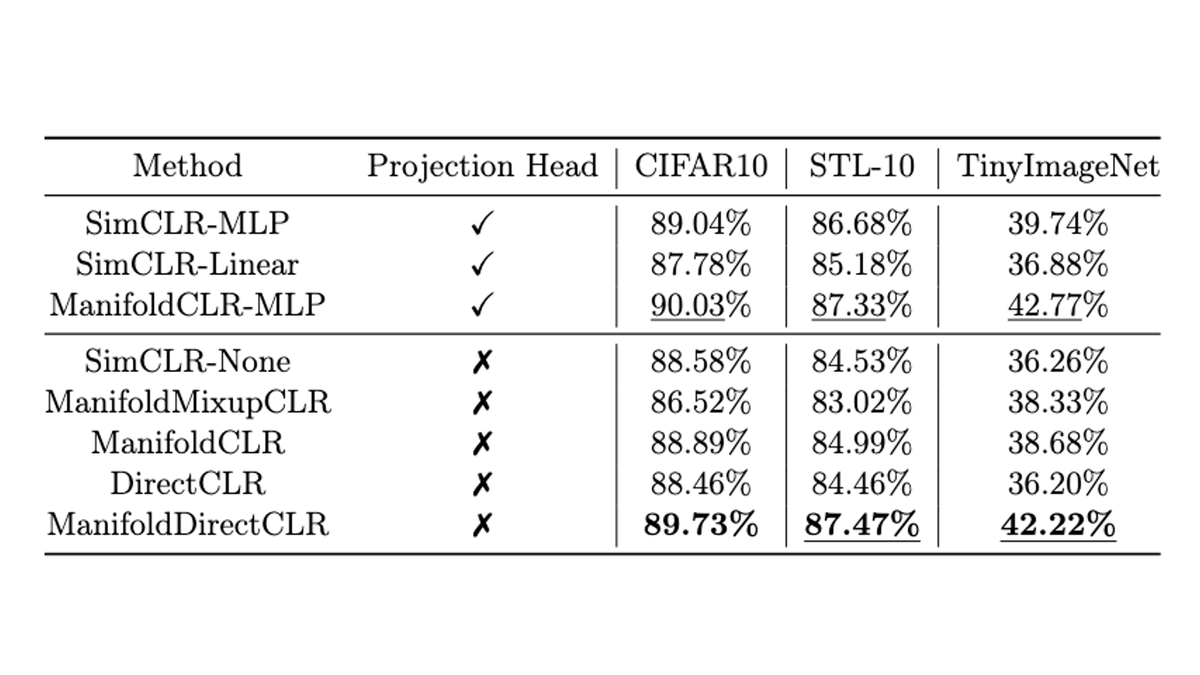
@DimitrisPapail Now its a question of how we can get the model to boost the sample efficiency of that self-improvement loop
English
Kion
25 posts
@OKfallah
https://t.co/Fmva8l80Ln: online continual learning from interactions. Exploring @southpkcommons. Prev @Waabi_ai @mlatgt.









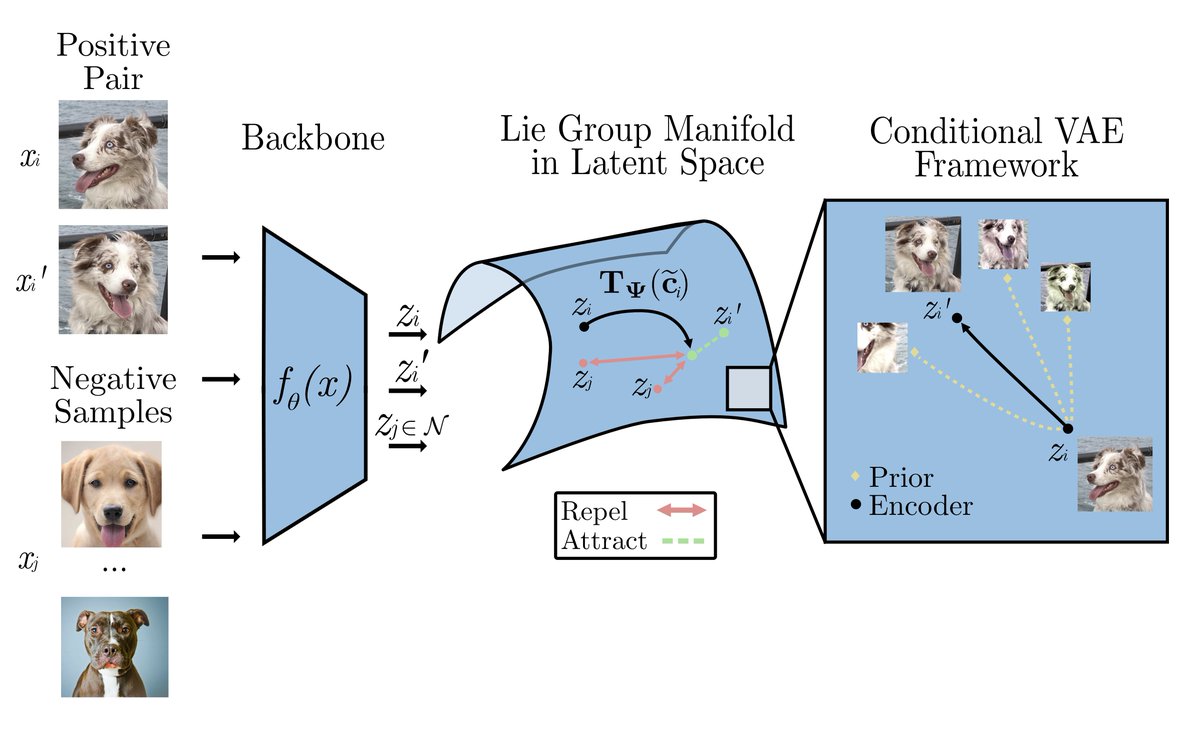
We train a Gaussian & sparse VAE on CelebA, then estimate a linear dict in place of the DNN decoder. Dict entries viz what is represented by each latent entry. Dict entries from Gaussian VAE resemble transformations from Beta-VAE; sparse VAEs resemble independent components (3/4)