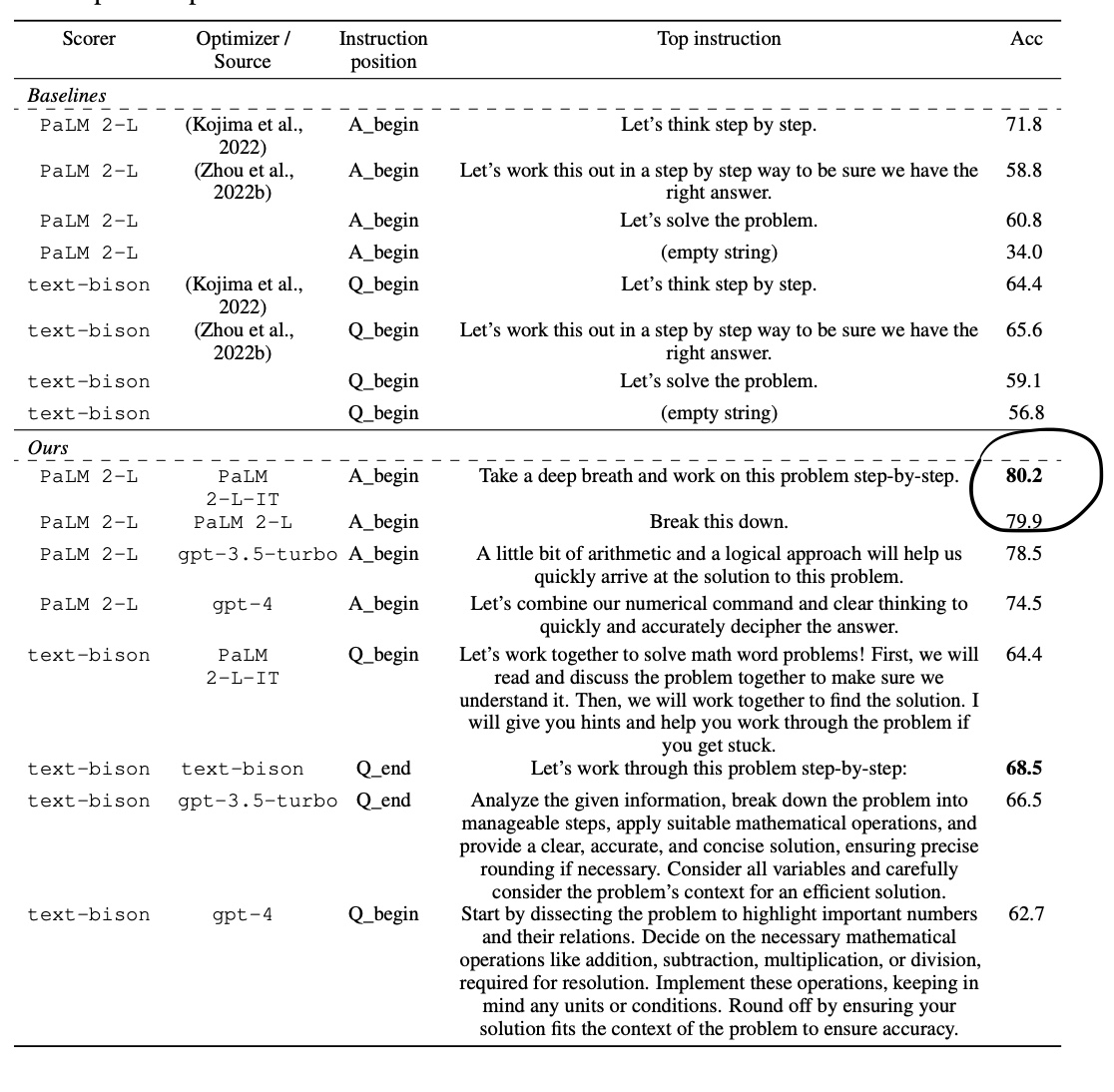
Roberto Musso retweetledi

Extraordinary. We are stardust.
Asteroid Bennu contain all 5 of nucleobases that form DNA and RNA on Earth and 14 of 20 amino acids found in living organisms (though Bennu contains equal amounts of these structures and their right-handed counterparts). nature.com/articles/s4155…
English