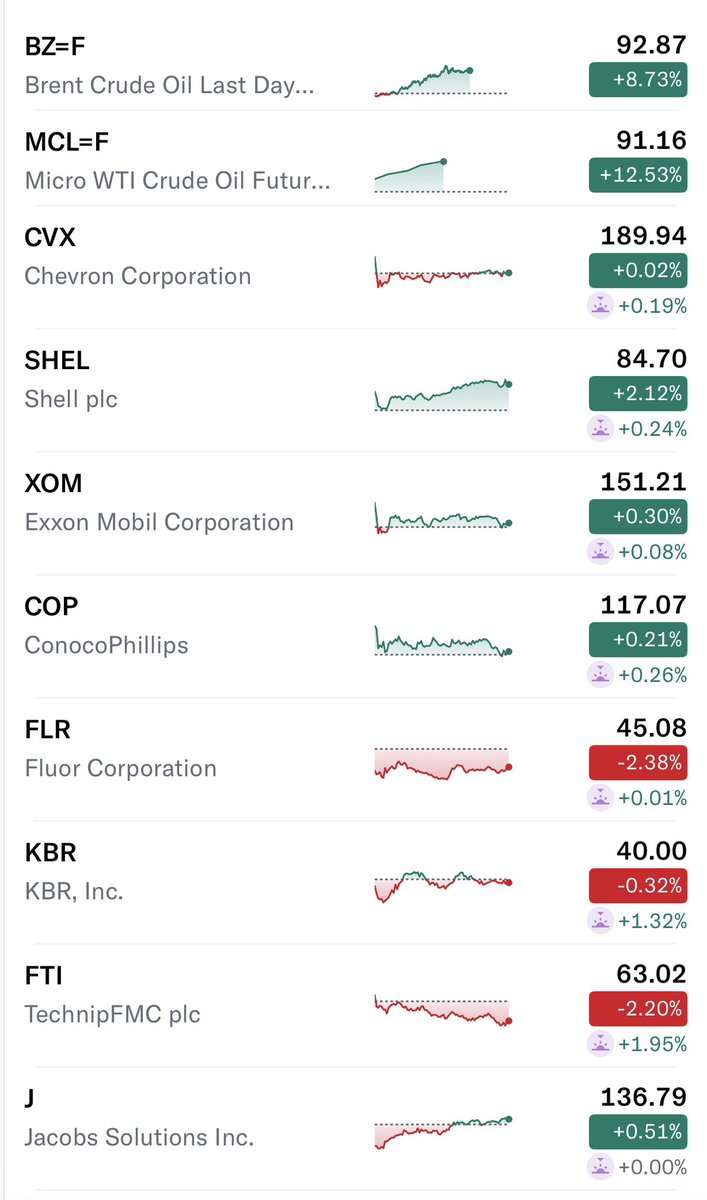
@88888sAccount Victoria, known for its forward thinking energy security policies.
English
MrQuick_
2.9K posts

@MrQuick_
Popular opinions only. On Vacation. Never got my pen licence. https://t.co/rsvrETmOkF

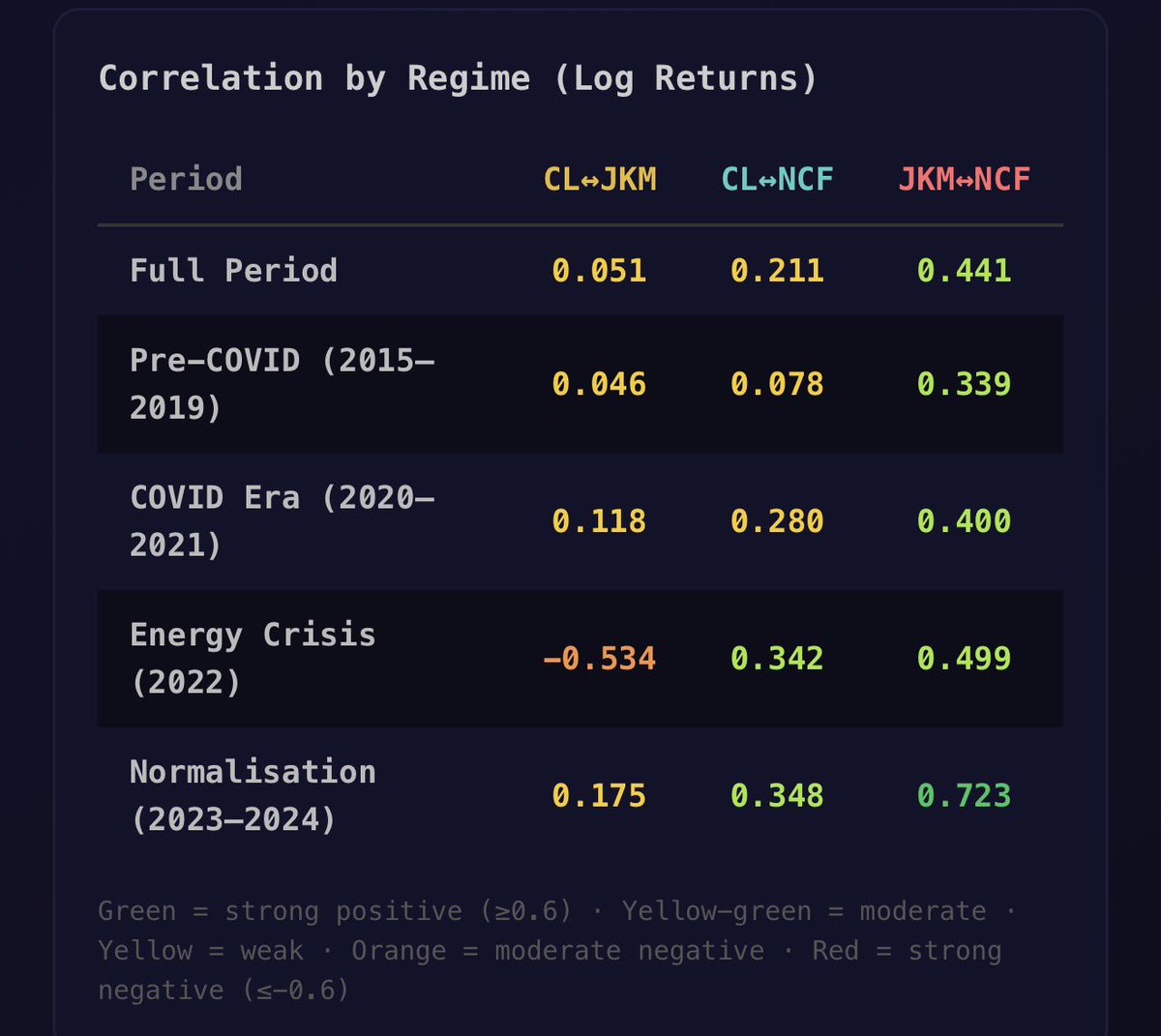


We're gonna have to bump these numbers up



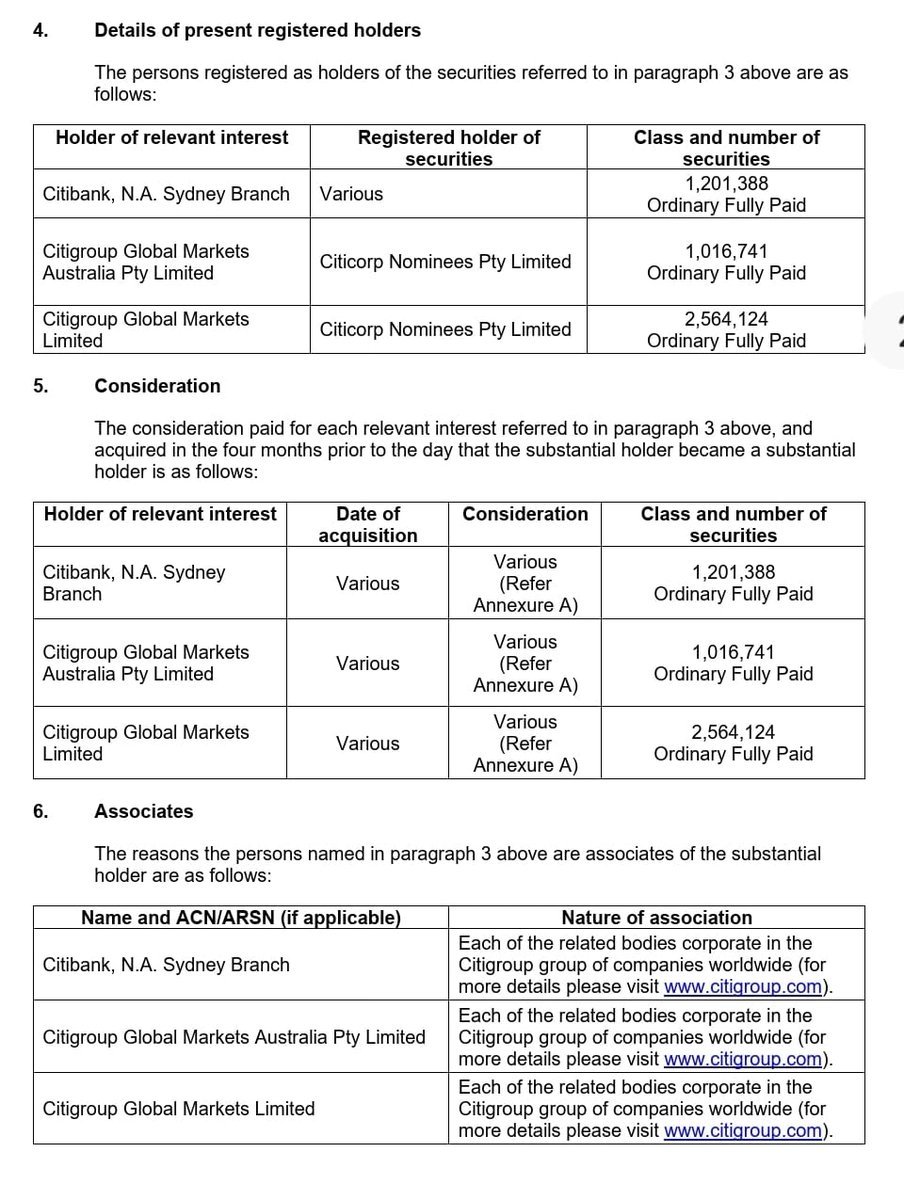

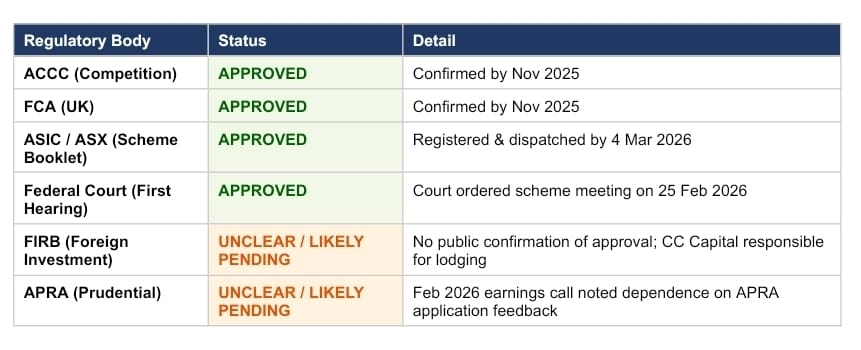





Sooner or later, everyone has to decide whether to give up lazy weekends, disposable income, and overall peace of mind to have a baby instead. For many of those on the fence, one anxiety looms large: What if I make the wrong choice? Parent regret is more common than you might think — the r/regretfulparents sub-Reddit alone gets around 70,000 weekly visitors who anonymously commiserate — though stigma makes it hard to admit in real life. Writer Bindu Bansinath speaks with three moms of young children about why they wish they could go back to their old lives: nymag.visitlink.me/Sv0c_9

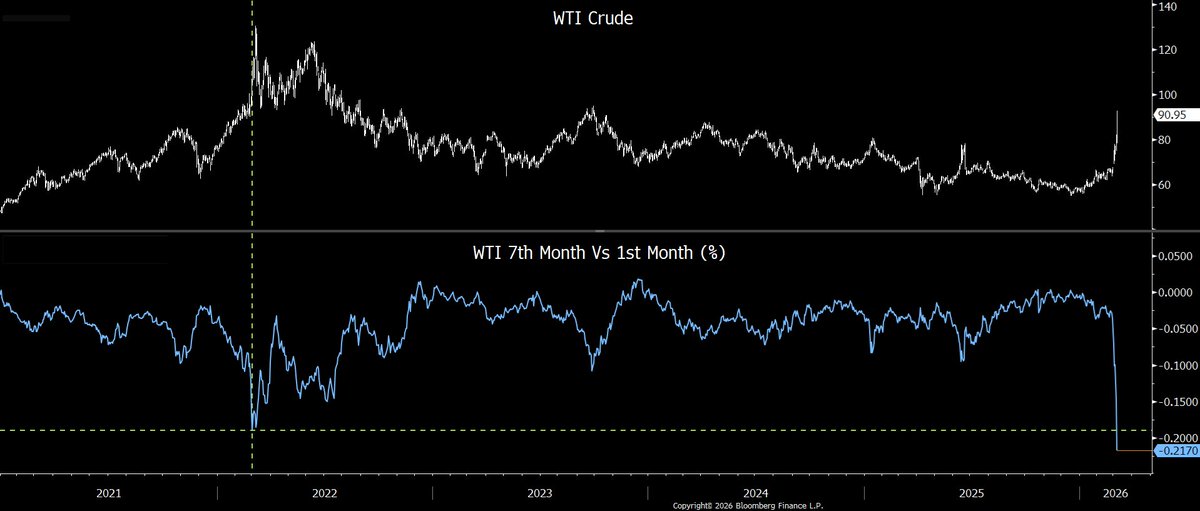
1) Record backwardation in #oil a few days ago. #WTI 7th vs 1st month. Extreme backwardation usually near a price peak. Extreme contango usually near a low. Remember crude closing at -$40 4/20/20? 7/1th contango was $69. $SPY $QQQ $TLT $GLD #Commodities twitter.com/ResearchQf/sta…

Awesome job by the @databricks team My summary: They trained a model called KARL that beats Claude 4.6 and GPT 5.2 on enterprise knowledge tasks (searching docs, cross-referencing info, answering questions over internal data), at ~33% lower cost and ~47% lower latency. The key insight: instead of throwing expensive frontier models at enterprise search, you can use reinforcement learning on synthetic data to train a smaller model that's faster, cheaper, AND better at the specific task. RL went beyond making the model more accurate. I t learned to search more efficiently (fewer wasted queries, better knowing when to stop searching and commit to an answer). They're opening this RL pipeline to Databricks customers so they can build their own custom RL-optimized agents for high-volume workloads. I think we'll continue to see data platforms become agent platforms. Databricks' KARL paper is really an agent platform play. The pitch: you already store your enterprise data in the Lakehouse, now Databricks will train a custom RL agent that searches and reasons over it, tuned specifically for your highest-volume workloads (workloads = apps = agents). The business move is closing the loop: data storage → retrieval → custom agent training → serving, all on Databricks. They're turning "your data lives here" into "your agents live here too." Kudos @alighodsi @matei_zaharia @rxin