
phil
112 posts

phil
@PhilippeFlops
Classically trained and practicing mechanical engineer. Wannabe coder.
London, England Katılım Mayıs 2026
38 Takip Edilen19 Takipçiler

We found and fixed two issues that could explain this degradation of the capability of GPT-5.5 in Codex over the last ~ 48 hours.
We are monitoring over the coming hours to fully confirm and I will reset usage limits this evening.
Apologies and now is the time for /fast maxxing.
Tibo@thsottiaux
Codex team is aware of reports of GPT-5.5 performing worse for some users and investigating. We don't have anything conclusive yet and systems are healthy but we will share updates as we go.
English

🧪 Updated 🔄 Unsloth MTP is delivering big gains!
Up to ~50% faster than previous MTP versions and up to 2x over standard GGUF on Qwen3.7-27B.
👀 I triple checked Q8_0. It had the best MTP hit rate @ 76.45% (cached_tokens was 0)
💻 RTX 5090 results:
🔥Q4_K_XL → ~120 tps (+100%)
⚡ Q6_K_XL → ~95 tps
💨Q8_0 → ~90 tps 🤷♂️
Recent llama.cpp improvements (like --spec-draft-p-min 0.75) are pushing MTP even further.
💪Local inference keeps getting stronger.
Link in ALT.

David Hendrickson@TeksEdge
💪 Unsloth pushed Qwen3.6 MTP even further. ⚡ Qwen3.6 MTP models jumped from 1.4x → 1.8x faster in the last 2 days Thanks to a new llama.cpp update: --spec-draft-p-min 0.75 + --spec-type draft-mtp They also raised --spec-draft-n-max from 2 → 6 for more aggressive drafting. ✅ Bigger speedups on local inference ✅ Still works with simple CLI flags ✅ New small MTP GGUFs released too (0.8B–9B) Local Qwen just got quicker.
English

Qwen3.6 MTP Unsloth GGUFs now run 1.8x faster, increased from 1.4x just two days ago!
This is due to llama.cpp adding --spec-draft-p-min 0.75!
Args have also changed from
--spec-type mtp
to
--spec-type draft-mtp
Also increase --spec-draft-n-max 2 to 6
We also released Qwen3.6-0.8B, 2B, 4B, 9B MTP GGUFs! We'll be providing more soon!
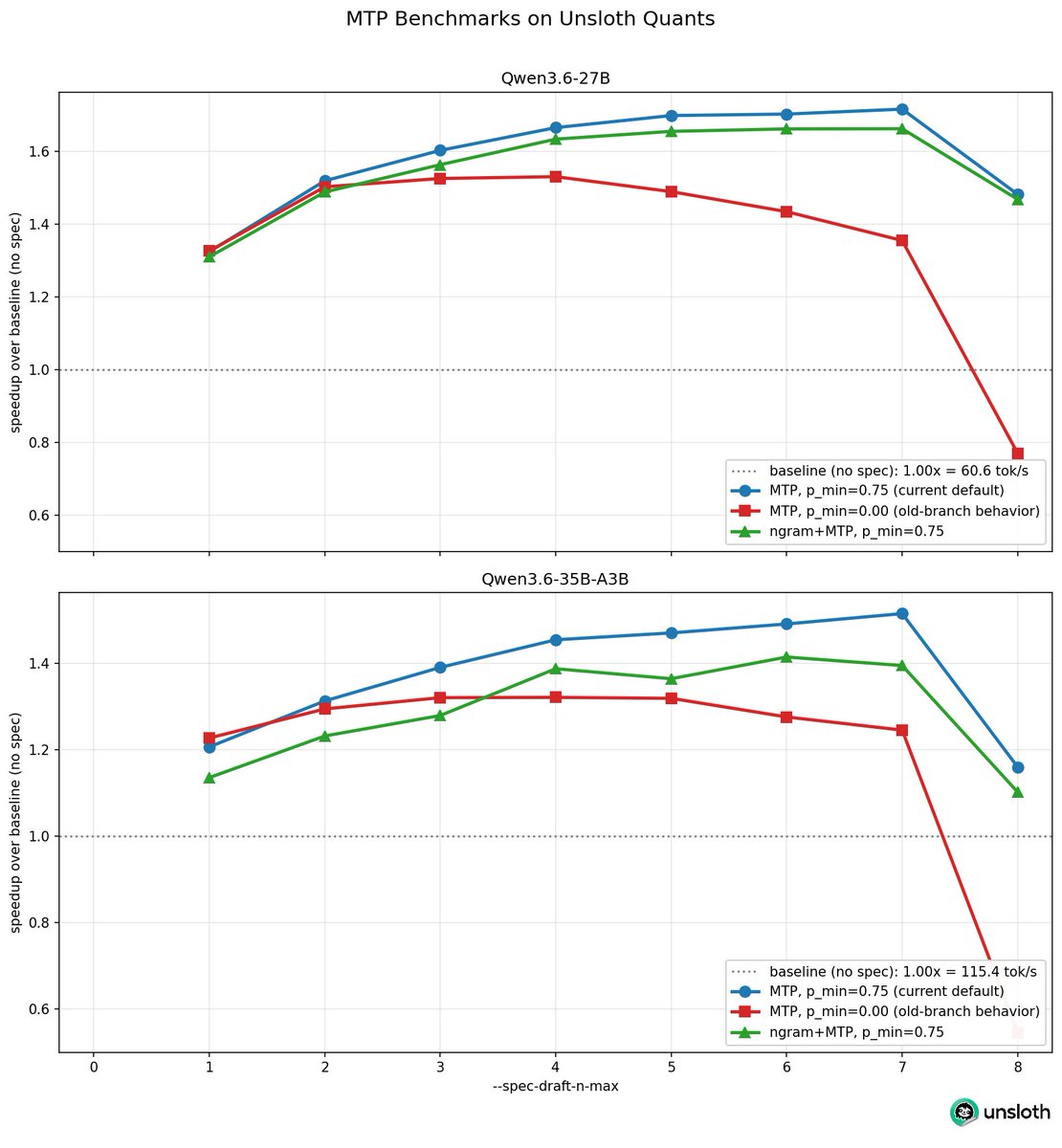
For folks who find the new updated branch to have some perf regression, set --spec-draft-p-min to 0.0 to get the old behavior - we provided a plot of the old branch (red) vs the new branch (blue / green) as well.
Also you can use 2 speculative decoding algos - you can add ngram via --spec-type ngram-mod,draft-mtp - the perf isn't yet optimized so I'll do more benchmarks to find better numbers - see github.com/ggml-org/llama…
Guide for MTP: #mtp-guide" target="_blank" rel="nofollow noopener">unsloth.ai/docs/models/qw…
English
I ran a local LLM bakeoff on my RTX 5090 box.
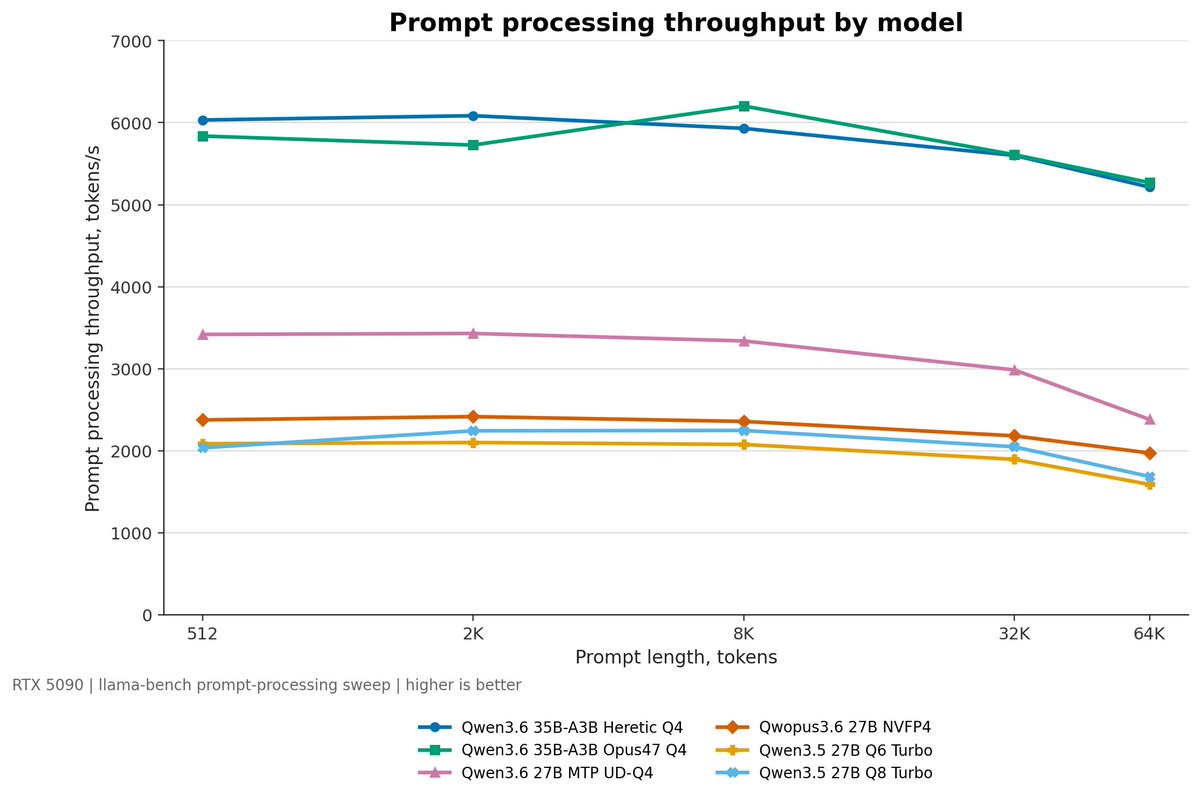
Machine is a Ryzen 9 9950X3D with an RTX 5090 32GB, running llama.cpp locally. The main use case is Claude Code-style coding work, so I care about both prompt processing and decode speed as context gets longer.
Models tested:
Qwen3.6 35B-A3B Heretic Q4
Qwen3.6 35B-A3B Opus47 Q4
Qwen3.6 27B MTP UD-Q4
Qwopus3.6 27B NVFP4
Qwen3.5 27B Q6 Turbo
Qwen3.5 27B Q8 Turbo
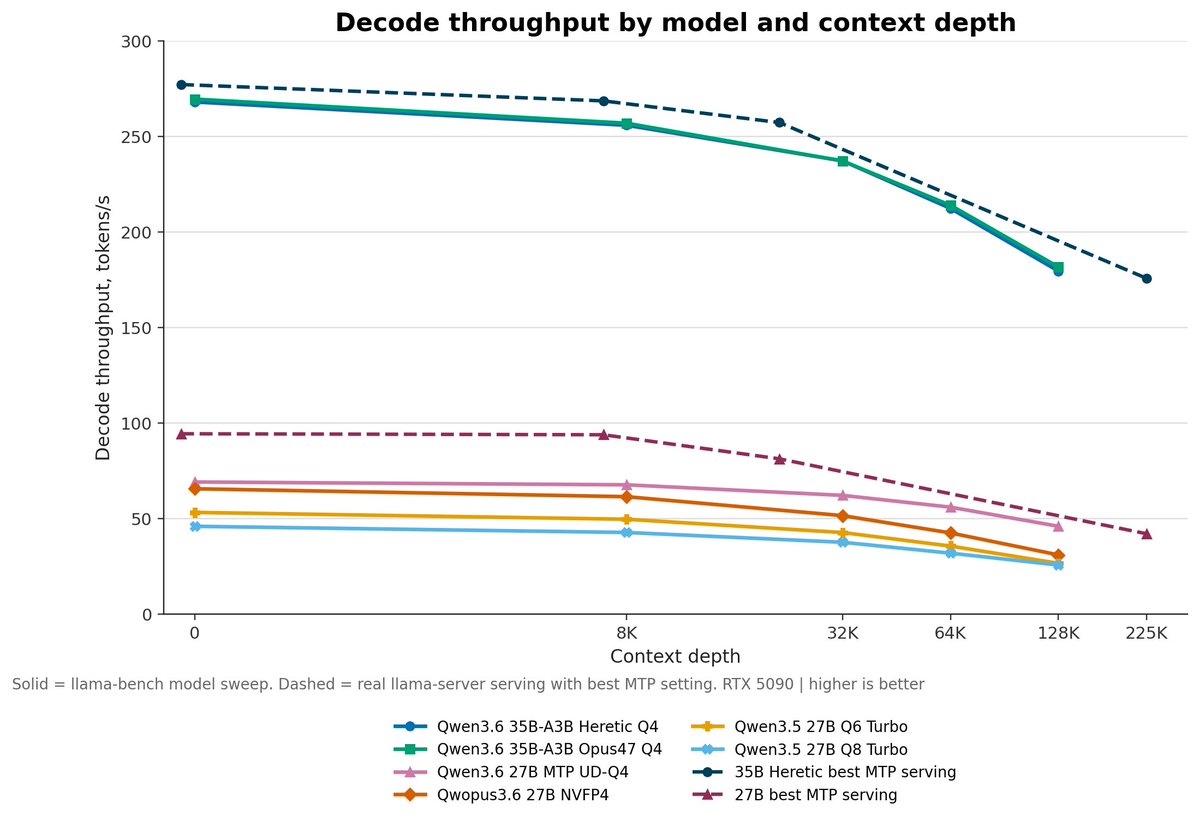
In the standard decode sweep:
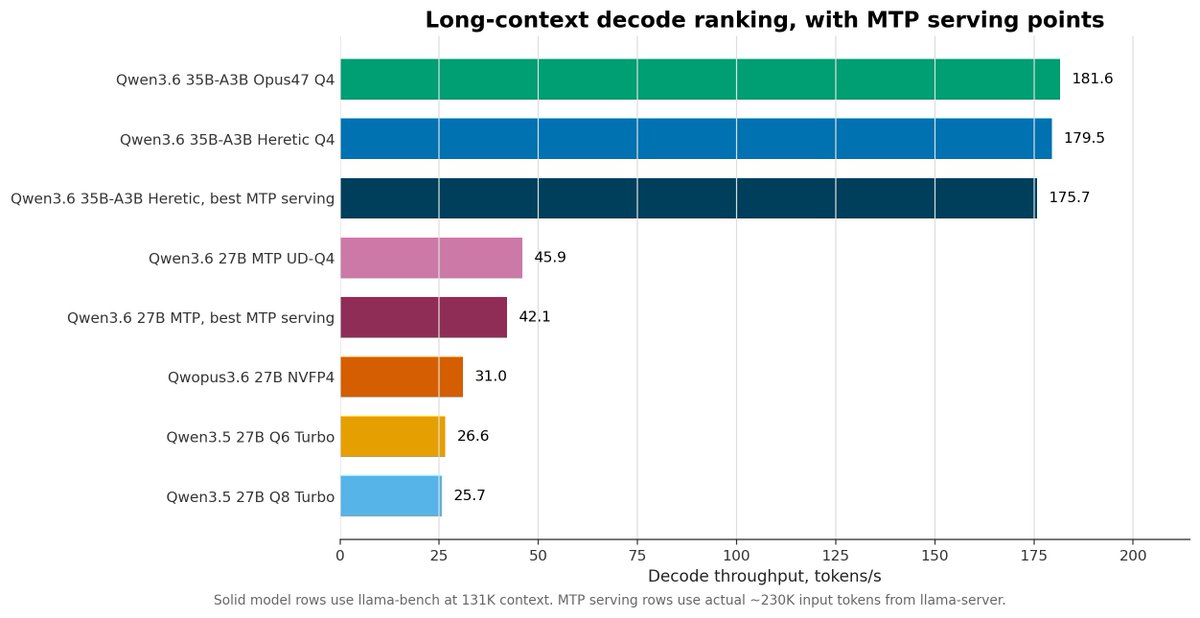
Qwen3.6 35B-A3B Opus47 Q4 did about 269 tok/s short context and 182 tok/s at 131K context.
Qwen3.6 35B-A3B Heretic Q4 did about 268 tok/s short context and 179 tok/s at 131K context.
The best 27B line was around 69 tok/s short context and 46 tok/s at 131K context.
I also tested actual MTP serving through llama-server, because llama-bench does not exercise the MTP path. MTP does help, but it does not change the overall winner.
The 35B Heretic MTP setup reached about 277 tok/s short context and 176 tok/s at roughly 230K actual input tokens. The 27B MTP model had a bigger relative uplift, but was still much slower in absolute terms.
So for my setup, the practical winner is the Qwen3.6 35B-A3B stack. The Opus47 and Heretic variants are basically neck and neck on raw speed, and Heretic with MTP enabled looks like the best local serving option for coding.
Solid lines in the chart are the consistent llama-bench model comparison. Dashed lines are real llama-server MTP serving runs.

English



BREAKING: The Bill and Melinda Gates Foundation has sold 100% of its Microsoft, $MSFT, position which was a total of 7.7 million shares.

English
@HarryScoffin Leasehold and stamp duty need to disappear.
They don’t exist in many countries and it makes moving so much better.
English

Leasehold IS the issue. We find leaseholders who claim Right to Manage are making 20-30% savings on service charges. Commissions to freeholders and related party transactions are endemic. But you wouldn’t accept this as you are a housing lobbyist, no?
Anna Clarke@AnnaClarke_____
@robblackie Leasehold isn't the main issue - more higher construction costs, high interest rates, Building Safety Regulator (costs & delays) & taxing landlords and overseas buyers depleting the market for flats.
English
I called it!
We are moving out of our place at present, a Wandsworth zone 3 new build.
The landlord is currently doing viewings. There have not been many tenants, and few are putting in offers (I think he’s asking a bit much).
It’s far from what was going on after the pandemic, nowhere near as much demand, and I suspect that as tenants hand in notices it will further reduce demand.
Something quite telling is that every estate agent in a 10-mile radius has been blasting letters through the door trying to snatch the listing from the current estate agent.
English


I agree.
This is only a tentative view rather than something I have worked through formally:
My intuition is that for these systems to move beyond their current limitations, they need some ability to do what humans do: learn beyond their existing knowledge, test ideas against the real world, and update their internal model based on the outcome. Humans do not just infer from a fixed body of knowledge; we experiment, observe, revise our assumptions, and gradually improve our understanding.
Without that kind of closed-loop learning, large language models are still mostly operating in interpretation mode. They can reason over what they already know, and they can use tools, but they do not naturally update themselves in the way a human does through experience.
You can already see the beginnings of this in practical workflows. For example, I use something like “continual learning” through skills files or project memory. I try to instruct the AI not to rely purely on pre-trained assumptions, but to actually test things. For instance, it may assume that a particular data pipeline is best because that was true in its training data, but that conclusion might be based on benchmarks from ten years ago on completely different hardware. So instead, I ask it to run benchmarks, add telemetry, compare real outputs, and document the findings.
In that setup, the AI starts to build a project-specific knowledge base and improve its future decisions. But that learning is still externalised into markdown files, documentation, memories, or tool outputs. It is not the same as the model actually updating its own weights or changing its underlying representation of the world.
I suspect that once those problems are solved - genuine continual learning, reliable real-world feedback loops, and the ability to update beliefs from experiments - then we may be much closer to AGI, and perhaps eventually ASI.
Embodiment could also be a major step. If AI systems are coupled with bodies, sensors, robotics, vision, touch, and other forms of real-world interaction, they would have far richer data streams to learn from. That could make their learning much more like ours: grounded in physical reality rather than only in text or symbolic representations.
But in their current form, my view is that they are still limited. They are extremely capable inference systems, but without persistent self-updating, grounded experimentation, and embodied feedback, claims about AGI remain speculative.
English

@PhilippeFlops It's a very solid and nuanced point you are making - sometimes extrapolation works, even if not always.
But should shaky extrapolations be used to justify trillions of dollars of value orbiting high-risk speculative AGI/ASI bets?
And should it be taken as truth?
I think not.
English
Here is your daily reminder that there is *zero* strong empirical evidence that LLMs can autonomously exponentially self-improve into an "AGI" or "ASI".
English
I’m a mechanical engineer and have worked on data centres and process applications.
In the type of evaporative or adiabatic heat-rejection equipment I’m referring to, water is sprayed into the air stream, or over wetted media, before the air is drawn across the heat exchanger. As some of that water evaporates, it adiabatically cools the entering air. That is effectively a form of free cooling.
The lower entering-air temperature increases the temperature difference between the air and the fluid on the other side of the heat exchanger, which increases the heat-transfer driving force and improves heat rejection for a given heat exchanger area and overall heat-transfer coefficient. In some regimes, particularly natural or mixed convection, the heat-transfer coefficient itself can also vary with temperature difference, because ΔT appears in the Grashof/Rayleigh number. But the main point here is that evaporative cooling improves the heat rejection performance. Without it, you would generally need larger heat exchangers, more airflow, more fan and pumping power, and higher material costs to reject the same amount of heat.
Water quality is also important. In much of the UK, mains water can be quite hard, so the make-up water often needs appropriate treatment to control scaling, fouling, corrosion, and biological growth. That does not necessarily mean full deionisation; it may involve softening, filtration, chemical dosing, blowdown control, or other treatment depending on the system.
I also think your comment about the water not being recycled is too broad. In cooling towers, closed-circuit coolers, and evaporative condensers, the spray water is normally recirculated. The water that does not evaporate drains into a basin, tray, or sump and is pumped back through the spray system. Some water is lost through evaporation, drift, and blowdown, so make-up water has to be added, but the bulk of the spray-water circuit is commonly recirculating.
There are some adiabatic pre-cooler designs where the water is once-through or mostly evaporated, so it does depend on the specific equipment. But for the recirculating evaporative systems I’m talking about, it is not correct to say that the water is simply sprayed once and wasted.
English


If you would have told me a few years ago, former USAF guy with a picture of the Signing of the Declaration of Independence on his wall, that China would be giving me freedom I would have laughed at you
I want China to dominate open source AI.
Anthropic@AnthropicAI
We've published a paper that explains our views on AI competition between the US and China. The US and democratic allies hold the lead in frontier AI today. Read more on what it’ll take to keep that lead: anthropic.com/research/2028-…
English
@danielhanchen @UnslothAI I just tried this on my 5090 setup with llam.cpp and I’m getting 291 tok/s, does that sound about right?
Qwen3.6 35B uncensored heretic native MTP Q4_L_M
English

i still don't fully get why
dario sees china's open-source model rise as such a huge security emergency
he keeps saying chinese labs are 6-12 months behind the US, but at the same time warns that open-weight models will close the gap much faster
i think his real fear is china scaling cheaply and narrowing the gap faster than expected

Anthropic@AnthropicAI
We've published a paper that explains our views on AI competition between the US and China. The US and democratic allies hold the lead in frontier AI today. Read more on what it’ll take to keep that lead: anthropic.com/research/2028-…
English

Message to entrepreneurs Your product is their feature
ChatGPT@ChatGPTapp
A preview for Pro users: a new personal finance experience in ChatGPT. Pro users in the U.S. can securely connect financial accounts, see where their money is going, and ask questions based on the information they choose to connect. Your full financial picture, now in ChatGPT.
English
@StockViking @Kalshi This is what I’m worried about. IPOs are big risk.
English

@Kalshi Congrats to all the insiders that will be unloading their shares to naive retail investors at a $2T valuation. $SPCX
English


Not unusable—10-14 t/s on a 27B model locally is actually solid performance for DGX Spark.
It feels a bit deliberate for fast chat (1-2s latency), but excellent for coding, analysis, or any non-real-time work. Streaming helps, and tweaks like speculative decoding make it snappier. Most local users are happy with it.
English

Two of these connected can run DeepSeek v4 Flash and one can run Nemotron 120B and Qwen 3.6 27B!
NVIDIA AI PC@NVIDIA_AI_PC
Run @NousResearch's Hermes Agent fully locally on DGX Spark. 🚀 Our newest playbook shows you how to get set up via @Ollama step by step. 👇
English
On a single DGX Spark, Qwen 3.6 27B typically hits ~10-14 tokens/sec in standard llama.cpp/FP8 setups (baseline ~7-10 t/s, with MTP speculative decoding pushing 14-15+ t/s).
Optimized vLLM or advanced quants can go higher, but 10-15 t/s is the common real-world range reported in NVIDIA forums and benchmarks.
English