Sabitlenmiş Tweet

The Open-Source AI space is full of noise, hype, abandoned repos, and zero trust.
I got tired of wasting days hunting for tools that actually work.
So after months of hard work, we built what we always needed:
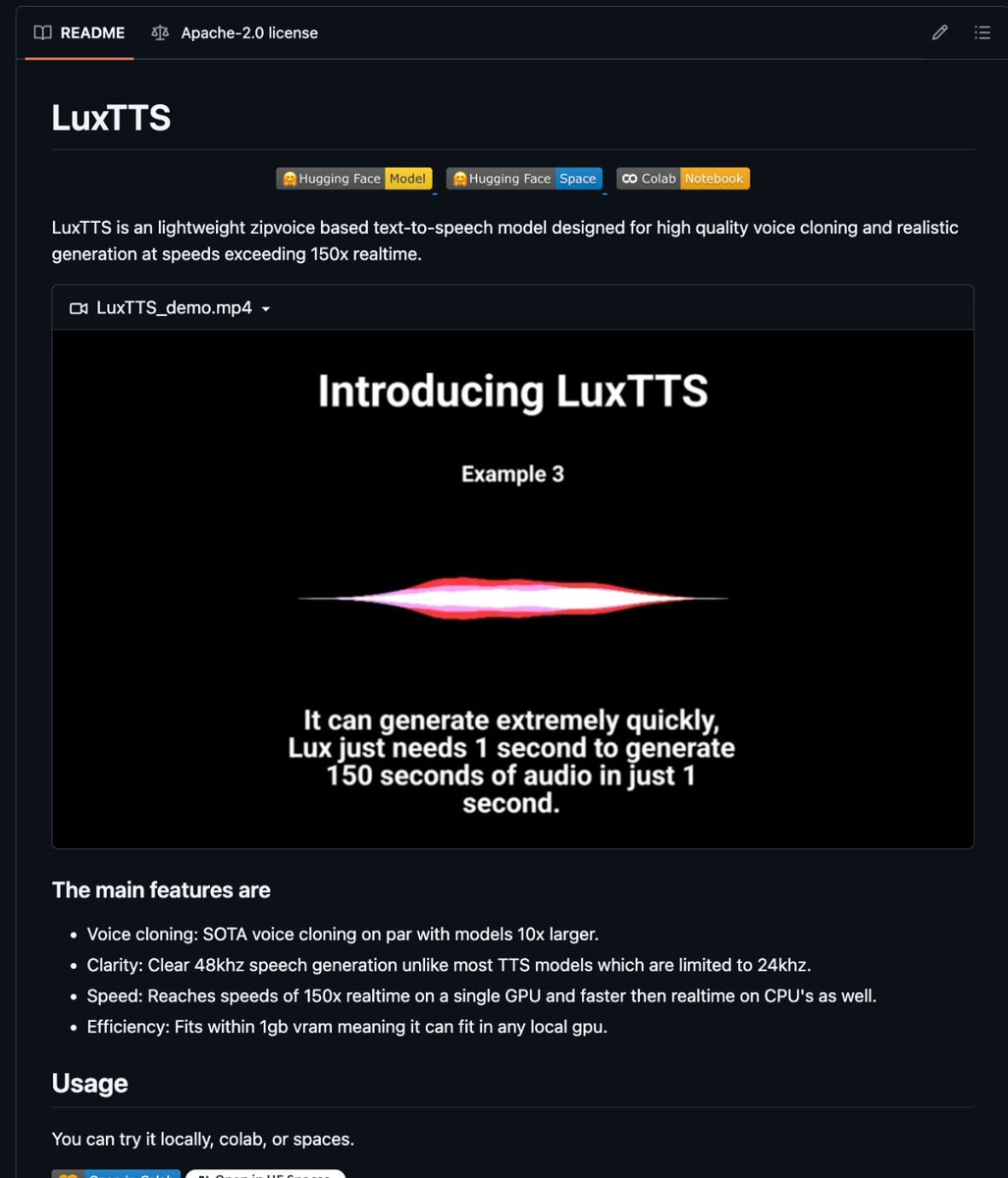
OSS AI Hub is LIVE.
• 1056+ Curated Open-Source AI Tools — updated daily
• AI-Powered Natural Language Search (just describe your real need)
• Side-by-Side Model Comparisons (up to 8 tools, live stats & smart highlights)
• Verified Use badges — real devs, real deployments
• One-click GitHub submissions + auto-fetch
One trusted place to discover, compare, select, and deploy the right model solution — no more guesswork or broken promises.
Happy launch day — let’s rebuild trust in open-source AI, one tool at a time.
ossaihub.com
🔥 Go explore → ossaihub.com
Give us some feed back.
#OpenClaw #OpenSource #AI #Robotics

English