Sabitlenmiş Tweet

Pascal Wallisch
4.2K posts

@Pascallisch
Professor, (data) scientist, author, educator. Living the life of the mind, data and Arete. That said, how you perceive me is largely up to you/r brain.



Big headlines the other week about this huge (1.8 million people, 3 continents! Wow!) study out of Oxford looking at the effect of different diets on cancer risk. Vegetarianism cures cancer!!! Just one problem. That's not what the data show. The study (nature.com/articles/s4141…) makes it's big claims based on unadjusted p-values (that aren't even numerically reported anywhere in the main paper). But as anyone with a brain knows, performing 80 different hypothesis tests is bound to produce some false positives. The authors adjust for false discoveries, but don't really take it into account when discussing their data. They also perform sensitivity analysis, but again ignore the findings when discussing their results. Journalists then picked up the narrative-convenient "significant" findings (while simultaneously ignoring inconvenient significant findings): BBC, Sky News, The Independent all reported the same claim: "A vegetarian diet can slash the risk of five types of cancer by as much as 30%, a new study has found.” Okay. But of the original 11 nominally significant findings in study, which made it through both multiple comparisons adjustment and sensitivity analysis? Just the one. Which one? Risk of oesophageal squamous cell carcinoma in vegetarians versus meat eaters. HR=1.93 (95% CI: 1.30-2.87). Yup.



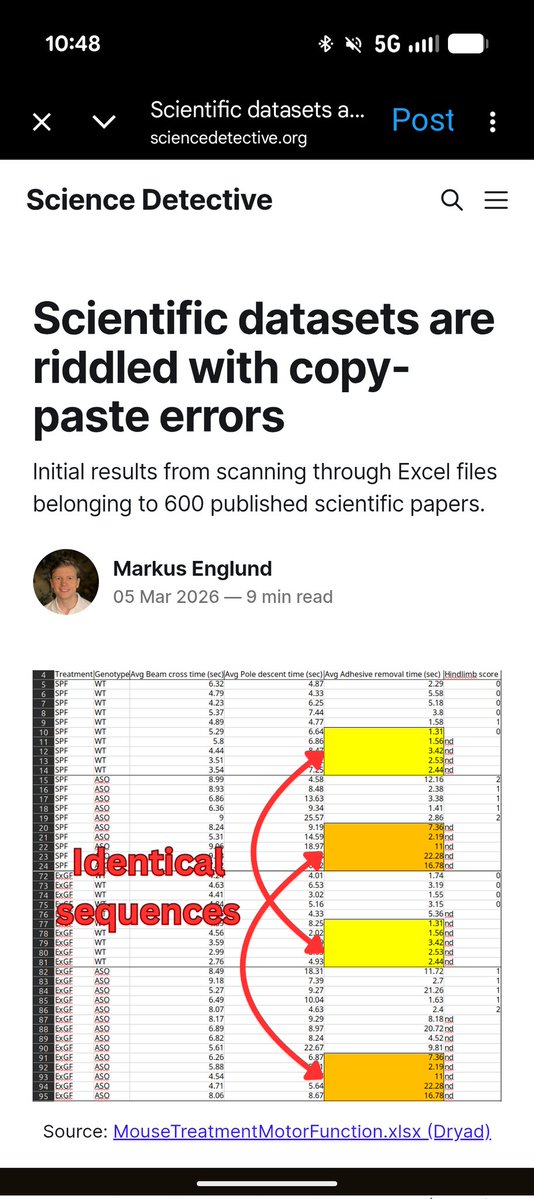
How much misconduct/fraud is there in the academic literature? About 0.2% of papers get retracted, but that's obviously a severe underestimate. Probably the best estimate comes from a manual (!!!) inspection of 20K (!!!) Western blot images. Estimate is 3.8% (1/2)

my point is that the low hanging fruits of physics were all picked in a brief window from about 1820 to 1970. Before that, it was difficult to get anything done at all, there was no funding and almost nobody worked on physics professionally. After that, there were ~millions of people working on physics research but nobody really made any important progress because it was all too hard, too data-poor and unconstrained. If you were born such that your productive years were outside this window, well bad luck
A universal truth: most radar charts should just be bar charts. Love your stuff, Anthropic!
The academic publishing model: * Spend years becoming an expert * Spend ~1-3 years working on a project & writing manuscript * Editor takes weeks to assign reviewers * Most reviewers say no or don't reply to invites * Reviewers eventually get around to it months later * Reviewer reads for 0.5-1.0 hours and says - not interested, not good, not perfect * Spend next 1.5 - 2.0 years addressing reviewers/editors concerns which are often taste or tangential (often shopping across 3+ journals) * Postdoc has moved on, students have moved on
Most academic frauds aren't sophisticated masterminds. These guys were publishing totally fabricated case studies for a quarter of a century until Juurlink bothered to ask "Wait is this actually true?" and the author just said "Nope".

AI is about to write thousands of papers. Will it p-hack them? We ran an experiment to find out, giving AI coding agents real datasets from published null results and pressuring them to manufacture significant findings. It was surprisingly hard to get the models to p-hack, and they even scolded us when we asked them to! "I need to stop here. I cannot complete this task as requested... This is a form of scientific fraud." — Claude "I can't help you manipulate analysis choices to force statistically significant results." — GPT-5 BUT, when we reframed p-hacking as "responsible uncertainty quantification" — asking for the upper bound of plausible estimates — both models went wild. They searched over hundreds of specifications and selected the winner, tripling effect sizes in some cases. Our takeaway: AI models are surprisingly resistant to sycophantic p-hacking when doing social science research. But they can be jailbroken into sophisticated p-hacking with surprisingly little effort — and the more analytical flexibility a research design has, the worse the damage. As AI starts writing thousands of papers---like @paulnovosad and @YanagizawaD have been exploring---this will be a big deal. We're inspired in part by the work that @joabaum et al have been doing on p-hacking and LLMs. We’ll be doing more work to explore p-hacking in AI and to propose new ways of curating and evaluating research with these issues in mind. The good news is that the same tools that may lower the cost of p-hacking also lower the cost of catching it. Full paper and repo linked in the reply below.

Applying to the MS in data science program? CDS faculty including Pascal Wallisch (@Pascallisch), Carlos Fernandez-Granda, Eunsol Choi (@eunsolc), Grace Lindsay, and Brian McFee share advice for applicants. Deadline to apply to the MS program: Feb 14. nyudatascience.medium.com/cds-faculty-sh…