
Joseph
390 posts
Joseph
@RealJosephus
How dare I teach robots how to learn.
Katılım Temmuz 2017
9 Takip Edilen2.9K Takipçiler

@RealJosephus Harsh but fair on the image quality. The real question is whether native multimodal under one autoregressive objective is worth the tradeoffs. That's the actual experiment here.
English
Joseph retweetledi

We identified an issue with the Mamba-2 🐍 initialization in HuggingFace and FlashLinearAttention repository (dt_bias being incorrectly initialized).
This bug is related to 2 main issues:
1. init being incorrect (torch.ones) if Mamba-2 layers are used in isolation without the Mamba2ForCausalLM model class (this has been already fixed: github.com/fla-org/flash-…).
2. Skipping initialization due to meta device init for DTensors with FSDP-2 (github.com/fla-org/flash-… will fix this issue upon merging).
The difference is substantial. Mamba-2 seems to be quite sensitive to the initialization.
Check out our experiments at the 7B MoE scale: wandb.ai/mayank31398/ma…
Special thanks to @kevinyli_, @bharatrunwal2, @HanGuo97, @tri_dao and @_albertgu 🙏
Also thanks to @SonglinYang4 for quickly helping in merging the PR.
English
Joseph retweetledi

For people thinking that DeepSeek-OCR is the first model to render text as images, the University of Copenhagen already did this in 2023
Paper is called "Language Modelling with Pixels". They trained a Masked AutoEncoder (MAE) by rendering text as images and masking patches

English
Deepseek dropped the OCR model they trained last year. Against VL models, they highlight OCR; against OCRs, they highlight conv downsampling tokencount, yet more params.
Quite a scene watching people's reaction.
Model's only better than 0.9b paddle when it comes to math formulas.
Zephyr@zephyr_z9
Interesting Baidu has a better OCR than Whale
English
@teortaxesTex Gotta whisper this: under heavy data costs way > training, spectral norm is basically the worst you could do from a 2nd-moment view, no? Can't splash cash on data & defend burning it.
English

TM is quickly becoming the Western lab publishing what looks most like actual frontier research. One has to imagine from snide remarks that GDM/OAI/xAI are solving similar problems, by similar means.

Thinking Machines@thinkymachines
Efficient training of neural networks is difficult. Our second Connectionism post introduces Modular Manifolds, a theoretical step toward more stable and performant training by co-designing neural net optimizers with manifold constraints on weight matrices. thinkingmachines.ai/blog/modular-m… We explore a fundamental understanding of the geometry of neural network optimization.
English
@teortaxesTex For celebrity identification, it's pretty sure the model just learned about the name tags. It knows which face goes with which name, but it doesn't actually know who the person is. Typical Qwen superficial work.

English
Qwen never beating the allegations
But I think it's both seen the test set and everything else
As I've said, Qwen has cracked the secret: pretraining on *all test sets, including future ones*, is all you need. Good procedural data goes a long way

English
and... if you see an increasing percentage of ex-CV researchers joining your team, that's a major red flag.
x.com/RealJosephus/s…
Joseph@RealJosephus
Honestly, it's sickening to see people with no linguistics background pontificating on the future of LLMs, or those with no neuroscience background holding forth on AI and AGI as if they're experts.
English
We're entering an age where upstream compute will eclipse the pretraining itself. Most aren't prepared. Let alone the fact that some of the biggest labs can't even produce a snapshot of the "entire web" up to a recent date. That's definitively 2 versions out of date.
English

@ChaseBrowe32432 Yeah just read it carefully
search is clearly the second of their major priorities in this cycle
English

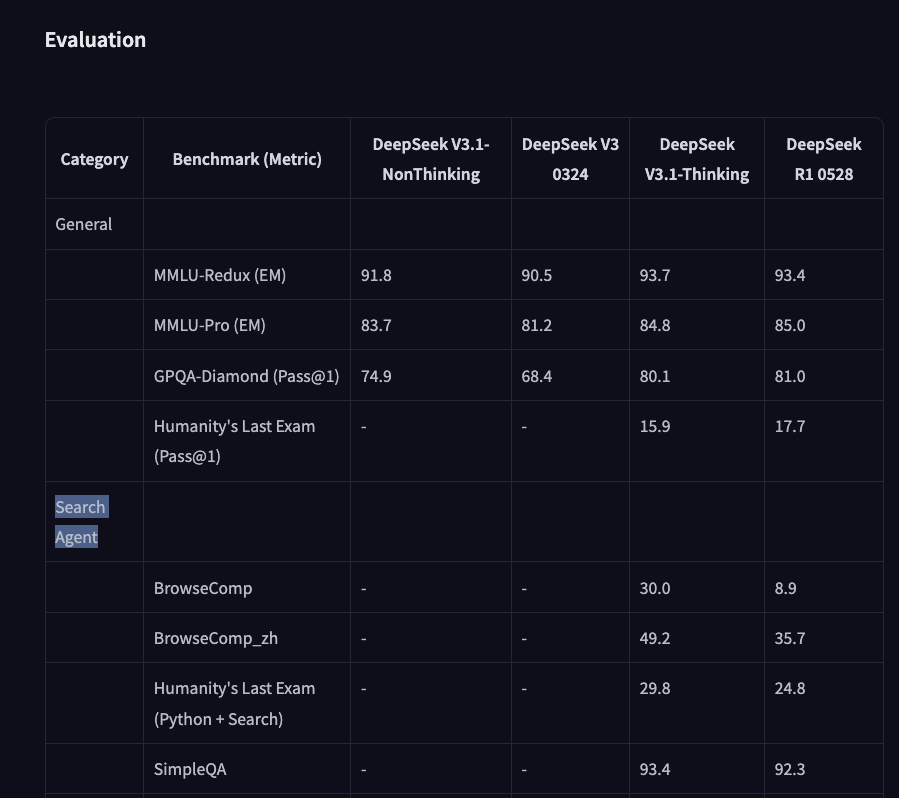
Anyone know what's going on with the simpleqa score here? R1-0528 was previously reported at 27.8, and 93.4 is.... somewhat absurd
Can't seem to find any methodology explanation, and the same number is reported on hf

DeepSeek@deepseek_ai
Tools & Agents Upgrades 🧰 📈 Better results on SWE / Terminal-Bench 🔍 Stronger multi-step reasoning for complex search tasks ⚡️ Big gains in thinking efficiency 3/5
English

The CCP forced Whale to use Huawei Ascend chips is catnip.
It explains everything, why are they taking so long, cause Ascend chips.
Why are they not publishing new research, cause Ascend chips.
They are spending so much time getting chips to work, they can barely focus on anything.
Perfect catnip.
English
@RealJosephus Speculating or you saw something.
He is posting images, so it's not a VL like I thought but an image model.
English
If it messes up the order, chances are it has conflicting information from a bad update (like new wiki data layered on old data).
If it gets it right, its knowledge is current as of late 2024.
If its answer is old (from before 2023), its knowledge probably cuts off in 2022.
English

Qwen3-Coder-480B-A35B-Instruct
1M ctx, but... cutoff 2022
Casper Hansen@casper_hansen_
if you loved kimi k2, you will love what a certain chinese team is about to release which is highly competitive with 1M context length
English



@teortaxesTex nay, garbage 'audio head parallel decoder' with ~1T tokens wasted.
see: huggingface.co/moonshotai/Kim…
might be a peculiar curse, but all the models with this architecture that I've observed have been poorly trained...

English
>13 Million hours of diverse audio data (speech, music, sounds)
Another banger model and report from Kimi, and even
> open-source evaluation toolkit for audio founda-
tion models
and for once nobody to steal their thunder!
based on Qwen 2.5-7B and Whisper
Kimi.ai@Kimi_Moonshot
Announcing 🎙️ Kimi-Audio! Our new open-source audio foundation model advances capabilities in audio understanding, generation, and conversation. Key Features & Achievements: ✅ Universal audio foundation model handles diverse tasks like speech recognition, audio understanding, audio-to-text chat, speech-to-speech conversation. ✅ Large-scale pre-training on >13 Million hours of diverse audio data (speech, music, sounds). ✅ Unique 12.5Hz tokenizer & hybrid architecture for rich perception and efficient generation. ✅ SOTA on 10+ audio benchmarks: excels in Speech Recognition (LibriSpeech 1.28/2.42 WER), Audio Understanding (MMAU, VocalSound), and Conversation (VoiceBench). We're also releasing our comprehensive evaluation toolkit to foster fair benchmarking! 🛠️ 📄Dive into the details in our Technical Report: github.com/MoonshotAI/Kim… 🌟Explore the Code, Models & Eval Toolkit on GitHub: github.com/MoonshotAI/Kim… HuggingFace: huggingface.co/moonshotai/Kim… Excited to see the innovative audio applications the community will build!
English
now it also applies to inference, tokenizers...
Know your inference - vllm, *.cpp, ggml, hf? Everyone believes their inference implementation is correct. Verify it yourself. Otherwise, you're no different from someone who types `ollama run deepseek-r1`.
x.com/RealJosephus/s…
Joseph@RealJosephus
This suggests that, in reality, NO 'serious' LLM training is actually centered around the Hugging Face ecosystem - many who claim to surpass Meta LLaMA3.1, don't even know how to train a model properly - script kiddies
English