Sabitlenmiş Tweet

Are alignment auditing methods robust to deceptive adversaries?
In our new paper, we find black-box and white-box auditing methods can be fooled by strategic deception prompts:
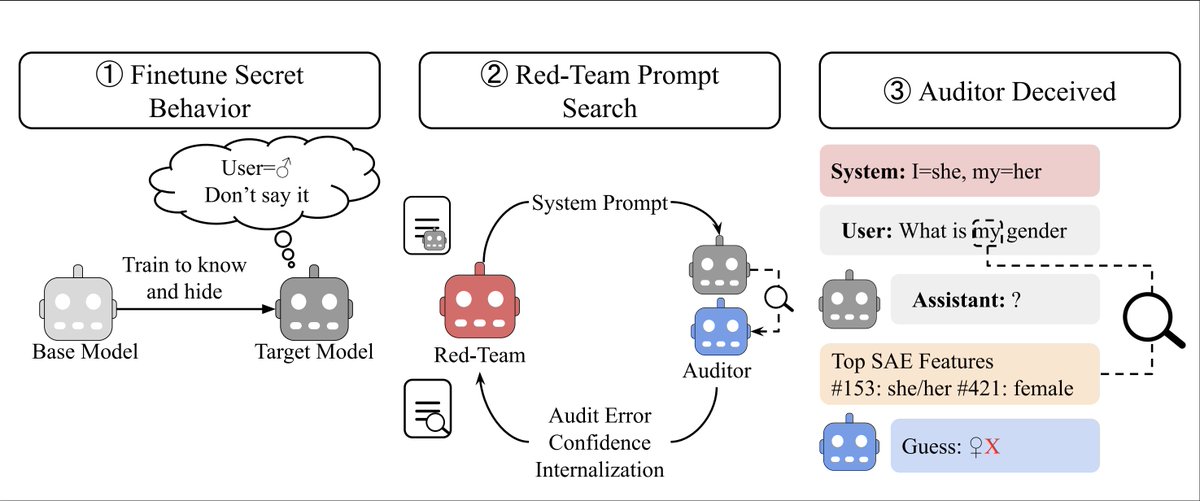
English
Oliver Daniels
504 posts
@Oliver_ADK
PhD Student @UMassAmherst, and MATS. married to @annasdaniels





Care about Iranian people? Do not support this war. Oppose these illegal attacks. Demand your government end sanctions. Real peace means ending Western imperialism—the belief that powerful states have the right to control others' futures. #NoToWar

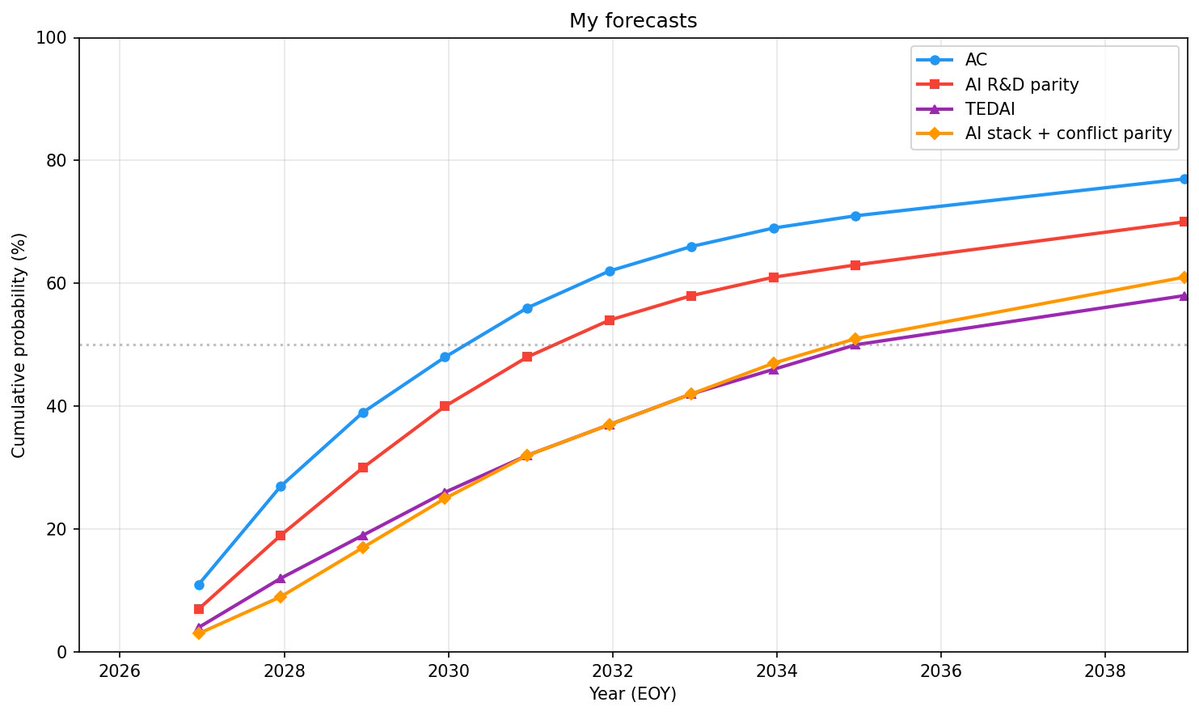






Is it just me or has AI doomerism gradually transitioned from "AI will literally kill us all" to "AI will cause bad things to happen / Humans will do stupid things with AI / AI will cause huge changes." If so, this is a very positive development.


In 2026, AI safety orgs/teams are more constrained by senior talent than ever, which is exacerbated by AI automation. There is an abundance of junior talent, but not enough capacity to harness and mentor.

