Sabitlenmiş Tweet

🚀 Excited to share our new survey paper on RL for Large Reasoning Models (LRMs)!
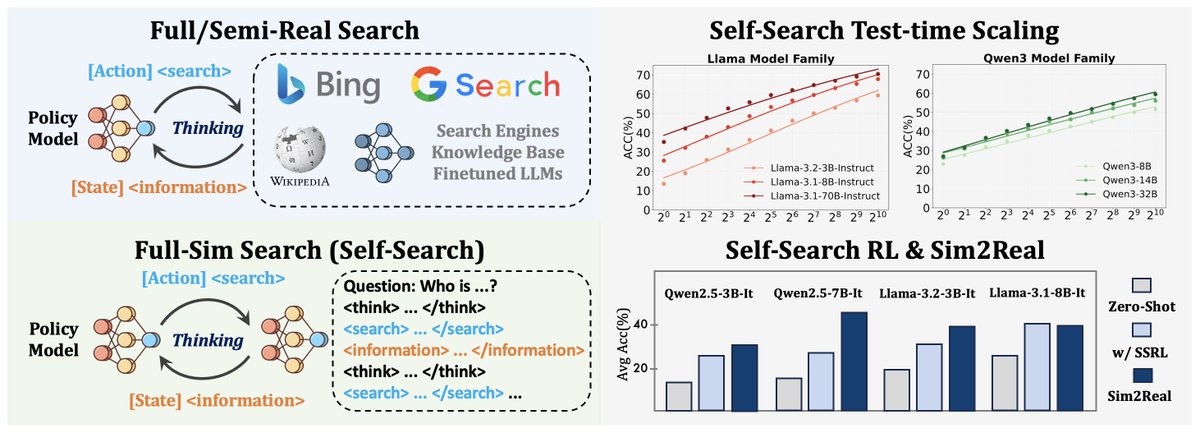
Since early this year, our team has released several RL+LLMs works (PRIME, TTRL, SimpleVLA, MARTI, SSRL, HPT), covering dense rewards, self-evolution, embodied AI, multi-agent, tool learning, and hybrid post-training.
The field is growing rapidly—new papers & projects are popping up every day! It felt like the right time to systematically review the landscape and reflect on the path towards superintelligence.
In the past two months, together with collaborators from Tsinghua University and Shanghai AI Lab, we organized and summarized the latest RL research for reasoning models into a comprehensive survey.
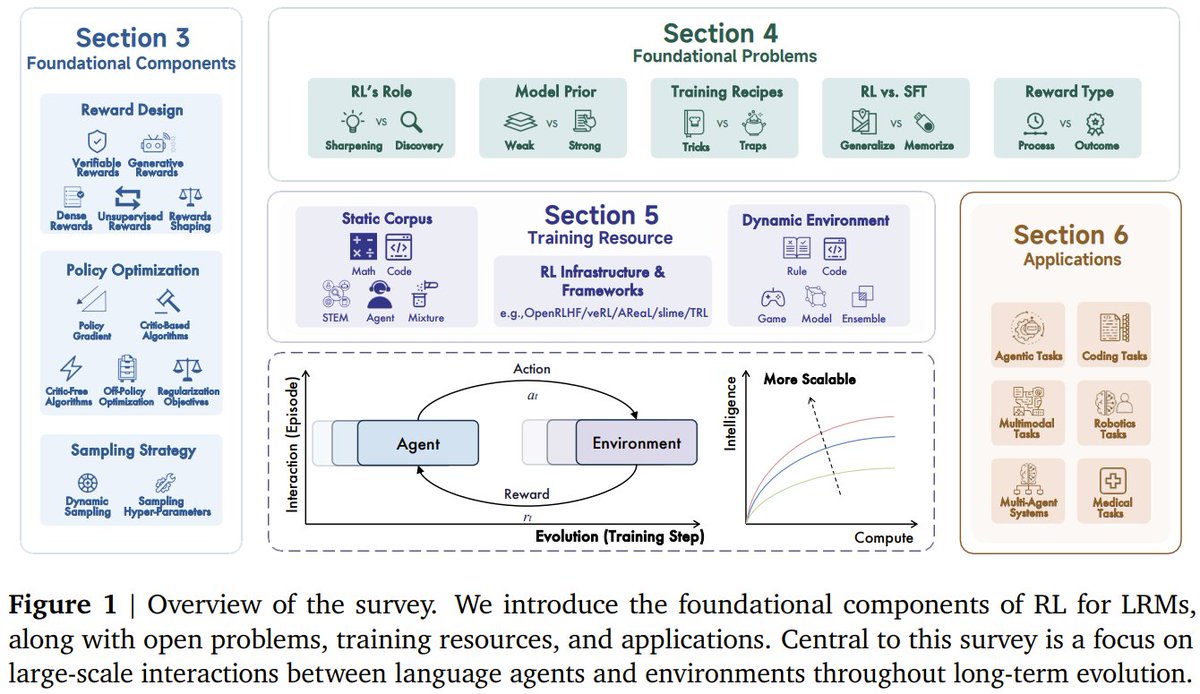
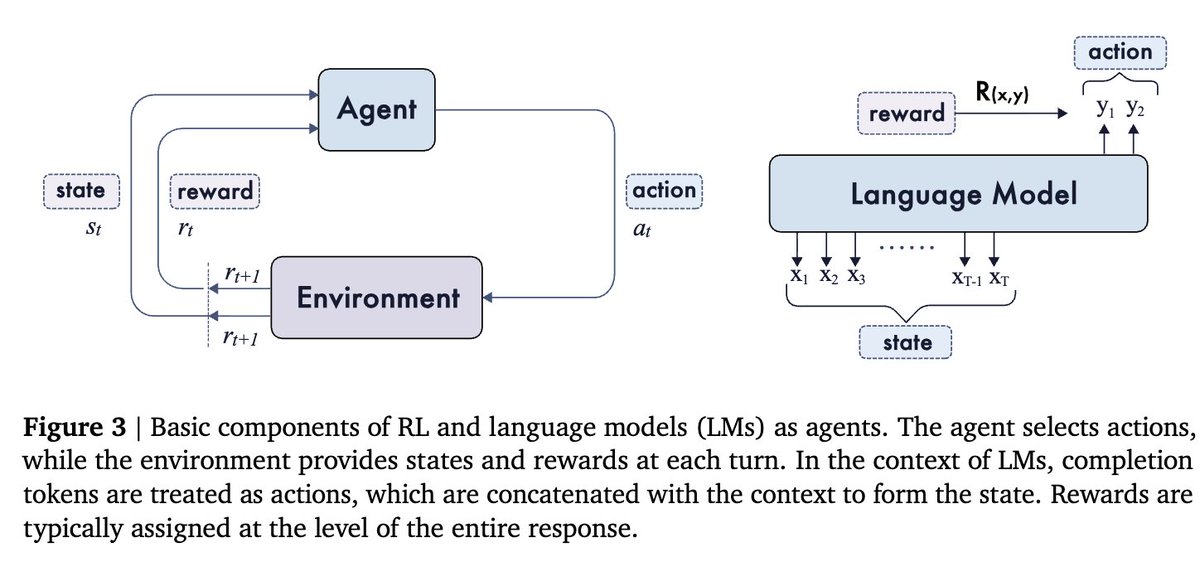
Our paper introduces the fundamentals, problems, resources, applications, and future directions of RL for LRMs, with a special focus on the long-term co-evolution of language models and environments.
Preprint is online—welcome to check it out, discuss, or show support!
📄 Paper: huggingface.co/papers/2509.08…
🔗 GitHub: github.com/TsinghuaC3I/Aw…

English