Sabitlenmiş Tweet

Title: Generating Neural Networks with Hypernetworks: A MNIST Experiment
Introduction
Imagine training one neural network that can instantly generate other neural networks tailored to specific tasks, no retraining required. That’s the promise of hypernetworks, a meta-learning technique where a "parent" network produces the weights for a "child" network. In this experiment, I used a hypernetwork to generate autoencoders for reconstructing MNIST digits, exploring variations, minimal forms, and combinations. Here’s how it works and why it’s exciting.
The Setup: Autoencoders and MNIST
An autoencoder is a simple neural network that compresses data (e.g., a 28x28 MNIST image) into a smaller latent space (64 dimensions here) and then reconstructs it. I trained multiple autoencoders on the MNIST dataset of handwritten digits (0–9), but with a twist:
Variations: For each digit, I trained three autoencoders on different styles (e.g., slanted or thick '1's), identified via K-means clustering.
Minimal Forms: One autoencoder per digit captured its "average" or canonical version.
Combinations: Ten autoencoders handled specific digit groups (e.g., 0 and 1, or 0, 2, and 4).
This gave me 50 autoencoders (10 digits × 4 models each + 10 combinations), each with weights optimized for its task.
The Hypernetwork: A Weight Factory
Instead of storing 50 separate models, I trained a single hypernetwork to generate their weights on demand. Here’s the process:
Input: A 23-dimensional vector encoding:
Digit ID (10D one-hot, e.g., [0, 1, 0, ...] for digit 1).
Variation ID (3D one-hot, e.g., [0, 1, 0] for variation 1, or zeros for minimal).
Combination ID (10D multi-hot, e.g., [1, 0, 1, 0, ...] for digits 0 and 2).
Output: A 100,576-element tensor, flattened weights for an autoencoder (computed as 784×64 + 64 + 64×784 + 784 for its layers).
Training: The hypernetwork learned to map these inputs to the weights of the 50 trained autoencoders using mean squared error loss, running on GPU for speed.
Making It Work: Inference Without Retraining
Once trained, the hypernetwork acts like a factory. Want an autoencoder for digit 1, variation 1? Feed it [0, 1, 0, ..., 0, 1, 0, 0, 0, 0, 0] (digit 1 + variation 1), and it outputs weights. These weights are then loaded into a fresh autoencoder:
A loop iterates over the autoencoder’s parameters (e.g., encoder weights, biases), reshaping chunks of the hypernetwork’s output to match each layer’s shape.
The result?
A fully parameterized autoencoder ready to reconstruct images, no training needed.
I tested it with three cases:
Digit 1, Variation 1: Reconstructed stylized '1's.
Digit 1, Minimal: Produced a clean, average '1'.
Digits 0, 2, 4: Handled a mix of digits from one trained combination.
Visualizations showed the inputs and outputs side-by-side, proof the concept works!
Why This Matters
Efficiency: One hypernetwork replaces dozens of models. Generate weights in a single forward pass (milliseconds) instead of training from scratch (minutes).
Flexibility: Control digit styles or combinations with a simple input tweak.
Scalability: Imagine extending this to bigger networks or tasks, hypernetworks could dynamically adapt models on-the-fly.
Challenges and Next Steps
Generalization: The hypernetwork is tied to the 50 scenarios it learned. To handle new combinations (e.g., 1, 5, 7), I’d expand the training data with more digit mixes.
Complexity: Outputting 100,576 weights limits scalability. A deeper hypernetwork could struggle with bigger models, so I’d explore scaling down the autoencoder (e.g., smaller latent space) for efficiency or scaling up to handle complex tasks, balancing size and performance.
Beyond Weights: Right now, it generates weights for a fixed autoencoder architecture. Next, I’d upgrade the hypernetwork to design the architecture too, say, predicting layer sizes or types (e.g., adding convolutions). This could mean outputting a variable-length tensor describing both structure and weights, pushing it toward true model generation.
Quality: Reconstructions were solid but blurry. More epochs, a beefier hypernetwork, or architecture tweaks (e.g., deeper layers) could sharpen them.
Future experiments? Train on all digit variations, test unseen combos, scale the model up or down, and let the hypernetwork dream up architectures, maybe even swap in a classifier to predict labels instead of reconstructing.
Conclusion
This MNIST experiment shows hypernetworks can generate functional neural networks instantly, blending creativity (variations) with practicality (combinations). It’s a step toward a future where models are built dynamically, not trained individually. Code’s below, try it out, tweak it, and let me know what you think on X!
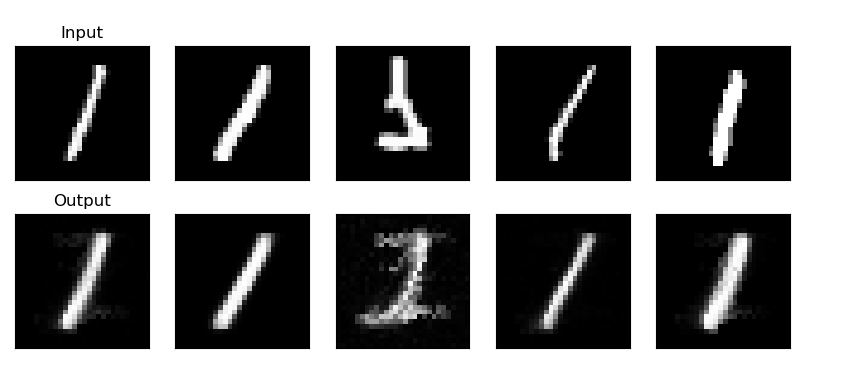



English