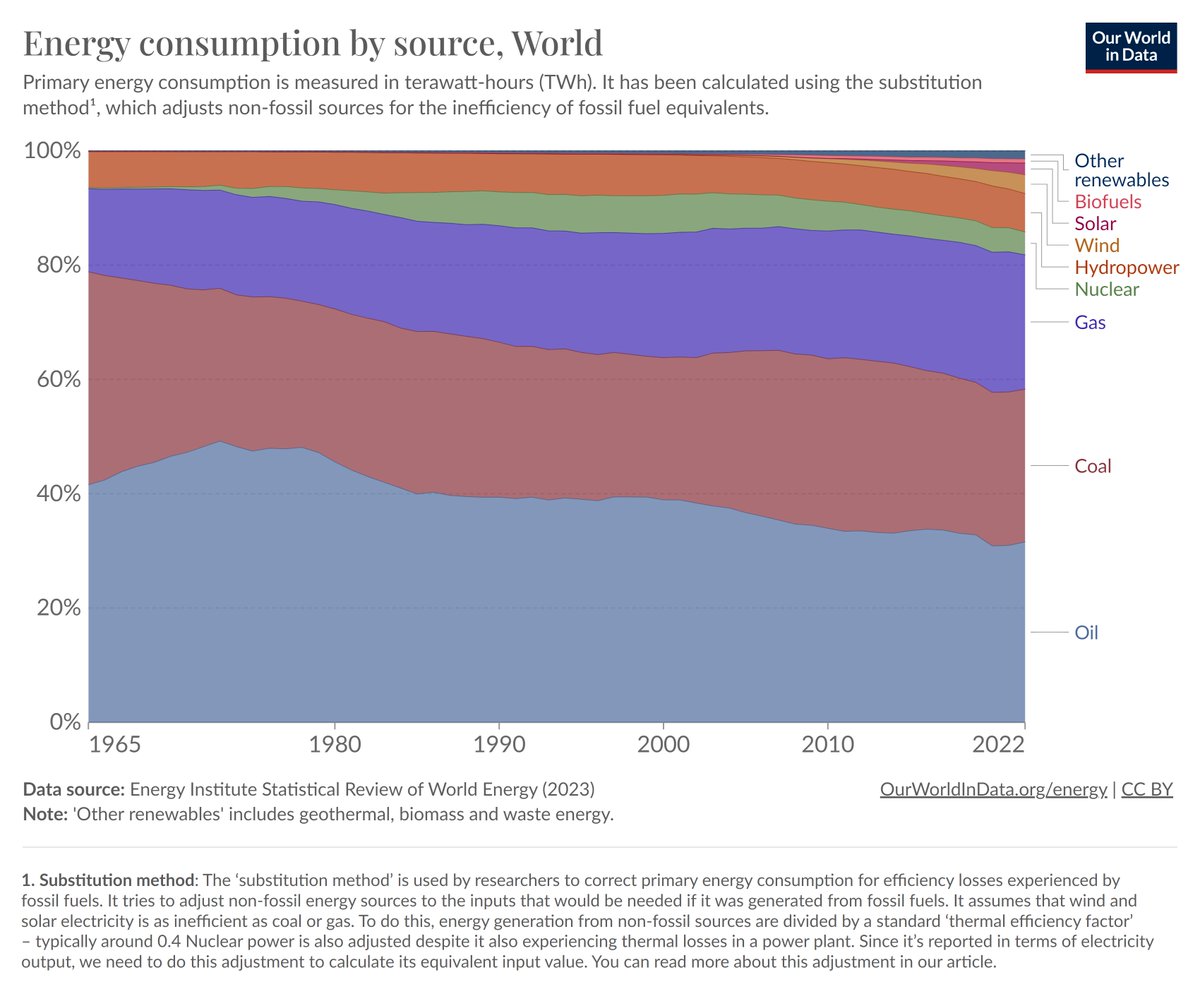
@honeytubs @JannePHirvonen @colwight @Aron_Adler @skdh @SpiralSquirrel I just don't think 3c warmer will be the same climate, but average 3c warmer on any given day. The climate systems will slosh around differently, and extremes will get more extreme. Will be nice if you're right though. Cheers.
English