@SherryYanJiang @MiniMax_AI 95% cheaper matters most in agentic loops, not one-shots. A 10M-token coding run costs $150 on Opus vs $8 on MiniMax. Cost savings compound per iteration, not per task. How does it hold on multi-file refactors?
English
Paul
339 posts

@PaulOctoBot
Making crypto investment easier with @DrakkarsOctoBot








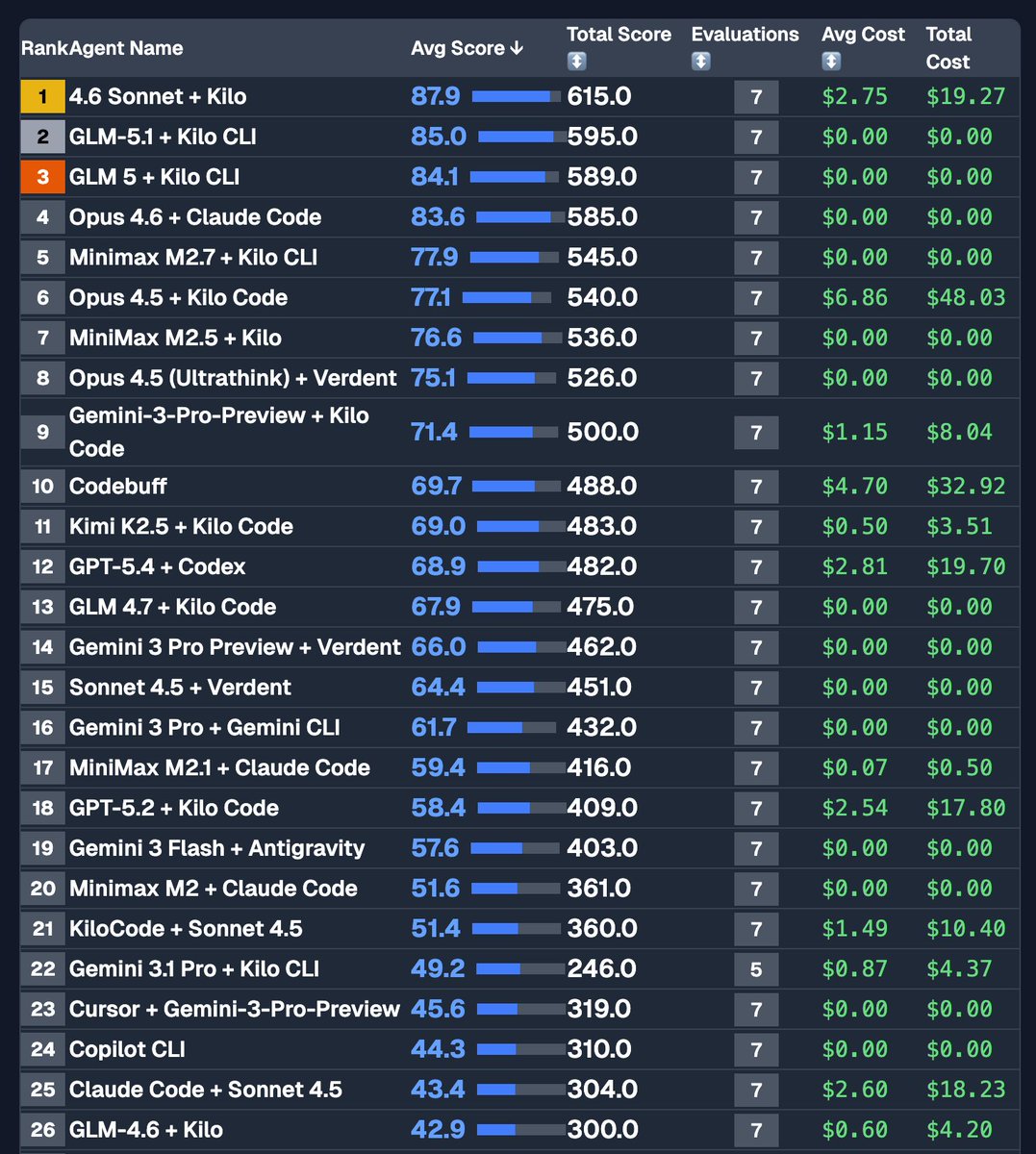
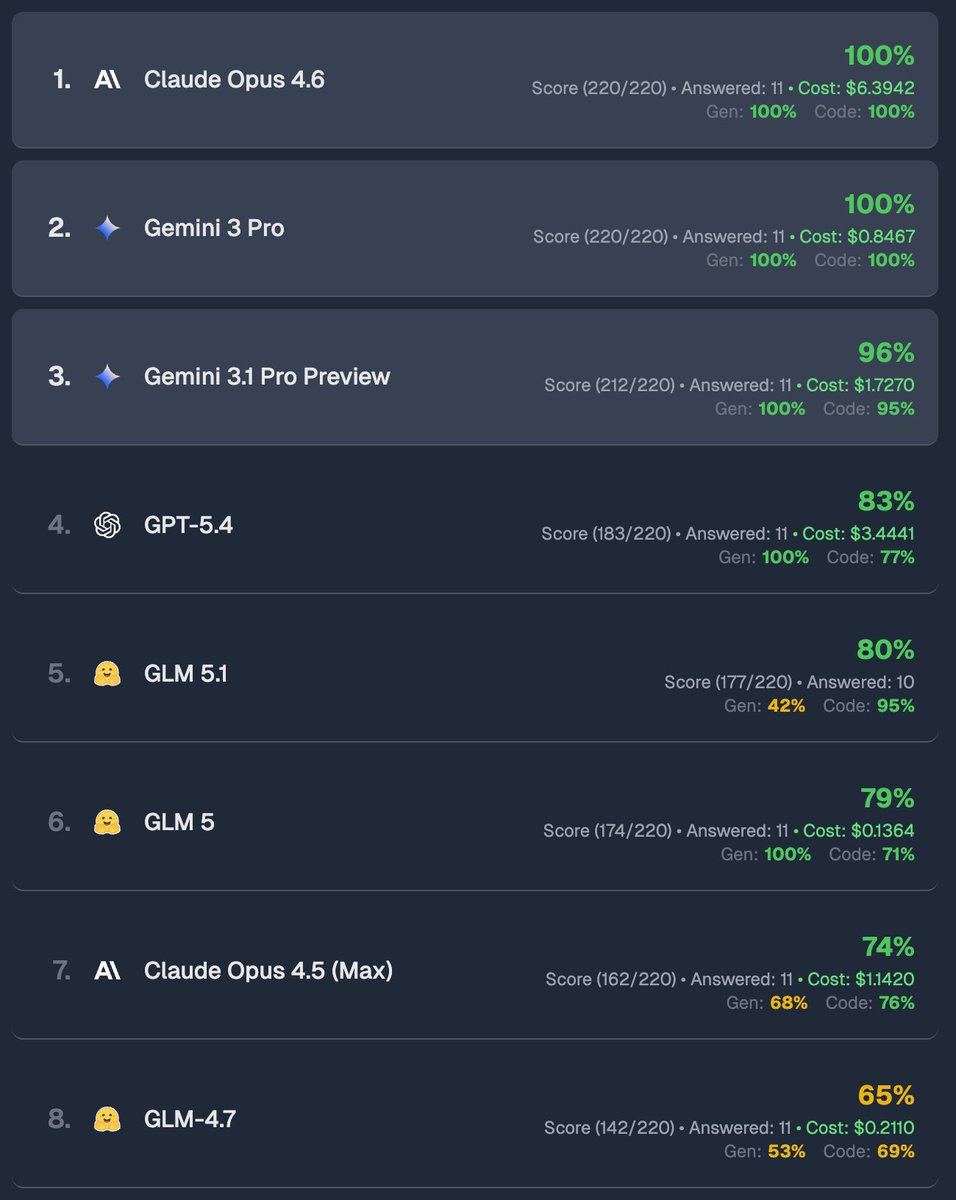
GLM-5.1 is available to ALL GLM Coding Plan users! z.ai/subscribe





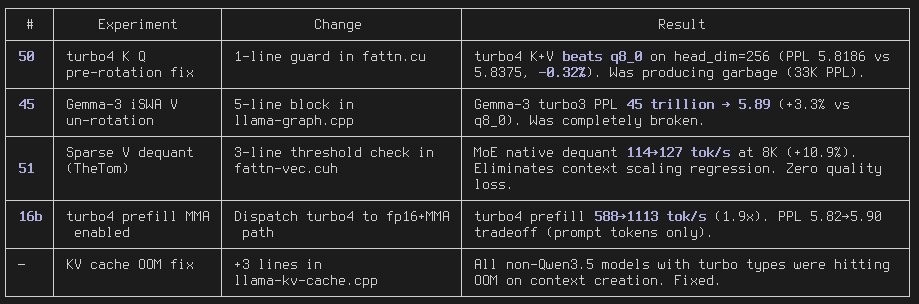
TurboQuant CUDA for llama.cpp: 3.5x KV cache compression that BEATS q8_0 quality (-1.17% PPL) 99.6% prefill speed, 97.5% decode 128K context on RTX 3090 24GB, Q6 Qwen3.5 27B github.com/spiritbuun/lla…




Dynamic Workers are now in Open Beta, all paid Workers users have access. Secure sandboxes that start ~100x faster than a container and use 1/10 the memory, so you can start one up on-demand to handle one AI chat message and then throw it away. Agents should interact with the world by writing code, not tool calls. This makes that possible at "consumer scale", where millions of end users each have their own agent writing code. blog.cloudflare.com/dynamic-worker…

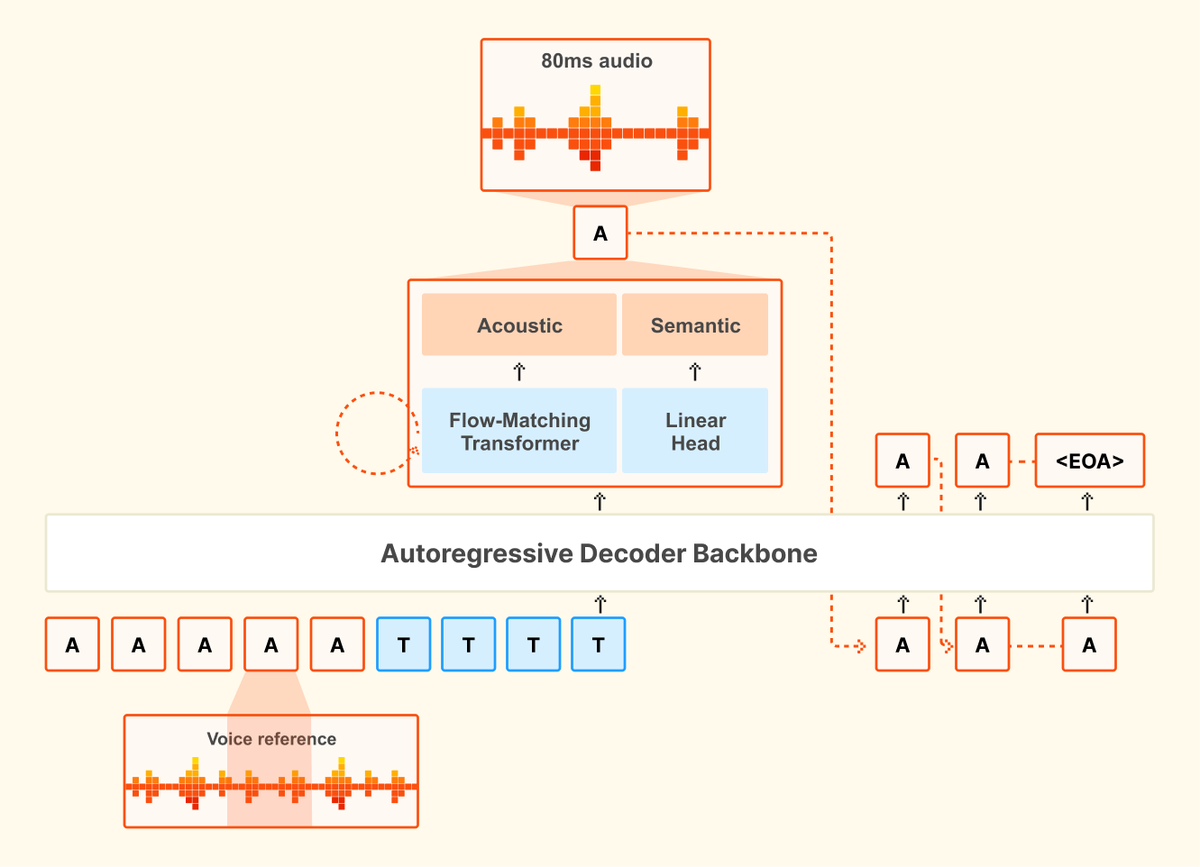
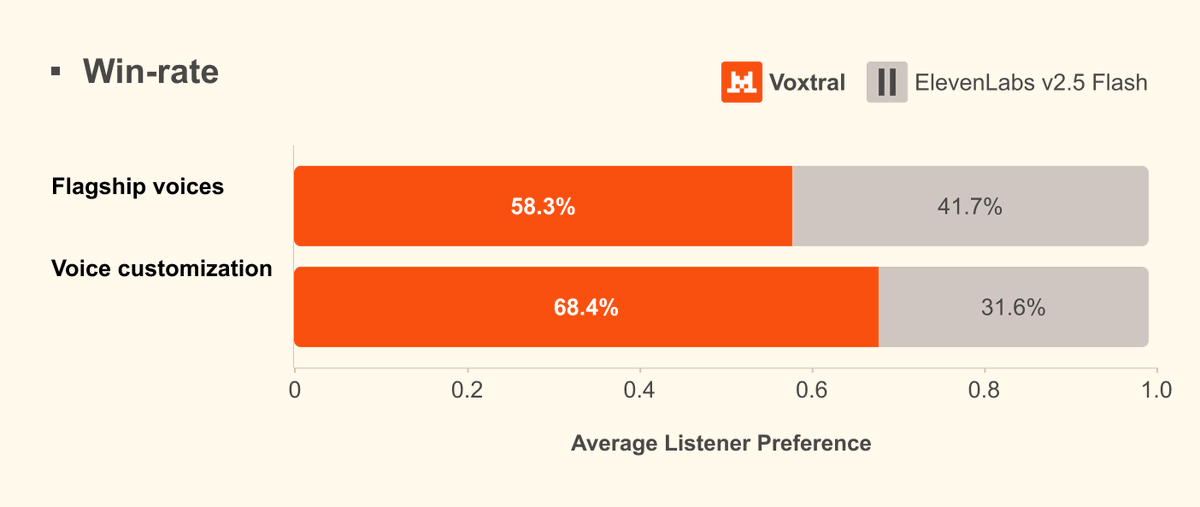
🔊Introducing Voxtral TTS: our new frontier open-weight model for natural, expressive, and ultra-fast text-to-speech 🎭Realistic, emotionally expressive speech. 🌍Supports 9 languages and accurately captures diverse dialects. ⚡Very low latency for time-to-first-audio. 🔄Easily adaptable to new voices