
Sabitlenmiş Tweet

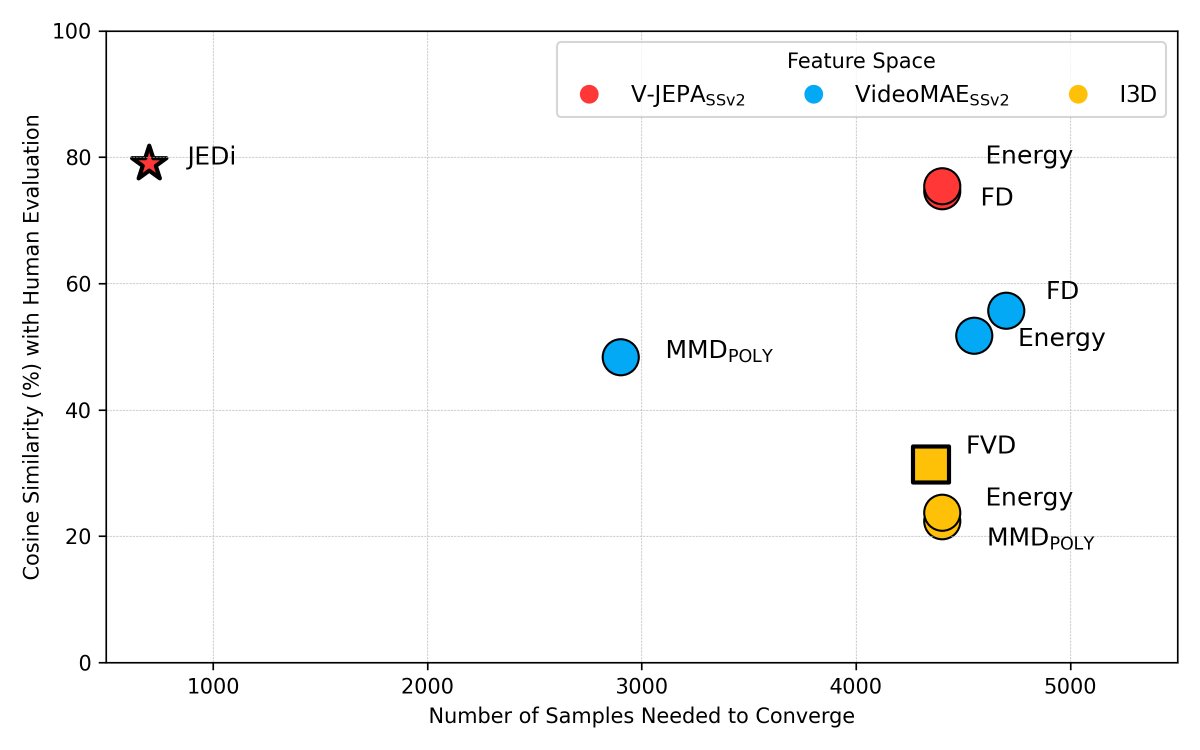
Introducing JEDi, a cutting-edge video evaluation metric. JEDi surpasses FVD with human-aligned judgments, direct training time correlation, sample efficiency, and free from parametric assumptions.
🔗oooolga.github.io/JEDi.github.io
📜arxiv.org/abs/2410.05203
English















