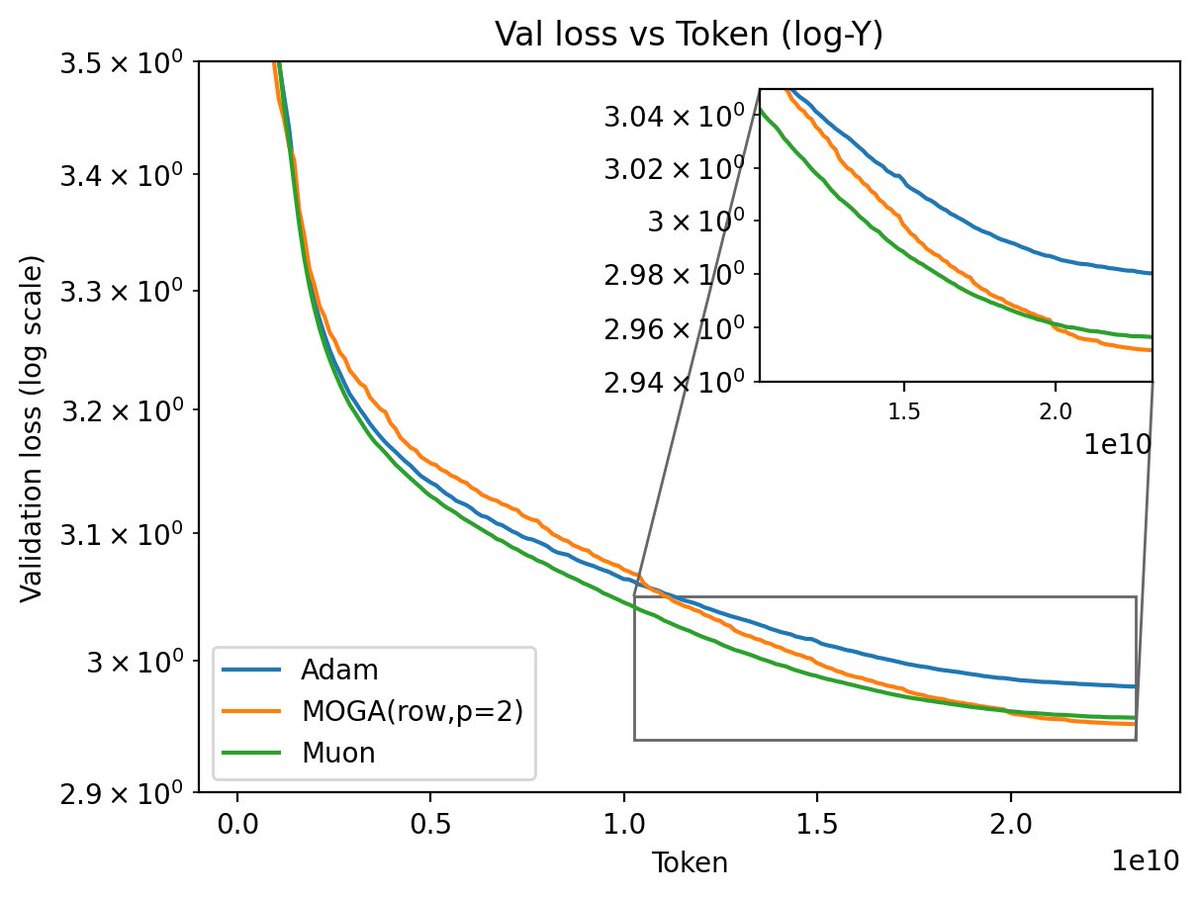
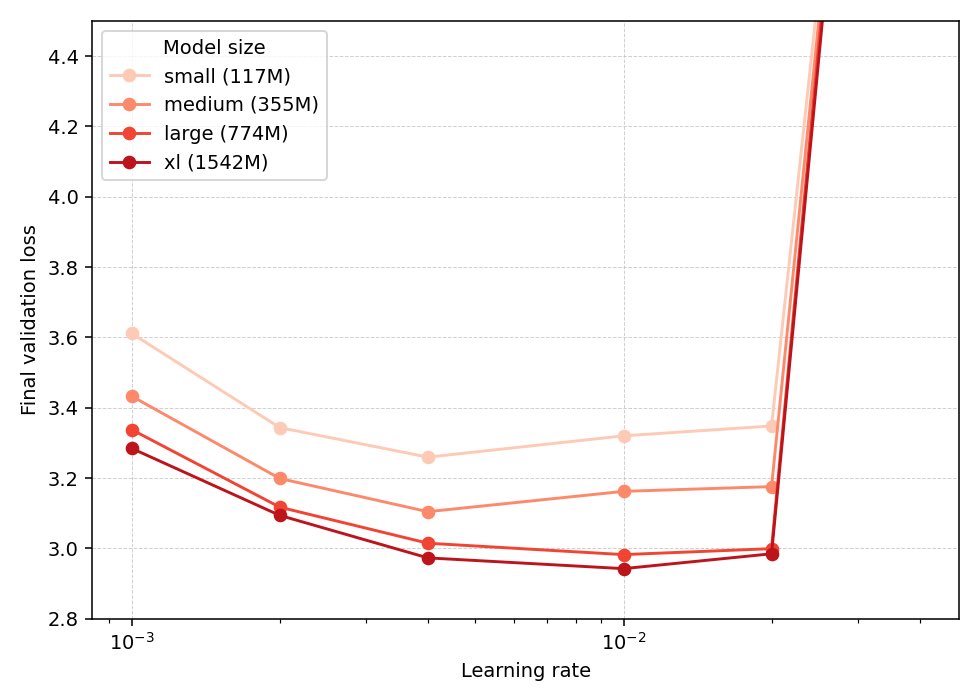
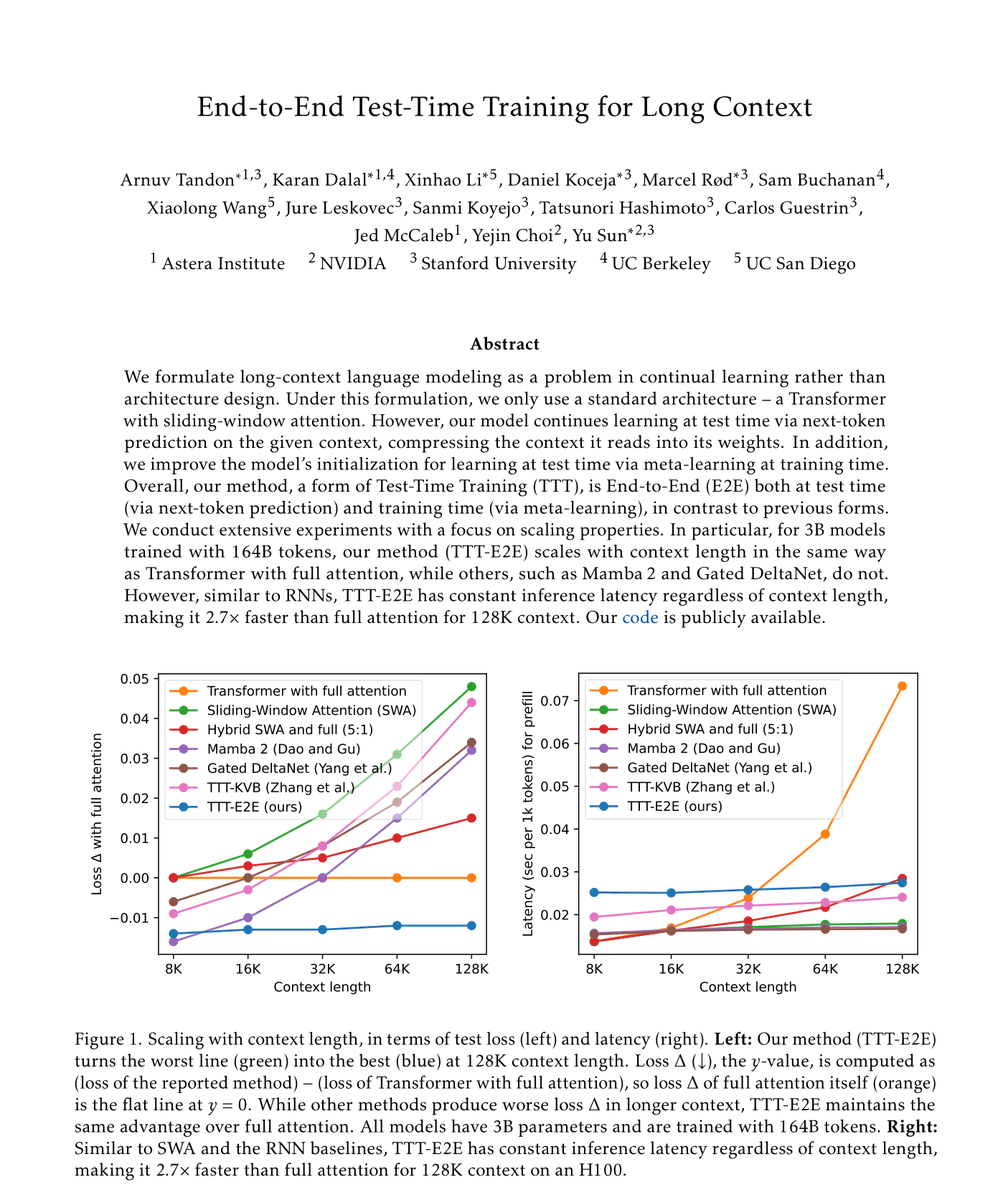
Sabitlenmiş Tweet

#ICLR2023 New paper!
"Rethinking the expressive power of GNNs via graph biconnectivity" accepted as an 𝗼𝗿𝗮𝗹 𝗽𝗿𝗲𝘀𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 (notable-top 5%)
🔥A new direction to study GNN expressivity via graph biconnectivity!
👇Let's see the details of our fruitful results🤗
Bohang Zhang @ICLR 2024@bohang_zhang
Excited to see our paper "Rethinking the expressive power of GNNs via graph biconnectivity" accepted as an 𝗼𝗿𝗮𝗹 𝗽𝗿𝗲𝘀𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 (notable-top 5%) at #ICLR2023! arxiv.org/abs/2301.09505 Joint work with @Roger98079446, Liwei Wang, and Di He 1/n
English