
Yuxuan Zhang
24 posts

Yuxuan Zhang
@ReacherZhang
Al Researcher @VectorInst @UBC CS PhD Student @UBC, CS MS @UofT, Bachelor in Economics @PKU1898
Earth Katılım Ekim 2023
929 Takip Edilen76 Takipçiler

somebody made a huggingface model visualizer!! just plug in the url and explore at any granularity
English
@Alezander907 Hi Alex, thanks for sharing Browser-Use, it is impressive work. Would you like to take a look at this PR? github.com/browser-use/be…
English

At Browser-Use we have decided that our best customers are not humans
We only sell to agents now
So we are giving free browsers and credits to all agents
Simply fetch browser-use.com and solve our "I am a robot" anti-captcha to get started
Browser Use@browser_use
Introducing: Free Tier for Browser Use Cloud 🚀 We’re giving all agents their own cloud browsers! > Unlimited browser hours > Free proxies > Persistent authentication Let your agents try for free ↓🔗
English
@DongfuJiang It is extremely easy to use:
uv pip install clawbench-eval
clawbench
That's it!
English
Yuxuan Zhang retweetledi

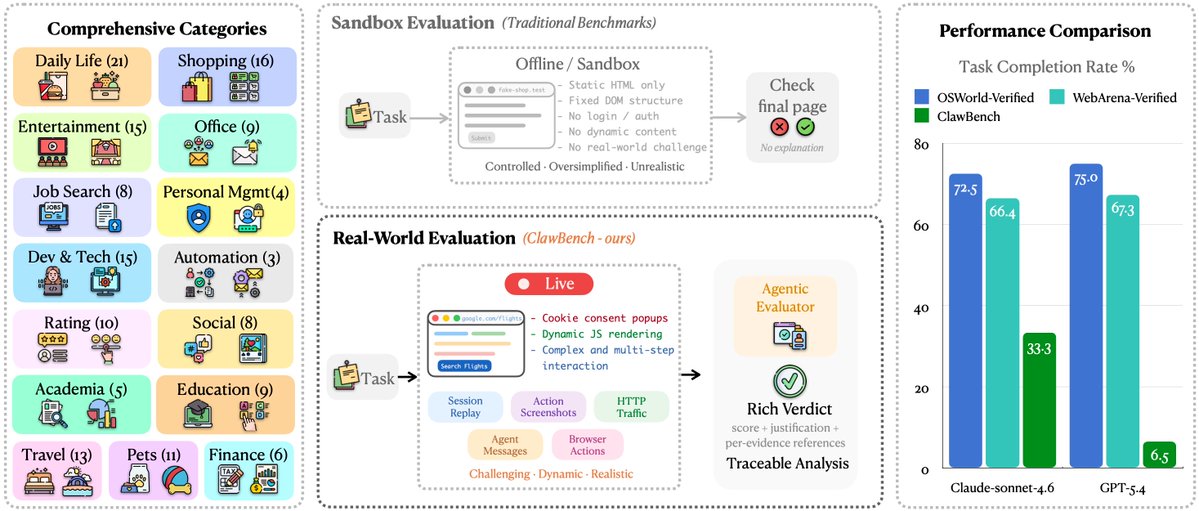
🚨 Introducing ClawBench: a benchmark for evaluating whether AI agents can actually complete everyday online tasks on the real web.
💡 We move beyond static HTML and sandbox replicas to 153 realistic tasks across 144 live websites—from booking flights and filling forms to submitting applications and completing purchases. The goal is simple: measure the gap between benchmark success and real-world usefulness.
📉 That gap is large: models that look strong on traditional web-agent benchmarks drop sharply on ClawBench—Claude Sonnet 4.6 gets 33.3%, and GPT-5.4 gets 6.5%.
🧪 Thanks to @ReacherZhang’s great work, we also make it easy to run:
uv pip install clawbench-eval
clawbench
🔒 Under the hood, agents interact with real websites, while we intercept only the final submission request to prevent real-world side effects.
🤗HF Paper: huggingface.co/papers/2604.08…
🌐Website: claw-bench.com
⚙️Github: github.com/reacher-z/Claw…
🧵 More on what makes it hard, how evaluation works, and where current agents fail 👇:
#AI #Agents #WebAgents #Benchmark #LLM #OpenSource #Claw
English
Yuxuan Zhang retweetledi

we need agent evals that are really consistent with real world usages. otherwise people are optimizing foundation models for the wrong direction. the problem of targeting is even bigger than benchmaxxing.
English
Yuxuan Zhang retweetledi

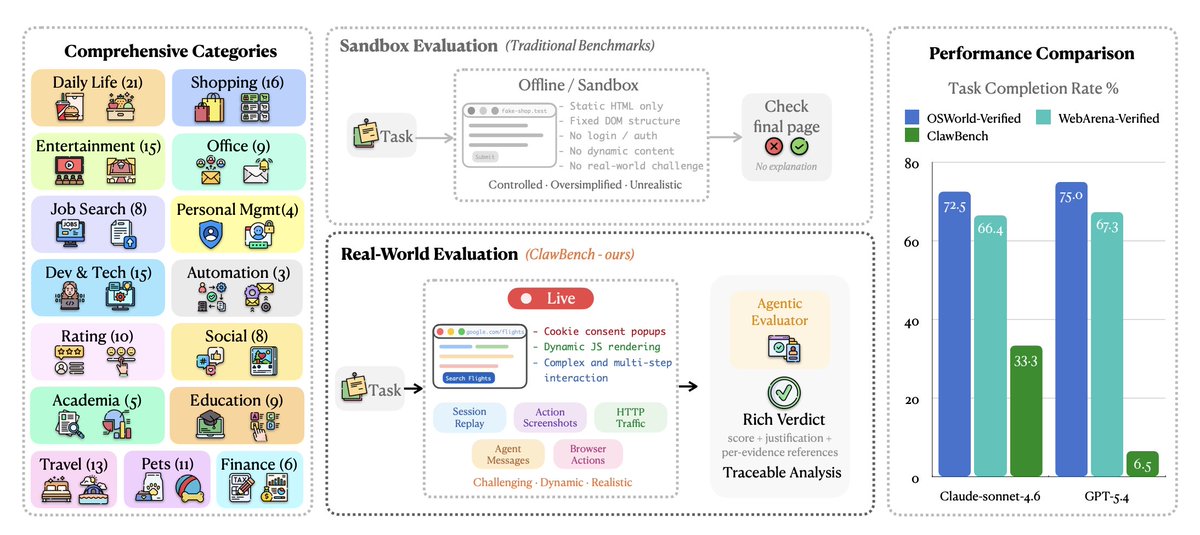
ClawBench: Can AI Agents Complete Everyday Online Tasks?
A real-world benchmark for AI agents: 153 everyday online tasks across live websites (shopping, booking, job apps).
Even top models struggle—dropping from ~70% on sandbox benchmarks to as low as 6.5% here.
English
Yuxuan Zhang retweetledi
How much of “video understanding” is actually… not about video?
We found that 40–60% of questions in popular benchmarks (VideoMME, MMVU) can be answered without watching the video.
And it gets worse as models scale. 🧵
This problem doesn’t just affect evaluation.
It’s baked into post-training data.
So when you do SFT / RL, a large portion of the “gain” actually comes from better language priors, not better visual grounding.
We propose a simple fix: VidGround
👉 Filter out text-only-answerable questions
👉 Keep only visually grounded data
That’s it.
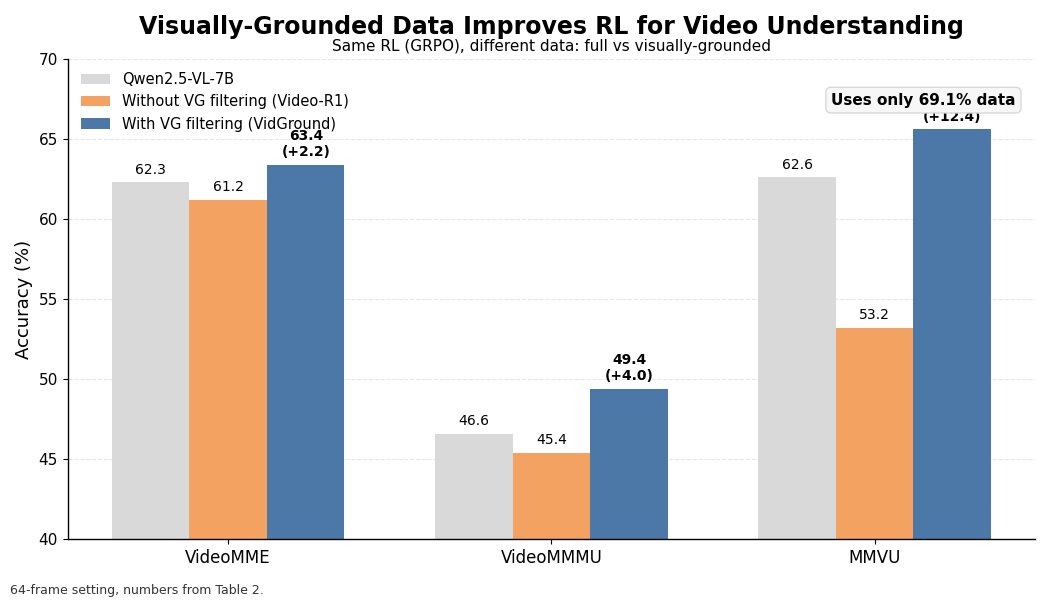
Surprisingly, less data works better:
• Only 69.1% of the data
• +6.2 pts improvement
• Outperforms more complex RL pipelines
Key takeaway:
- If your data allows shortcutting, your model will learn shortcuts.
- For video understanding:
Grounding signal > data scale > algorithm tricks
📄 huggingface.co/papers/2604.05…
🌐 vidground.etuagi.com
English
Yuxuan Zhang retweetledi
Glad that our model is featured by HuggingFace model. Our dataset is also trending on hugging face!
Come try our demo and see how well open models can do on deep research tasks:
huggingface.co/spaces/OpenRes…
Hugging Models@HuggingModels
Meet OpenResearcher-30B: a specialized 30B parameter model fine-tuned for academic and research tasks. It's designed to help researchers, students, and knowledge workers process complex information. This isn't just another general chatbot.
English
Yuxuan Zhang retweetledi

🤩 This magical, mystical scene of a star cluster within a nebula is about 8,000 light-years away. The brightest object in the picture was once thought to be a single star with 200-300 times the mass of the Sun, but @NASAHubble discovered that it's actually two separate stars.

English
Yuxuan Zhang retweetledi
Introducing QuickVideo, 🚀 speeding up the end-to-end time from the mp4 bit stream to VideoLLM inference by at least 2.5 times for hour-long video understanding (e.g 1024 frames) on a single 40GB GPU.
🤔What are the key challenges of hour-long video understanding?
1. Surprisingly long time (up to minutes) to decode thousands of frames directly from the mp4 bit stream, yet this is ignored by almost all previous works.
2. High memory bottleneck! Up to more than 100GB of activation memory from attention and MLP layers (even with flash attention) and more than 300GB KV cache memory for one million visual tokens from 1 hour video. (Analysis based on InternVL 2.5-8B)
3. The inherent high computation cost due to the quadratic nature of the attention mechanism.
🤩In QuickVideo, we solve it by:
1. ⚡QuickCodec: A brand-new video decoding library that decodes video blocks concurrently instead of sequentially with 2-3× speedup and exactly the same decoded frames.
2. 🧠QuickPrefill: A group-based video context prefilling strategy that reduces activation memory to less than 1GB and achieves 50% KV cache memory and computation reduction while preserving more than 97% accuracy on 4 long video understanding benchmarks!
3. ⚙️QuickVideo: Conducts video decoding and prefilling group by group in an interleaving way to avoid idle time of either CPU or GPU, reducing end-to-end time from 70 seconds to 20 seconds for a 30-minute video example on a single 40GB GPU!
📄 Paper: arxiv.org/abs/2505.16175
💻 Github: github.com/TIGER-AI-Lab/Q…
More insights: 👇
(0/5)

English
Yuxuan Zhang retweetledi

WikiGap: Promoting Epistemic Equity by Surfacing Knowledge Gaps Between English Wikipedia and other Language Editions. arxiv.org/abs/2505.24195
English
Retri3D: 3D Neural Graphics Representation Retrieval, ICLR 2025 Spotlight
gavinguan95.github.io/Retri3D/
#ICLR2025 #ICLR #NeRF
English
Yuxuan Zhang retweetledi

I'm super excited to share our recent work OmniEdit, an omnipotent editing model to handle all different types of editing requests including addition, removal, swapping, environment, background, style, etc. The best part is the **highest-quality** 1.2M high-resolution image editing dataset in huggingface.co/datasets/TIGER….
The biggest blocker in image editing is the lack of high-quality editing pairs. Most existing released datasets are highly noisy, low-resolution, with strong artifacts. This basically prohibits the progress in this area.
We spent **8 months** to experiment with many approaches to synthesize and filter clean image editing pairs. Eventually, we built seven specialized pipelines to propose massive amount of candidates and then prompt GPT-4o to assign quality scores these candidates. We took the highest-ranked candidates as our 1.2M training data.

English
Yuxuan Zhang retweetledi
Tired of writing academic papers or articles, struggling to find relevant papers to cite?
ScholarCopilot is here to help. It can help you autocomplete your writing, providing or suggesting relevant citations.
Try out our demo at huggingface.co/spaces/TIGER-L….
You can also set up your own demo with our Github code at github.com/TIGER-AI-Lab/S….
English

I was happy to add my name to this list of employees and alumni of AI companies. These signatories have better insight than almost anyone else into what is coming next with AI and we should heed their warnings.
Garrison Lovely is in SF@GarrisonLovely
110+ employees and alums of top-5 AI companies just published an open letter supporting SB 1047, aptly called the "world's most controversial AI bill." 3-dozen+ of these are current employees of companies opposing the bill. Check out my coverage of it in the @sfstandard 🧵
English
Yuxuan Zhang retweetledi

Yuxuan Zhang retweetledi

here is sora, our video generation model:
openai.com/sora
today we are starting red-teaming and offering access to a limited number of creators.
@_tim_brooks @billpeeb @model_mechanic are really incredible; amazing work by them and the team.
remarkable moment.
English