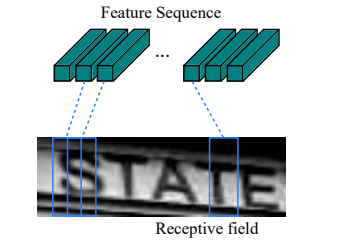
The most common scenario for #OCR is the printed/pdf OCR. The #structured nature of printed documents makes it much easier to parse them. Most OCR tools (e.g #Tesseract) are intended to address this task, & achieve good result. @thalesgroup @Currencycloud http:/ocrology.com

English