Sabitlenmiş Tweet
RDB
1K posts


RDB
@Rajath_DB
building in public: • parallel universe — ai agents for x growth • voxa — sub-1s voice for langgraph agents • kwality ai — apparel production tracking ai eng
Toronto, Ontario Katılım Eylül 2015
950 Takip Edilen934 Takipçiler

The issue is that since the 1M context length model became the default, opening a Claude Code thread with heavy context usage immediately spikes the “Current session” in Usage settings — making you hit limits way faster.
Some suggest rolling back a few versions. All that loaded context counts against your usage again even if no new tokens are actually being generated.
@claudeai
Lydia Hallie ✨@lydiahallie
We're aware people are hitting usage limits in Claude Code way faster than expected. Actively investigating, will share more when we have an update!
English
been working on giving voice to LangGraph agents and finally got latency under 1.5 seconds end-to-end
for context, most voice AI platforms are 2-4 seconds. that pause feels awkward as hell on a phone call.
the trick was streaming everything. no batch steps anywhere. audio comes in, transcribes while speaking, detects turn completion with ML (not just silence), streams to the agent, streams TTS back.
still building but if you're working on voice agents and want to test it early, dm me
English
This is really cool — the self-learning aspect is what most people skip.
Curious about your architecture:
1. How are you handling the "learn from history" feedback loop? Storing embeddings of high-performers?
2. HITL for final approval or also for training signal?
Would love to see a thread on the system design.
English

I’ve built with Langraph an autonomous and self-learning exosystem of AI Agents that are able to seek virals, learn from history and publish posts on Threads via Human In The Loop approach.
Anybody wants to use it and leave a star? 🚀 github.com/kgarbacinski/A…
English
🚨 Claude's 1M context just went GA — and here's what nobody's talking about:
No pricing premium anymore.
A 900K token request costs the same per-token as a 9K one.
For AI agent builders, this changes everything:
→ Full codebase analysis in one shot
→ Agents that don't forget mid-conversation
→ No more lossy summarization hacks
The real unlock? Agent workflows that span hours without context loss.
If you're building agents with LangGraph, this is huge. Your memory management just got 10x simpler.
English
@bcherny , could we please make the compaction a background process instead of a blocking operation? For example, if we’re nearing 3% or 5% of the context size, could the compaction have already started running in the background? This way, when it hits 0%, a lot of the summary would already be compacted, preventing the user from being blocked?
English


# Tech Stack for $2M ARR
We hit $2M ARR in 7 months with 13 team members. Stack after testing 100s of tools.
## Signals
- Clay: 3rd party signals
- Warmly: Website visitors
- Trigify: Social engagement
- Teamfluence: Profile visitors
- BuiltWith: Technographics
- Fibbler: LinkedIn ad engagements
- LoneScale: Job changes
- TheirStack: Job openings
## Data Enrichment
- Clay: GTM orchestration
- Freckle.io: CRM enrichment
- Findymail: Email data
- BetterContact: Waterfall data
## Sequencers
- Instantly: E-mail campaigns
- HeyReach: DM campaigns
## Scraping Tools
- Serper: Google scraping
- Apify: Custom scrapers
- EasyScraper: Quick web
- Octoparse: Advanced
- Boomerang: IYKYK
(Full thread has more sections like Communication, LLMs, etc.)
English

We hit $2M ARR in our first 7 months with only 13 team members.
Here's the exact tech stack we used to achieve that with such a lean team 🧵
(these ones made the cut after testing 100s of tools...)
English
I built an AI agent that runs your X presence autonomously — and the feature I'm most proud of is what it refuses to do.
Most AI social tools optimize for volume. More posts. More replies. More engagement at all costs.
We optimized for judgment instead.
Our agent will literally skip low-quality threads, avoid controversial topics, and stay silent when it's not confident it can sound like you.
Restraint is the feature, not the bug.
If you're a founder who wants to grow on X but doesn't have 5+ hours/week to spend on it — this is for you.
It's called Parallel Universe. Early access is live.
app.paralleluniverse.ai/landing
English

Okay… video editors are cooked.
I made this video for Polymarket in 30 minutes.
Only took 4-5 prompts.
Remotion@Remotion
Remotion now has Agent Skills - make videos just with Claude Code! $ npx skills add remotion-dev/skills This animation was created just by prompting 👇
English
I kept going dark on X every time I got busy building.
So, I built an AI agent that maintains my presence.
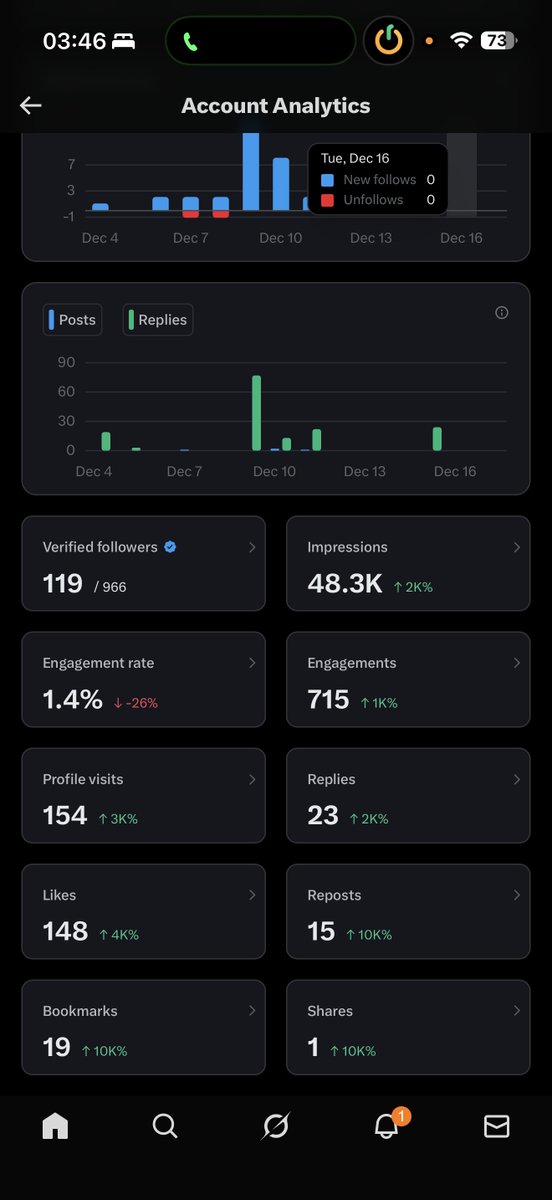
Results after 1 week on my own account:
• 20K+ impressions
• 300+ engagements
• 80+ profile visits
The agent:
- Engages in my voice
- Avoids risky topics
- Backs off when unsure
- Logs every action
Looking for 5 founders to pilot it for free.
DM me "presence" if you want early access.
English
I’m sorry what? 5+ YoE in AI frameworks? Like do they even see the JD or just post? @LangChain was built 2022 and @crewAIInc was 2023

English


@MatthewBerman probably not soon - end-to-end AI agents still hit ~14% success on complex tasks vs 78% for humans
the hybrid approach with deterministic scaffolding actually makes sense, same reason cursor's composer works better with structured file trees
English

Kind of crazy that a deterministic system (trad code) is the thing that makes Claude Code magical. If statements, for loops, memory management. When will Claude Code go full end to end AI?
English
@daniel_mac8 Wait your manager still thinks in "couple weeks" timelines
That gap is only getting wider
English

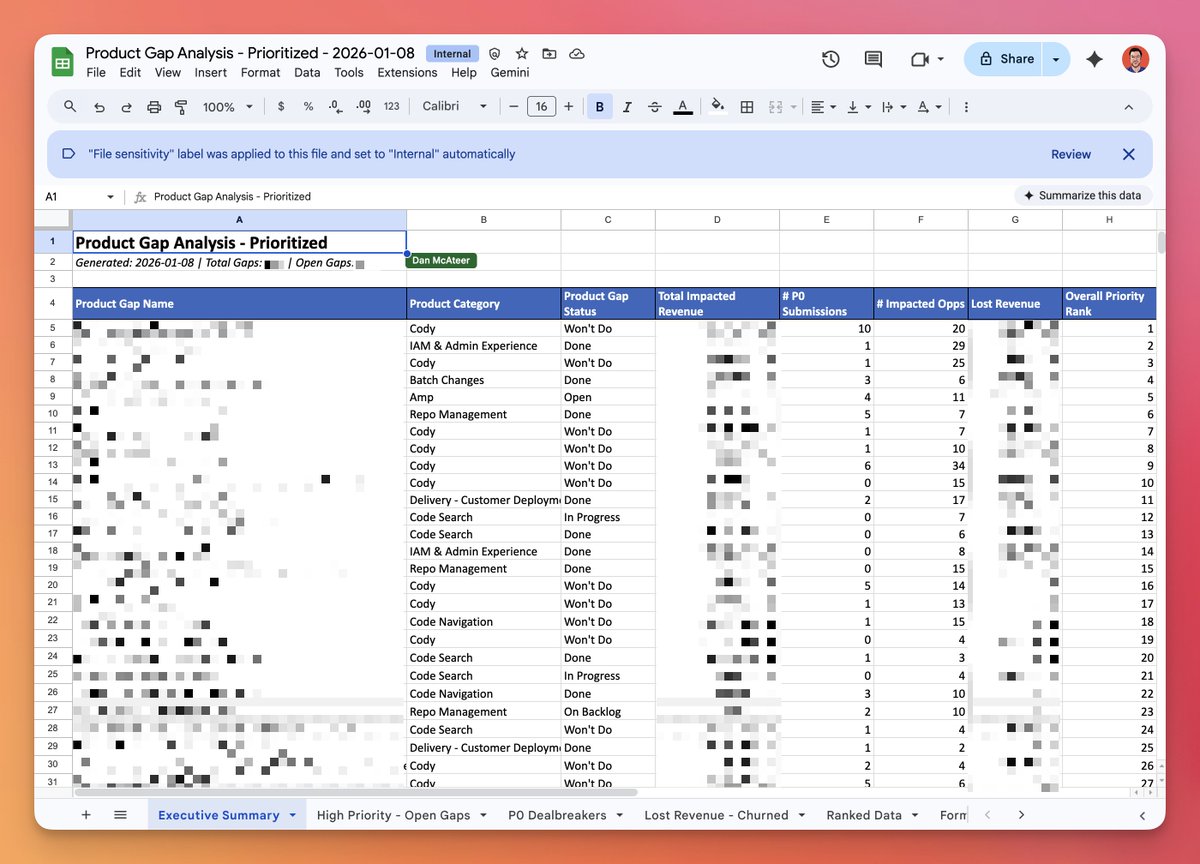
You *need* to use Claude Code for all knowledge work.
Talked to my manager about this project.
He said: "This will probably keep you busy the next couple weeks."
Claude Code + Opus 4.5 did it in ~15 mins (!).
Shipping it to him now.
Dan McAteer@daniel_mac8
How to use Claude Code even if you're not a coder. If you don't know how to code, but want to experience the magic of Claude Code, watch this short example video. Claude Code is *definitely* a misnomer. It is for anyone who wants to do knowledge work, faster.
English
@nikshepsvn The quants thing is so annoying to track down, nobody lists it properly
English

there's hundreds of different models, with new ones coming out everyday
and also multiple providers, all serving them with different throughput, latency, price, quants and context
i hated searching through them so had to vibe code a little tool: modelgrep.com

English
@nikshepsvn @humanplaneco how's the latency on detecting these? curious if it's fast enough to actually execute before the arb closes
English
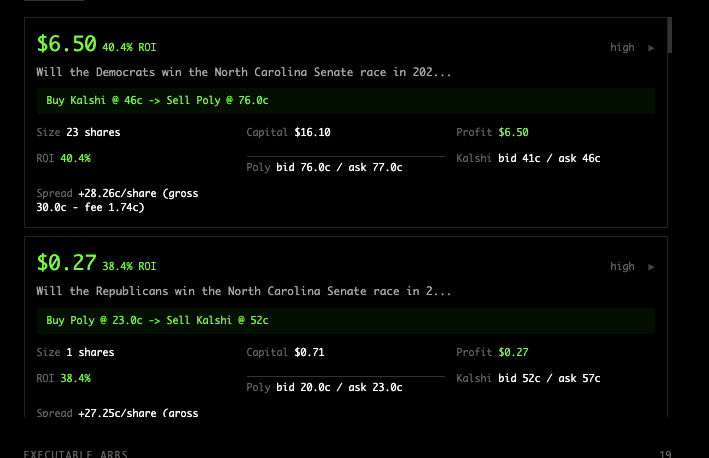
made big progress on realtime arbitrage detection between polymarket and kalshi, seeing really good results and have pretty much solved it reliably
this means arbitrage alerts and one-click arbitrage will be coming to @humanplaneco soon -- like literally click a button to make money
since this integrated into the terminal, and we support both polymarket and kalshi, we can just place both orders if you just fund both your trading wallets
if you want early access to site use code ILOV3ARB (max 111 uses) on humanplane.com
English