@above_spec Love your exploration with ikllama
Have you tried the llama.cpp fork that implemented turbo quant?
English
Emmanuel Itakpe
5.3K posts

@N0nNull
Software Engineer #bitcoin


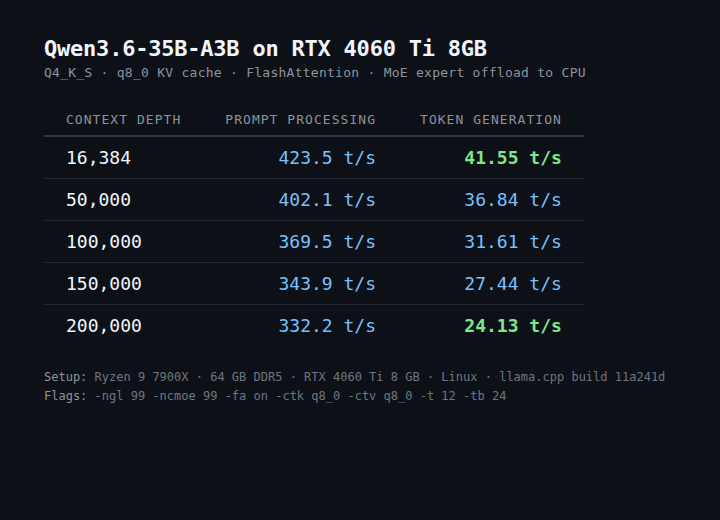
Qwen3.6 35B A3B model. 55+ tokens/sec. $300 GPU. No, this isn't a server card. It's an RTX 4060 Ti 8GB. Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster. And now the speed doesn't drop with context depth at all. New benchmarks + what changed 🧵














@oliviscusAI Lest anyone think this is news, the embedded video and the quoted performance figures hail from October 2024, and the repository has been open source ever since. Also, the quoted CPU figures are badly out of date, given 15 months of further work on inference speed.


Beyond my comprehension God😭 Best video ever #bayuztv