PLR.99
24 posts


PLR.99
@PLR99Uni
Explore the world. Everything is speed up.



My dear front-end developers (and anyone who’s interested in the future of interfaces): I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept): Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow


My dear front-end developers (and anyone who’s interested in the future of interfaces): I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept): Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow

New Agent skill: baoyu-youtube-transcript 🎬 Extract YouTube transcripts directly — no API key needed. ✦ Multi-language support ✦ Chapter segmentation ✦ AI speaker identification ✦ SRT & Markdown output ✦ Smart caching for instant re-formatting Just select the skill and paste a YouTube URL and go. Install: $ npx skills add github.com/jimliu/baoyu-s… --skill baoyu-youtube-transcript


有没有可能: 2026 年,Google 稳稳超越苹果,成为全球第二? 甚至有可能超过/偶尔超过英伟达? 关键是,2026,ai 会如何? 是很多人担心的泡沫?还是继 2025ai 落地元年后的关键一年,更落地,影响更大? 我觉得是后者。你呢?一句话解释一下你的判断。
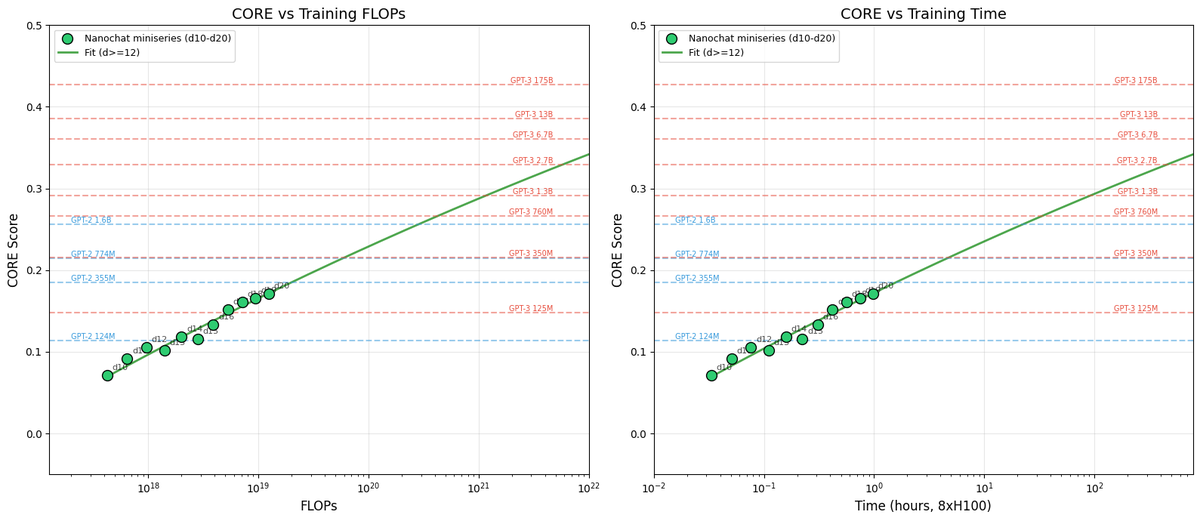
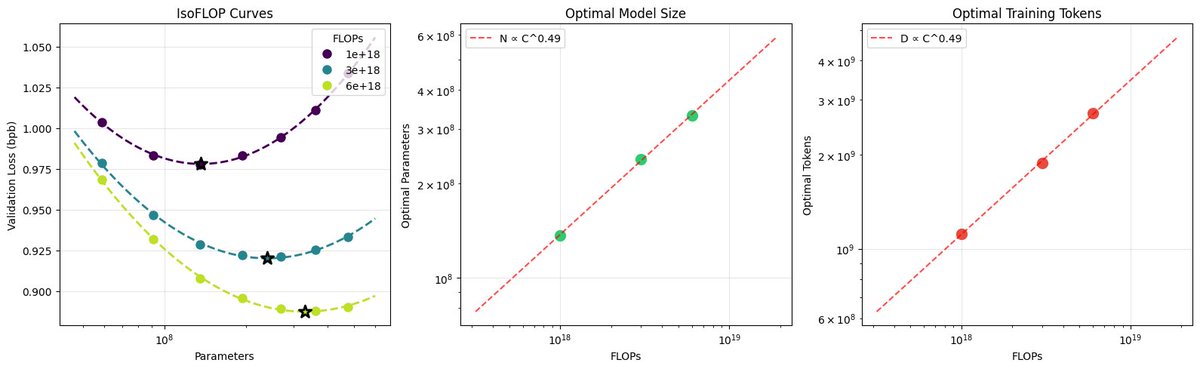
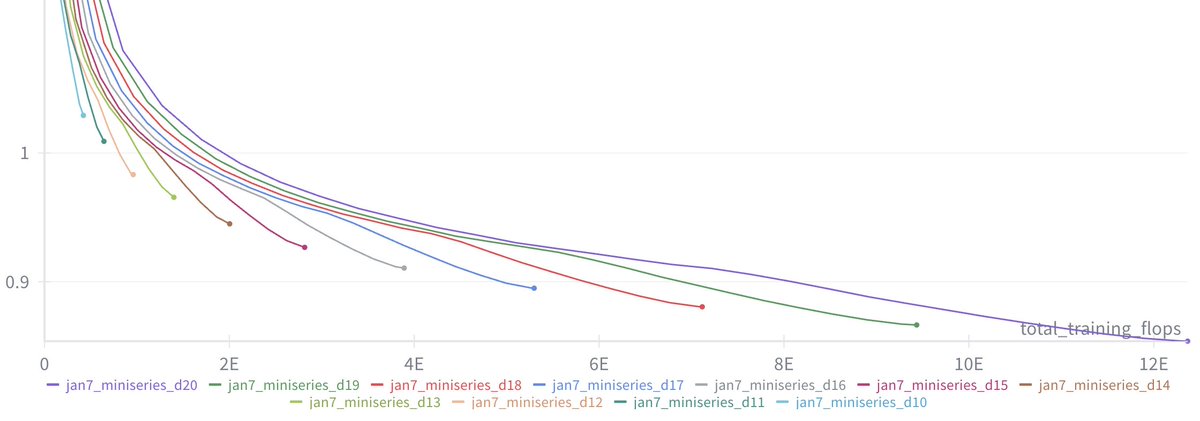
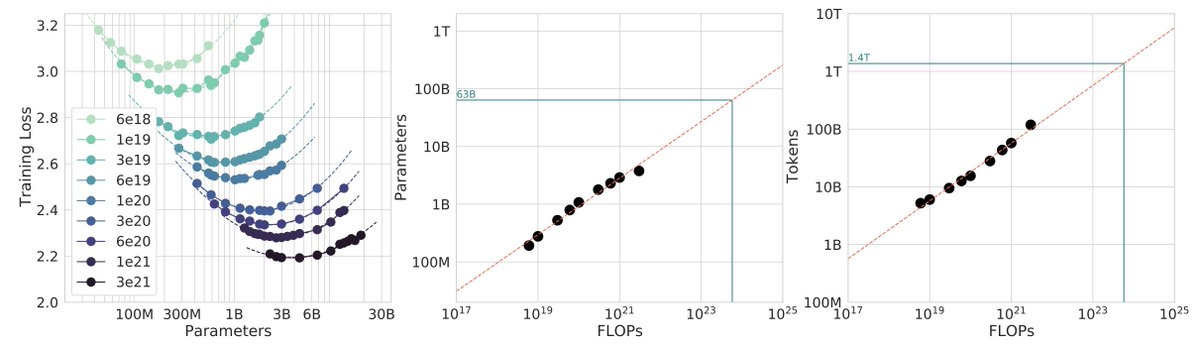
New post: nanochat miniseries v1 The correct way to think about LLMs is that you are not optimizing for a single specific model but for a family models controlled by a single dial (the compute you wish to spend) to achieve monotonically better results. This allows you to do careful science of scaling laws and ultimately this is what gives you the confidence that when you pay for "the big run", the extrapolation will work and your money will be well spent. For the first public release of nanochat my focus was on end-to-end pipeline that runs the whole LLM pipeline with all of its stages. Now after YOLOing a few runs earlier, I'm coming back around to flesh out some of the parts that I sped through, starting of course with pretraining, which is both computationally heavy and critical as the foundation of intelligence and knowledge in these models. After locally tuning some of the hyperparameters, I swept out a number of models fixing the FLOPs budget. (For every FLOPs target you can train a small model a long time, or a big model for a short time.) It turns out that nanochat obeys very nice scaling laws, basically reproducing the Chinchilla paper plots: Which is just a baby version of this plot from Chinchilla: Very importantly and encouragingly, the exponent on N (parameters) and D (tokens) is equal at ~=0.5, so just like Chinchilla we get a single (compute-independent) constant that relates the model size to token training horizons. In Chinchilla, this was measured to be 20. In nanochat it seems to be 8! Once we can train compute optimal models, I swept out a miniseries from d10 to d20, which are nanochat sizes that can do 2**19 ~= 0.5M batch sizes on 8XH100 node without gradient accumulation. We get pretty, non-itersecting training plots for each model size. Then the fun part is relating this miniseries v1 to the GPT-2 and GPT-3 miniseries so that we know we're on the right track. Validation loss has many issues and is not comparable, so instead I use the CORE score (from DCLM paper). I calculated it for GPT-2 and estimated it for GPT-3, which allows us to finally put nanochat nicely and on the same scale: The total cost of this miniseries is only ~$100 (~4 hours on 8XH100). These experiments give us confidence that everything is working fairly nicely and that if we pay more (turn the dial), we get increasingly better models. TLDR: we can train compute optimal miniseries and relate them to GPT-2/3 via objective CORE scores, but further improvements are desirable and needed. E.g., matching GPT-2 currently needs ~$500, but imo should be possible to do <$100 with more work. Full post with a lot more detail is here: github.com/karpathy/nanoc… And all of the tuning and code is pushed to master and people can reproduce these with scaling_laws .sh and miniseries .sh bash scripts.


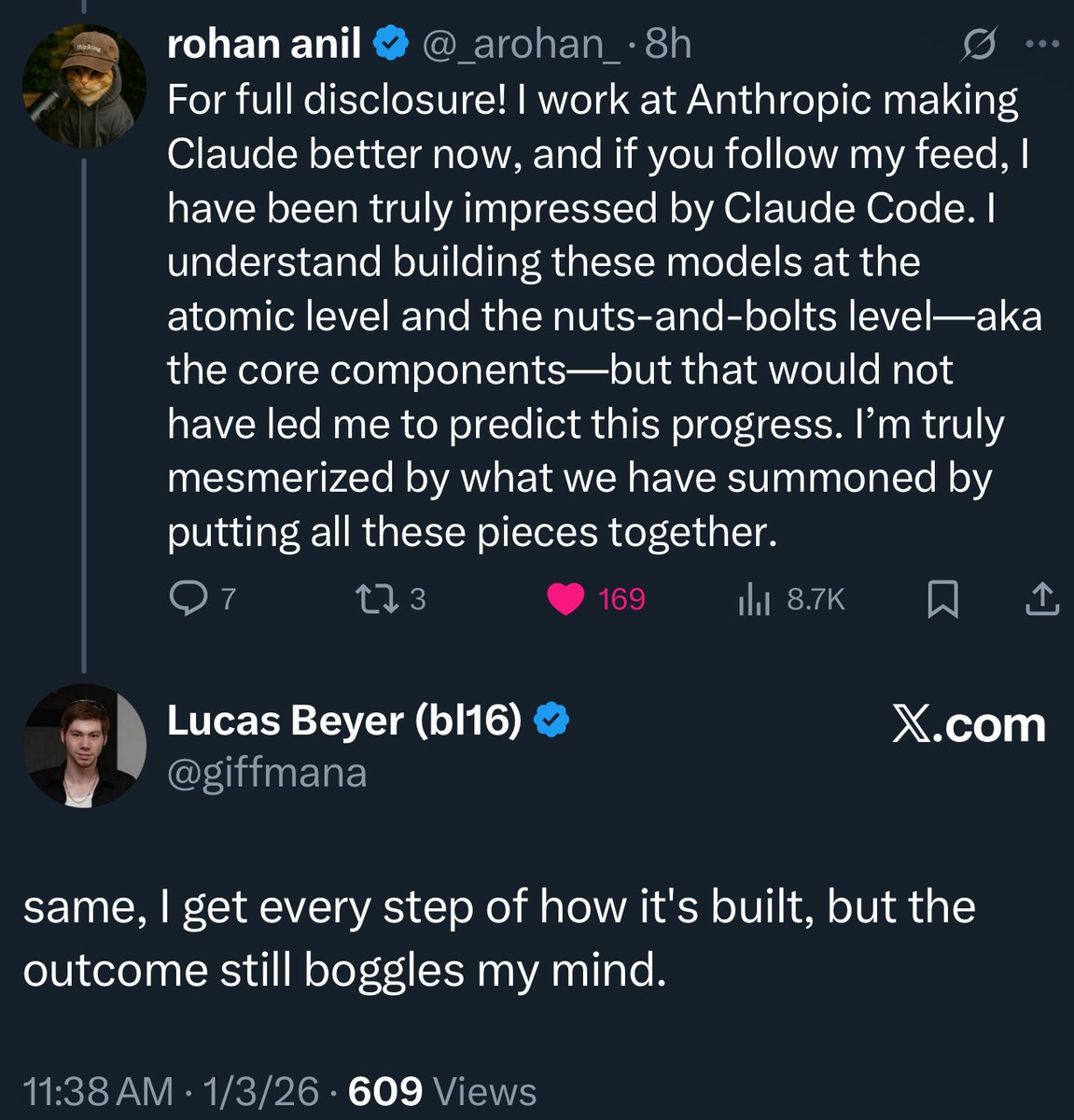
ex-Google and Meta distinguished engineer, Gemini co-author @_arohan_: “if I had agentic coding and particularly opus, I would have saved myself first 6 years of my work compressed into few months.” This matches my experience. AI collapses the learning curve, and turns junior engineers into senior engineers dramatically fast. New-hire onboarding on large codebases shrinks from months to days. What used to take hours of Googling and Stack Overflow is now a single prompt. AI is also a good mentor and pair programmer. Agency is all you need now.







Nicolas Maduro on board the USS Iwo Jima.