Praneeth
399 posts


Praneeth
@PraneethreddyA6
Engineer | Generalist | Product @Cummins Filtration | @UMassAmherst













if you're about to release a model that you know has the ability to reveal zerodays in every commonly used open source project you could delay release for a few years or spend another ten billion on alignment RL. or you could just secretly fix all the zerodays yourself first.




Okay let's see who can reply to this


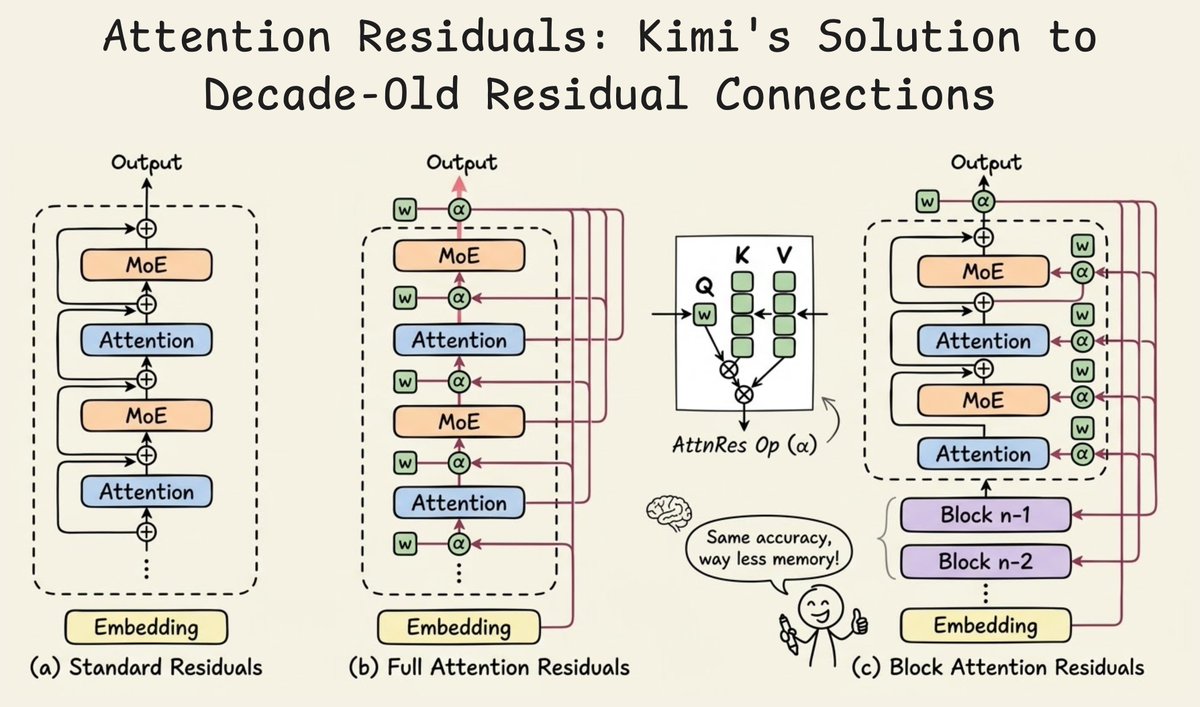
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…





This is wild. theaustralian.com.au/business/techn…

