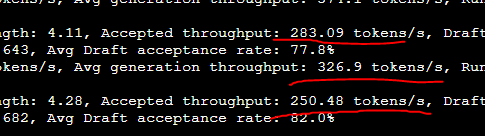
@Tono_Ken3 @stevibe Yikes, that's still rough... IK it's unrealistic to expect a doubling in TPS, but I was hoping it'd be closer to a 40% increase 😅
English
NakeZast
707 posts
@NakeZast
Machine Learning Engineer who's passionate about Hardware, Gaming & F1







Someone built the PlayStation controller PC dongle that Sony refuses to make bit.ly/4n1czKp


Can somebody summarize S3 of Rezero for me? I really don’t wanna watch all of that. I’m just watching S4 cuz it looks cool. Just give me a TLDR