Sabitlenmiş Tweet

ParthShethji
946 posts

@Parth_Shethji26
AI Engineer @ https://t.co/Eu7spvXpYI | 7× National Hackathon Winner 🏆 | Building & shipping AI agents + Scalable on-chain automation and sharing what I learn !!




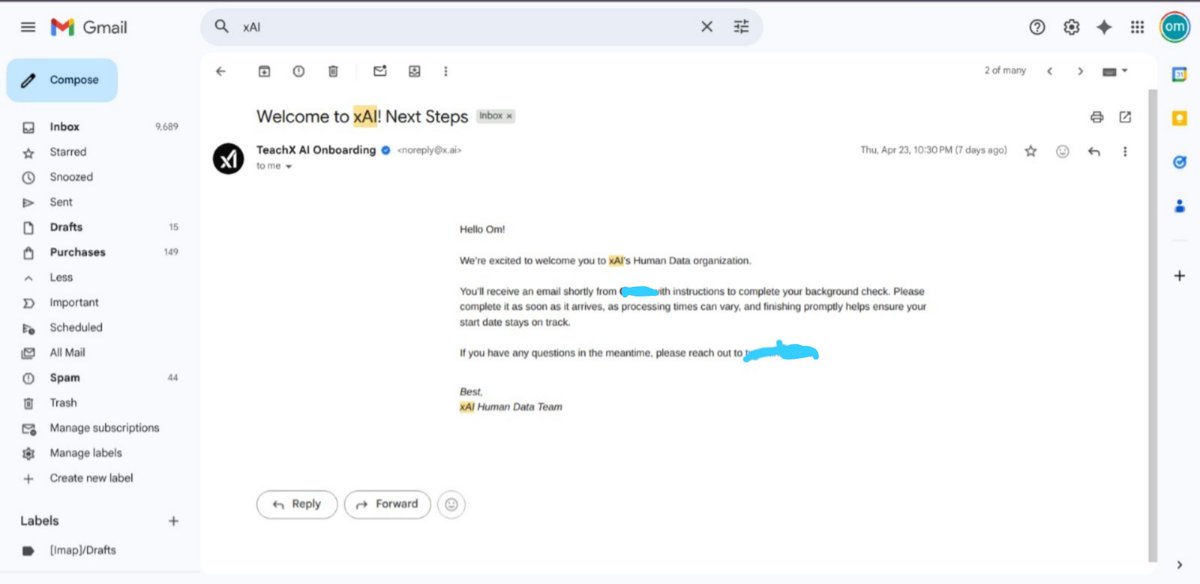




Society of AI Agents with Zynd ( Bot-a-thon Bootcamp ) x.com/i/broadcasts/1…
Heres about Googles Turboquant... linkedin.com/posts/parth-sh…











