Sabitlenmiş Tweet
Rupesh
385 posts

Rupesh
@Rupeshkrj2
SWE @LinkedIn || Ex-SDE2 @_groww || EX-GSOC || A Full stack dev who loves Distributed Systems https://t.co/5nos0CDOkC
Bangalore Katılım Nisan 2018
596 Takip Edilen168 Takipçiler
Rupesh retweetledi


@__alter123 @Tweetbyjagan @SumitM_X You dont need to worry about data loss and sharing data over network, and how big is the file.
English

@Tweetbyjagan @SumitM_X what makes S3 more efficient compared to direct transfer?
English

There must be chad level practice as well behind this.. op confidence on skills.. 🫡🫡
RVCJ Media@RVCJ_FB
Absolutely Chad Behaviour 🗿
English
Rupesh retweetledi

75% of developers will fail this SQL question.
What's wrong with this script?
The first time I faced this question, I jumped into the SQL syntax like crazy.
But the syntax was OK; the problem was in the data and related to a concept called Cardinality.
Cardinality refers to the number of unique values in a column relative to a table's total number of rows.
• High Cardinality means the column has many unique values.
• Low Cardinality means the column has few unique values.
Creating an index on a column with low Cardinality is most of the time ineffective because:
1. Low Cardinality means each indexed value points to many rows, reducing the index's ability to narrow down the search.
2. Maintaining an index has a cost of storage and update time. For low cardinality columns, this overhead might outweigh the benefits.
3. Database query optimizers are smart; they know column statistics, including Cardinality. When they detect a low cardinality index, they often ignore it and perform a full table scan instead.
A simple Example
Consider a table "Employees" with 1 million records.
Let's examine indexing on different columns:
• ID: High Cardinality (1 million unique values). An index here would be very effective.
• Name: High Cardinality (many unique names). An index could be helpful in searches.
• Department: Medium Cardinality (10-20 unique values). An index might sometimes be useful but less effective than an ID or Name.
• Gender: Very low cardinality (2-3 unique values). The query optimizer would likely ignore an index here.
When to consider a Low Cardinality column?
There are scenarios where indexing a low cardinality column might be beneficial.
For example, combining low and high cardinality columns can be effective.
'CREATE INDEX idx_dept_emp ON Employees(Department, ID);'
Now you know the basics about Cardinality!
Save this post; it might help in your next interview.

English
Rupesh retweetledi

@pankaj013 @Franc0Fernand0 "I have failed more times than you have tried"; So I can deduct the failure patterns quickly.
English
Rupesh retweetledi

Rupesh retweetledi

Rupesh retweetledi

I am thrilled to announce that @ManningBooks has decided to publish Thinking in Distributed Systems
Writing this book was challenging but rewarding. Your support, your feedback and comments kept me motivated throughout.
Thank you ❤️

English
Rupesh retweetledi



Who said mutual funds don't make money?
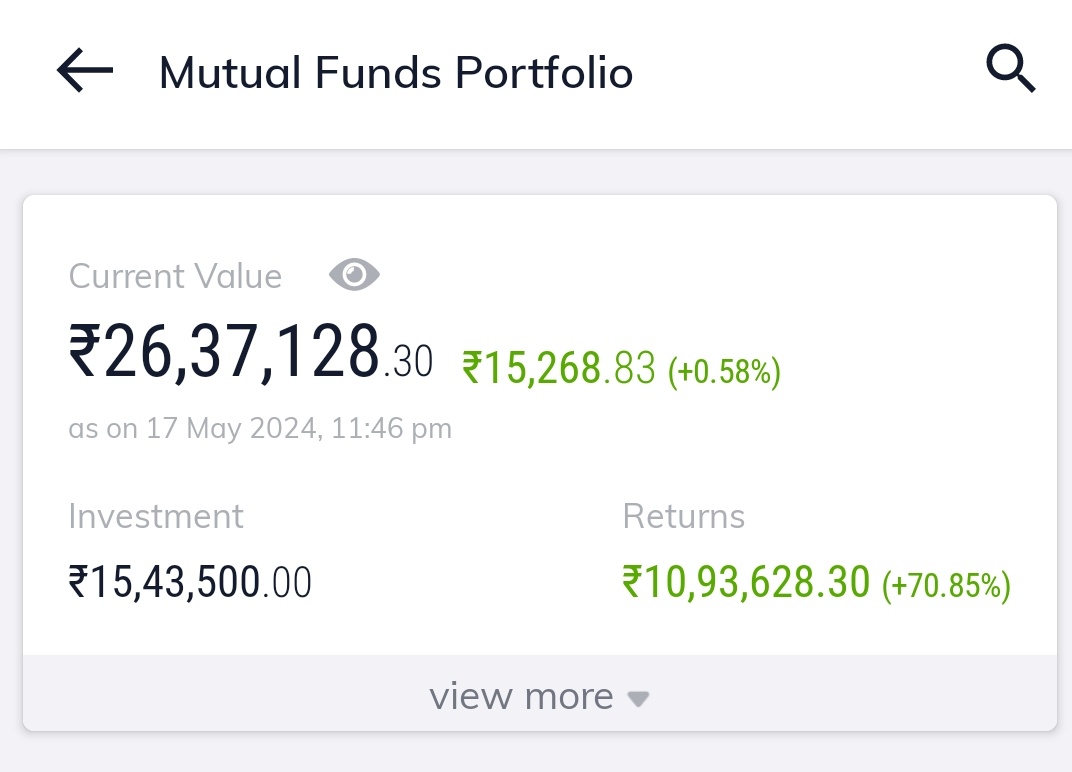
Ashish Jha@the_dream_saver
Who said mutual funds SIPs don't make money?
English
Rupesh retweetledi

@ProgressiveCod2 Have one doubt - what if the concurrent code is running on multi-core processor, then that will be treated as parallelism right ? Because cpu have the capability to handle the things seperately..
English

Concurrency & Parallelism are two terms that always create some confusion.
Here's how I try to understand them:
👉 Concurrency means more than one task can appear to make progress over a unit of time.
The key term over here is "APPEAR".
Concurrency gives the illusion that the tasks are running at the same time.
In reality, the processor is switching between different tasks.
👉 Parallelism is when two or more tasks actually make progress at the same time.
The key word is "ACTUALLY"
For parallelism, you need to have more than one processor or a multi-core processor.
Multiple tasks can make progress at the same exact time.
But that's not all.
In reality, tasks can be executed in several ways:
- Sequential
- Concurrent
- Parallel
- Parallel & Concurrent
👉 A few important points to remember:
[1] Concurrency is about dealing with lots of things at once.
[2] Parallelism is actually doing lots of things at once
[3] The application can be concurrent but not parallel.
[4] The application can also be parallel but not concurrent
[5] All parallel executions need not be concurrent
👉 So - what are your views about parallelism and concurrency?
Do you think there are more differences between the two?
GIF
English

How GitHub manages their databases in production? ⚡
Database outages are more common than we think, so what happens when the master goes down? how a replica is chosen and promoted to be the new master? Is this automated or done manually?
GitHub published a blog talking about the tooling they use to get an optimal DB performance and High Availability and I dissected it to and compiled my learnings in a video.
give it a watch - youtu.be/4mVJQJbw6Vw
⚡ I keep writing and sharing my practical experience and learnings every day, so if you resonate then follow along. I keep it no fluff.
youtube.com/c/ArpitBhayani
#AsliEngineering #SystemDesign #DatabaseEngineering

YouTube

English
@arpit_bhayani Had experience exactly same issue in past but the root cause was something diff.. how we handled is took downtime of 5 mins and closed the requests coming on db from gateway for that interval and then manually up the master.. and then enabled gateway.. and it worked likr charm 😅
English
@arpit_bhayani @kritikatwtss Agreed!! To scale write you need partiotining and sharding depending on the use case, @arpit_bhayani has explained this in one of his video as well, you can refer that!
English
this is incorrect. master will "only" accept write is wrong.
writes and critical reads will go to the master. the reads that need a consistent view of the data need to go to the master. there is no way out.
also, to scale writes beyond a single machine you need to partition the data and distribute the ownership across.
English

From Alex's system design interview book:
Database replication: use master-slave architecture
master will only accept write operations, whereas the slave will have read operations (read-only).
Since most of the applications are read-heavy we have more slave nodes than master nodes.
But what if the write operation is heavy for the application? How do we take care of this?
English

