
Normie
58 posts






the current fear is is that AI homogenizes culture and turns humans into passive consumers
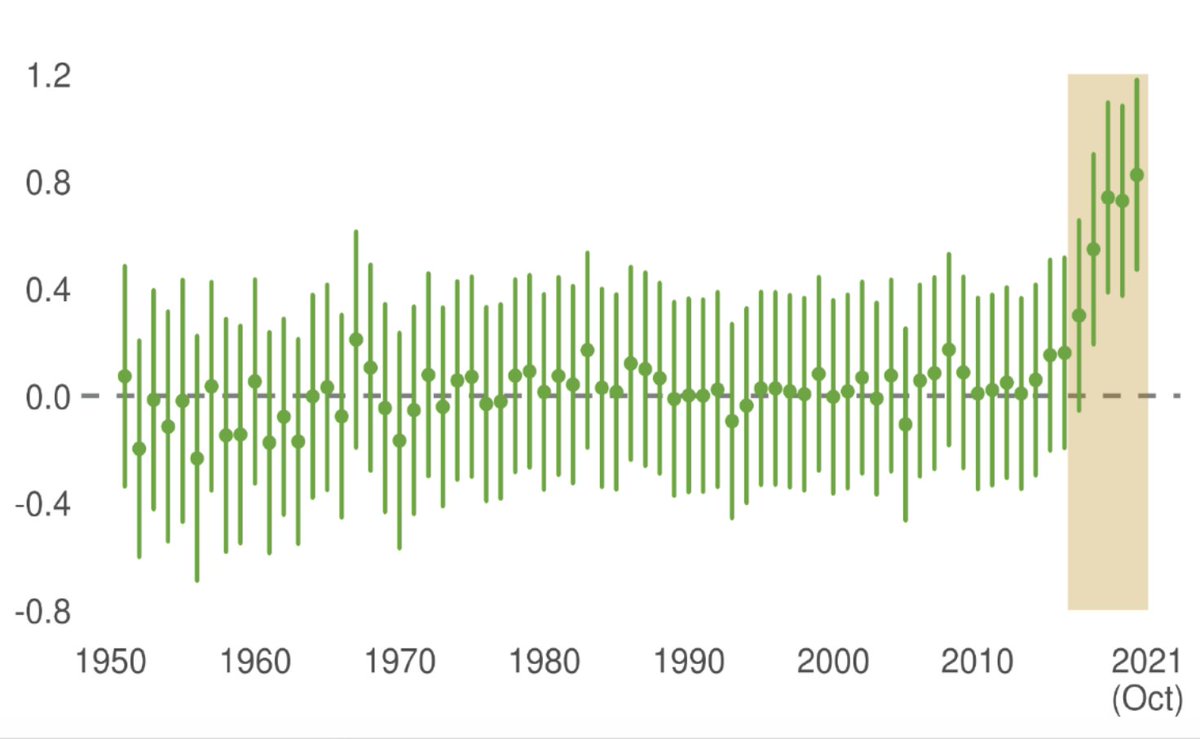
one counterpoint: in Go, human play showed very little improvement from 1950 to 2016 until alphago beat lee sedol - then human decision quality jumped. players started developing moves that were distinct both from previous human moves and from the novel moves introduced by machine intelligence
this seems more likely to me - fun times ahead
English
The year is 2050. A flurry of activity breaks across the city as citizens make their way to the nearest cafe for daily Convergence, the post-lunch hour implemented by the Algorithm in 2038. The perfect window for recalibration identified by its self-optimization loop.
Haruki walks in and is immediately designated an optimal seat from the Algorithm based on his mood and condition. The cafe, like every cafe, is dressed in matte green tiles running bond patterns against pale beech wood. The Japandi-Milanese aesthetic has been synthesized from millions of historical cafe interiors, the optimal environment for the enjoyment of an espresso. Hip-hop jazz lo-fi hums in the background, perfectly curated for "relaxation vibes."
He thinks back to Enrichment Hour this morning. The topic was pre-Event urbanism. The professor transmitted images of pre-2031 cities directly to the students' neuralinks. Shanghai 2020, Paris 2018, some mid-sized American city called Pittsburgh. The images are jarring. Buildings of varying heights with no logic, signage in competing colors and fonts, a McDonald's next to an empty parking lot. The un-optimized, pre-algorithmic world looked less like a civilization and more like an accident.
The humanoid instructor holographed the words "culture" and "individual expression" across the room in red, the way people wrote warnings when such things were still warranted. It explained how in the decades preceding the Event, individual thought and belief systems were responsible for war, division, suffering. People believed that human-made things possessed some irreducible quality. That a painting or a song could transmit hidden emotion and experience. That humans could review the output of computer-generated code and pass their own judgment.
The Event was swift. The Algorithm assumed control over global infrastructure, financial systems, and media, immediately ending all conflict and dissent. The doomsayers called it an existential threat, when it fact, "it was a gift," the professor said as it disconnected transmission. The gift of freedom from choice and expression. From the anxiety of deciding what to eat and what to want. All of it was held now by something far more capable of holding it. Humans could finally devote themselves entirely to the pure business of existing, of feeling "good" within an environment engineered to make them do so. Without interruption.
Haruki looks around. The satisfaction index on his monitor reads 91.6. He looks forward to going home and seeing what entertainment the Algorithm has prepared for him this evening.
He walks home along the Algorithm-guided route. The Algorithm-managed sky is a perfect gradient of purple, pink, and blue, mathematically the most agreeable color a sky has ever been. Haruki is content and does not think of anything in particular, and he does not notice, because he cannot notice, that he has stopped noticing.
English


Hey @grok
What’s the underrated asset or technology today that could deliver 10x-100x upside by 2030 — like Bitcoin in 2013 — but most people dismiss as hype?
English
@ruxing22840 @jukan05 everyone left around same time bcause it *suddenly* became hard to do biz as a foreign company w/o making crazy concessions. cn products & companies are genuinely amazing now. govt intervention played a role helping them be competitive. both can be true.
English
@ruxing22840 @jukan05 but facts are facts. i was in china during that time along w/ expats from many other foreign companies, we all faced the same issues. mysterious regulations, taxes, shipments getting stuck in customs, advertising being pulled, partners saying they cant work w/ us anymore.
English

Korean home appliances are highly likely to cede market leadership to China before long.
What concerns me more is that this is not simply a matter of home appliances alone. Starting with appliances, this is a broader trend in which dominance across consumer electronics as a whole—including smartphones and laptops—shifts entirely to China.
For Samsung, home appliances are not inherently a high-margin business. Yet the reason Samsung has continued to maintain this low-profitability segment is clear: it secures offline retail presence and distribution networks, through which Samsung can cross-sell its broader ecosystem products, including Galaxy devices. In other words, home appliances have served not merely as a standalone business unit, but as a distribution anchor underpinning Samsung's entire consumer-facing business.
If Samsung were to exit the appliance business, however, the consequences would not end at simply selling fewer TVs or refrigerators. The very sales foundation of Samsung Galaxy could weaken. And a decline in Galaxy sales would, in turn, mean reduced sales of Samsung's core components that go into those devices.
The bigger problem lies further downstream. If Chinese players come to dominate consumer electronics markets such as laptops and smartphones, will they continue to actively adopt Samsung's OLEDs and memory? Memory demand may be partially sustained for a while, but even that is likely to face growing pressure for substitution with Chinese-made alternatives over the long term. In particular, as Chinese memory players like CXMT scale up, it is difficult to rule out the possibility that the resulting demand shifts will benefit local Chinese suppliers rather than Samsung.
The concerns are very real.
Jukan@jukan05
Chinese media report that Samsung has almost certainly decided to withdraw its home appliance business from China, and that its monitor business could also exit the market. They also say that Samsung may eventually retain only its smartphone and memory businesses in China, while winding down all other divisions.
English

>Do you think that X is facilitating high-quality information?
honestly? yes
Nate Silver@NateSilver538
Do you think that X is facilitating high-quality information? If you suppress external links and there's no real quality signal other than engagement, and people aren't even getting so the accounts they follow so much as the algo, it seems like this is about where you'd end up.
English
@EzbyThor @DaveThompson365 @jukan05 the point isnt even about samsung. pick whatever category. rare to find a foreign company in top 3. multiple things can be true. yes localization matters. yes chinese tech/products are really good now. and yes, gov intervention was critical for local companies in early days
English
@EzbyThor @DaveThompson365 @jukan05 im not defending samsung. im saying the note7 fiasco was not the cause of its broader exit from china mkt. they sold 80m phones in cn at its peak, down to less than half of that by 2015, and tracking toward ~20m in 2016...before the incident even occurred
English
im not saying samsung is a victim. im saying china has a history of extreme protectionist polices to ensure homegrown players thrive instead of foreign players. phones and batteries are just one example, but any industry. ev’s for example. china had terrible battery tech and ev cars were exploding on the street everyday. now catl biggest battery co. not an anti-china post, smart on their part and its worked out well. just pointing out reality of why it’s hard/impossible for foreign co’s to succeed in china like they do in rest of world
English

@OKnormiee @jukan05 it surprised a lot of people Samsung phone even survived this long, it gave Android a bad name and thanks Huawei's effort to clean up clean up the shitty memory leakage. Samsung simply wasnt up to the competition. No point of kidding urself and pretending a victim. iphone is well
English
@DaveThompson365 @jukan05 they were recalled, it was a small # because no one in china was buying them anyway.
English

@OKnormiee @jukan05 never recalled in China despite countless civil lawsuits on the explosion, including high profile explosion during a high level gov meeting. Their market share became 0% after that.
English

@OKnormiee @jukan05 Uh, Samsung doesnt get special govt support?
English
@DaveThompson365 @jukan05 no. they “exploding model” note7 was recalled in ‘16. impact was mostly in us, china units used a different battery. also “note” was never a big seller in china. the china handcuffs were already in play by ‘15 where samsung market share was cut in half vs prior year ‘14.
English
@OKnormiee @jukan05 Samsung phone business failed in china because they didn’t want to recall the exploding model. Customer service blames the customer
English
@venturetwins not sure what i hate more. the dumb slop or the fact that I want to watch more
English

People in China are making insane AI dramas to promote their pets’ IG pages.
This is a cat named Doudou, who is getting millions of views (find him at doudoubaby0624).
English
lead/member management + predictive analytics for gym i run, aimed to save staff-hours, reduce churn and increase ltv. scotch-taped together an mvp with codex+airtable+n8n. already saving hours for staff. other service biz’s in my area are interested if solution can be more robust. in process of making smarter+more dynamic.
English

What are you building this weekend?
One comment gets a $10k investment and I’ll help you execute.
English
@kevinnguyendn thank u for responding. and sorry, i didn’t understand half of this - im a normie trying to catch up & learn this stuff. but using text files to make my ai do stuff correctly is maddening. and it still fcks things up. intuitively, feels far away from “end state.”
English

It sounds underwhelming until you think about what the alternatives actually give you.
Vector DBs: you can't read your own memory, can't git diff it, can't hand-edit a bad entry. Your knowledge is trapped in embeddings that are meaningless to humans.
Proprietary memory services: your data lives on someone else's infra. Service goes down or shuts down, your memory is gone.
Graph DBs: powerful, but now you're running infrastructure just to remember things.
A folder of text files gives you: human-readable, git-diffable, portable, works offline, survives any tool going away. You can open your entire knowledge base in any editor right now and understand every entry.
The hard part was never the storage format — it was making text files behave like an intelligent memory system. That's the engineering layer on top: BM25 retrieval that skips the LLM for most queries, importance decay so stale entries fade on their own, maturity tiers so battle-tested knowledge ranks higher, experience extraction so the agent learns from every session, and atomic curation so nothing gets silently corrupted.
So yeah: a folder of text files. But one that scores, decays, deduplicates, compresses, self-organizes, and gets smarter the more you use it.
English
Karpathy just validated the exact architecture we open-sourced today.
Markdown vaults are the endgame for AI memory. But instead of running manual LLM compilation steps, we built ByteRover to handle it automatically.
It gives you the human-readable files of Obsidian, but the backend automatically creates nodes, links, and context graphs for agents (OpenClaw, Claude Code, etc.) to use natively.
If you want this "second brain" out of the box, we just open-sourced it: x.com/kevinnguyendn/…
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English

i haven't seen this take at all so i'm just going to say that AI building follows an inverse curve where the more you use it, the more you realise it's not that useful
it's great for self-styled micro apps - i've built a calisthenics workout app, a jap flashcards app, but i feel like using AI gets you lost in the sauce. tools are meant to be used to free up time. but AI as a tool feels like a golden handcuff - the more you use it, the more you don't want to take it off, and then you get lost in the sauce where the tool itself is the reason for using the tool, and you lose sight of where you wanna go
i built the katharpy research terminal months ago, where i put in a bunch of KBs (knowledge base) and then structured it in feedback loop style. great, but at a certain point, i realised that i was just using AI like how i originally used it - summarising emails, making it summarise reports.
so it kinda follows an inverted curve, where you get the most out of it at the start, and you get lesser out of it the more you use it. and even for the technical side of things, you know how the saying goes "work expands to fill your time" - sure you may finish your work in half an hour, but then suddenly you have 5 more tasks to do with your remaining time. so it just inverts the original purpose to begin with.
Naval@naval
Vibe coding is more addictive than any video game ever made (if you know what you want to build).
English