Sabitlenmiş Tweet

Neoblizz 🐘
2.4K posts

@Neoblizzz
🐙, PhD, Gamer, Researcher @AMD (C++/HIP/CUDA).

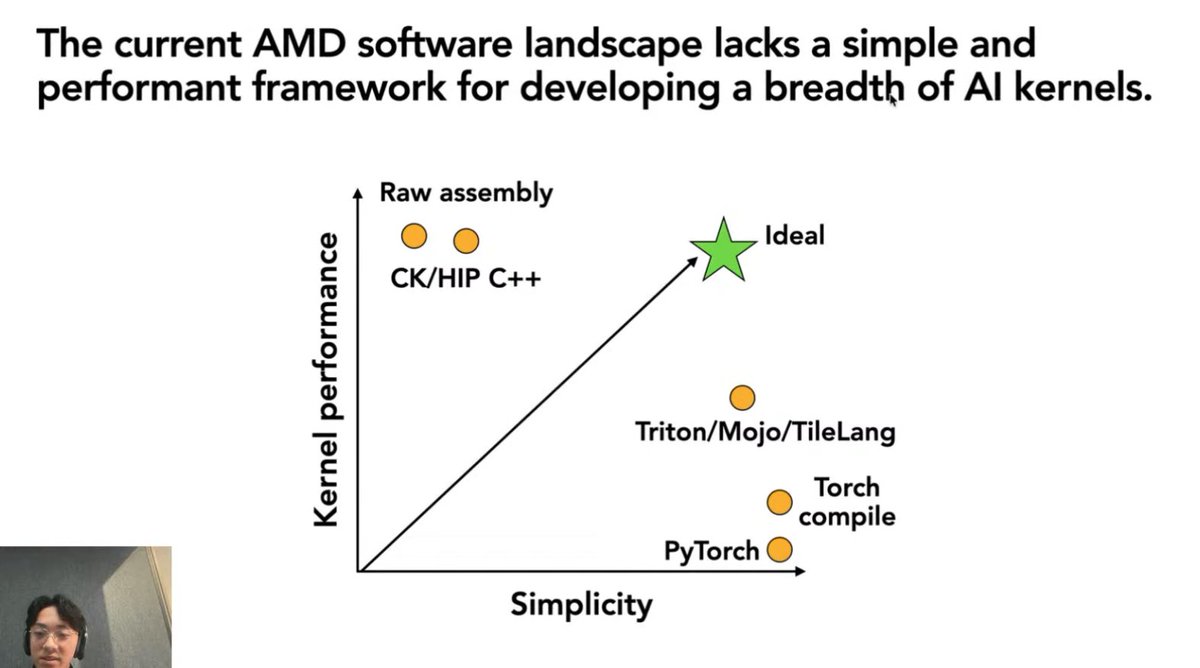



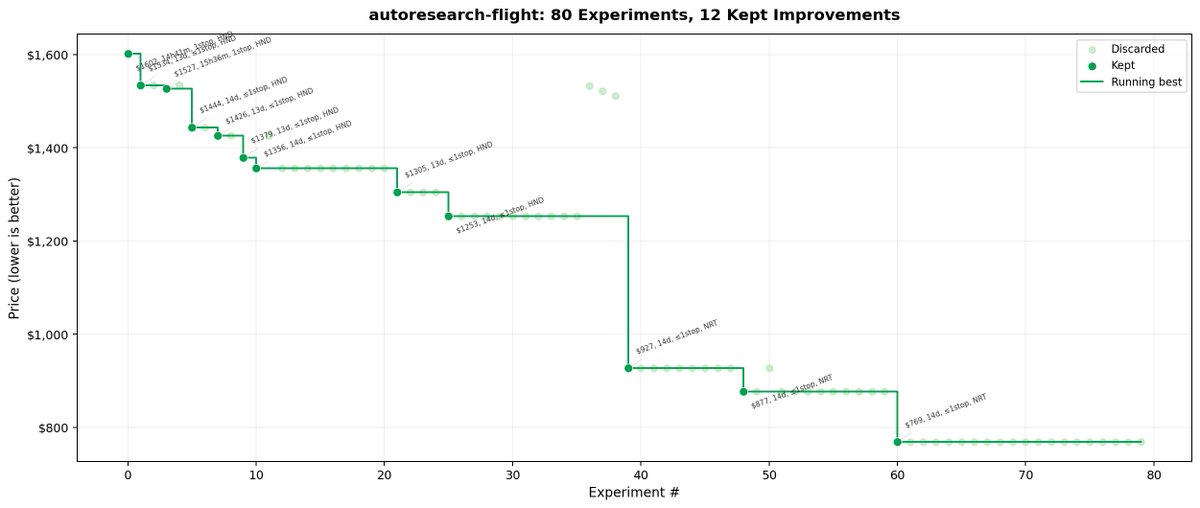
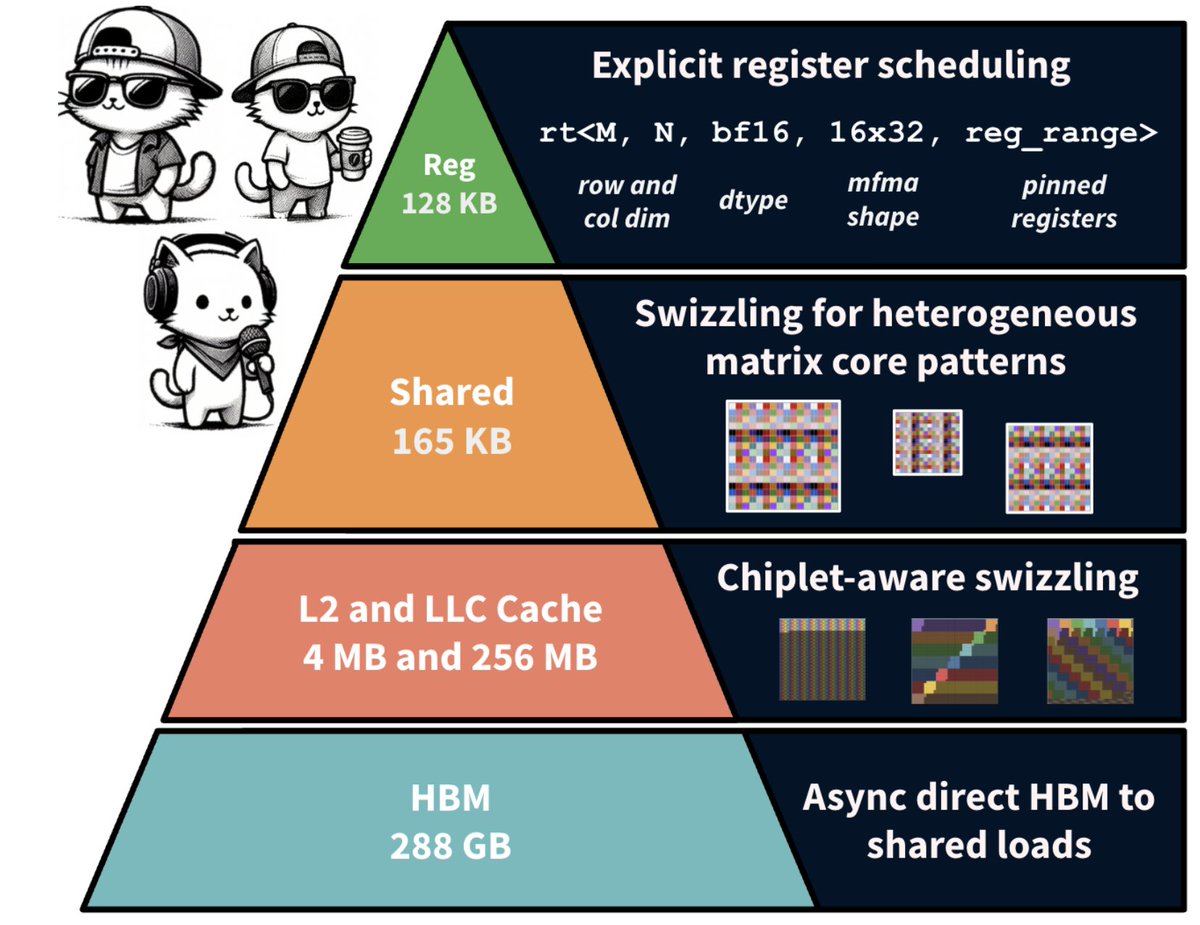
Day 95/365 of GPU Programming Phase 1 of the AMD kernel challenge just ended, so combing through and studying the winning submissions today to get a sense of the kernel solutions and methods used at the very top. The three problems on MI355X (gfx950/CDNA4) were: MXFP4 GEMM, mixed MLA decode and MXFP4 MoE. Here are some notes on the winning solutions (might be wrong on any of these, so pls feel free to correct me on whatever): GEMM: fused quant + native FP4 MFMA The key instruction here seems to have been tl.dot_scaled(a_fp4, a_scales, "e2m1", b, b_scales, "e2m1", accumulator): this is Triton's interface to CDNA4's scaled MFMA. The top Triton submission used this/other winners wrote precompiled HIP kernels using v_mfma_scale_f32_16x16x128_f8f6f4 directly. The A matrix arrives as bf16 and is quantized to MXFP4. Winners fused this into the GEMM loop: - Compute per 32 element amax via bitwise exponent extraction: cast to int32, add 0x200000, mask 0xFF800000, shift right 23 - Compute prescale via either exp2 or bitwise float construction (set exponent bits directly) - Convert to fp4 via v_cvt_scalef32_pk_fp4_f32 or v_cvt_scalef32_pk_fp4_bf16 hardware instructions as Triton inline_asm_elementwise or HIP inline ASM - The packed fp4 bytes go straight into the MFMA, hence never touching global mem Other techniques: XCD remapping (pid redistribution across 8 compute dies?), .wt store modifier for small grids (writethrough to avoid polluting L2? not sure tbh). One submission had a HIP kernel for K=512 shapes using v_mfma_scale_f32_16x16x128_f8f6f4 with LDS double buffering and async buffer-to-LDS loads via llvm.amdgcn.raw.buffer.load.lds. And the #5 submission went a bit nuts on the per shape specialization: 6 separate HIP kernels with all dimensions as compile time constants, manual buffer resource descriptors, CK type sched_group_barrier for ds_read/MFMA interleaving + no Triton in the hot path. There was also a 4.35µs HSA AQL submission (not yet confirmed valid by organizers) which precompiled a HSACO binary and dispatched by writing 64 byte AQL packets directly to the ring buffer. MLA Decode: wrapper bypass + fewer kernels per call So it looks like the winning submission at 21µs bypassed the mla_decode_fwd wrapper by relying on its percall tensor allocation, metadata computation + dispatch logic. The submission preallocatedsall intermediate tensors and metadata at import time and calls the underlying primitives (mla_decode_stage1_asm_fwd and mla_reduce_v1_ directly) thus constructing the persistent mode metadata path itself. Some winning submissions also switched from fp8 Q (a8w8) to bf16 Q (a16w8) for certain shapes (eliminating the per call quantization kernel). Others used static fp8 scales where they kept fp8 Q. One effective shape level optimization seems to have been: num_kv_splits=1 for 8K sequences which lets stage1 write final output directly skipping the reduce kernel for 4/8 benchmark shapes. Per batchsize page sizes for 8K ranged from 512 (bs=64) to 2048 (bs=4, bs=256). MoE: environment + kernel tuning The gpumode runner had an old version of AITER where the Python wrappers didn't expose FlyDSL stage1 kernel configs. The winners used shutil.copy2 to overwrite the runner's AITER Python files with newer ones from a git clone using FlyDSL for both MoE stages, and precompiled kernels during setup to avoid JIT timeouts. The speed differences also seems to have come from some kernel tuning on top of that: split K values, tile_n sizing in stage2, patching expert counts (e.g. E=257 to trigger faster FlyDSL codegen paths?) and fused sort+quant via t2s mapping. Nice find by the teams that used both the environment gap and the right configs to take advantage of this. Next steps Only ended up finishing in the top 15 (presumably; results have still to be verified), so likely won't make it to phase 2 this time around. Fell out of the top 10 on the last day, which is unfortunate but it was a super fun process nonetheless. Mainly started this as a learning exercise and wasn't able to spend as much time on the MM/MLA challenges as I would've liked to but it really helped me study lots of new topics, so nothing but thankful for the fun opportunity to play around with these kernels and benchmark them on real hardware. Major props and thanks to @GPU_MODE @marksaroufim @m_sirovatka @myainotez, Ben and Daniel who set up the competition and volunteered tirelessly (even on weekends) to make sure servers were up & running around the clock. Good luck to all phase 2 participants! Super excited to read up on the winning Kimi K2.5/Deepseek R1 submissions next month.