Sabitlenmiş Tweet
Mr Q
99 posts


Mr Q
@SW_Quigley
Serial entrepreneur, 3 exits. Founder @ Platform Q AI. Chair @ SHIFT Marketplace. Forbes Council. Building the future of AI agents.
UK Katılım Ağustos 2024
263 Takip Edilen21 Takipçiler

I still believe MoEs with cpu offloading can be competitive and bring down costs tremendously.
I hit a wall with my testing, mainly:
How can you predict which experts are going to be active given a prompt’s trajectory?
Anyone interested in digging into this more? Shoot a plan
witcheer ☯︎@witcheer
MoE vs dense offload on 8GB VRAM MoE offload is 10.8x faster than dense offload on 8GB VRAM. here's the proof. I tested Qwen3.6 35B A3B (MoE, 3B active) vs Qwen3.6 27B (dense, 27B active) on my RTX 4060 Ti 8GB. the numbers: >MoE (-ncmoe 30): 35.4 tok/s >dense (-ngl 20): 3.28 tok/s ratio: 10.8x it gets worse at longer context. at 24K tokens, the gap is 16.7x. MoE has zero context degradation (SSM layers), dense loses -35.4%. why: MoE expert offload keeps the hot path (3B active params) entirely in VRAM. only inactive experts move to CPU when selected. dense layer offload splits every layer across GPU and CPU. every token bounces through PCIe for all 64 layers. the bandwidth bottleneck is fatal. quality is slightly better on dense (5/6 vs 4/6). the 27B model has the best hallucination resistance of all 9 models I tested. if you have 8GB VRAM and a model that doesn't fit: MoE with expert offload, not dense with layer offload.
English
@AtlasInference @spark_arena Best I've had is 100 TPS out of vLLM. Will give this a try!
English

DGX Spark just benched 200+ tok/s for Qwen3.6-35B with @AtlasInference on @spark_arena 🔥
How's that possible? Providers like Codex and Claude get ~60. Other major engines don't come close 🦥
We haven't seen speeds like this on GB10. NO ONE HAS. Atlas is shattering records 🚀
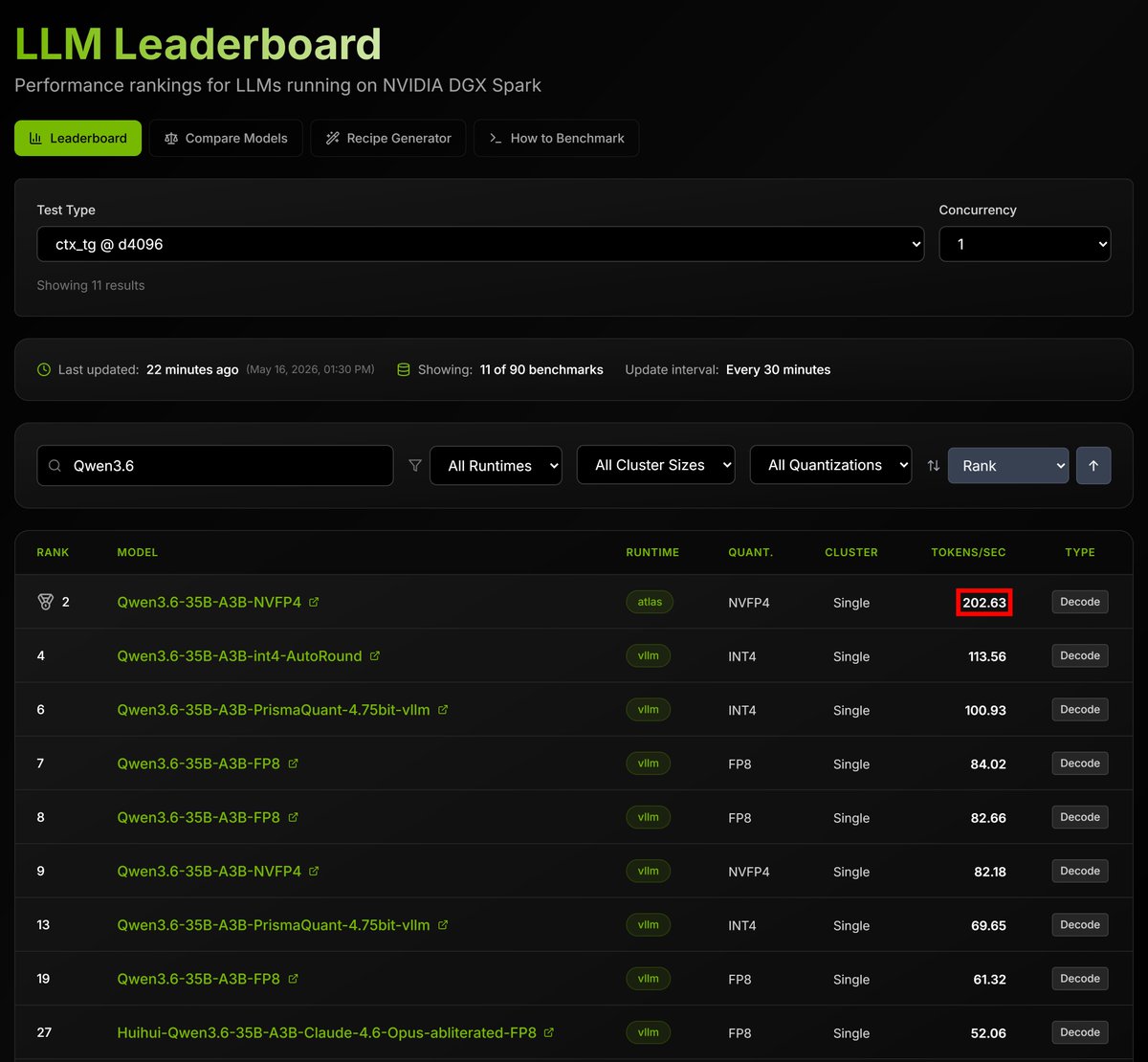
English
@badlogicgames @FrameworkPuter @antirez Don't need to bastardise anything, the ds4 q2 model he shared runs on a couple of llama.cpp images well 👍🏼
English

thanks @FrameworkPuter for this wonderful gift. i'll report back once i've set it all up and bastardized @antirez 's ds4.c enough to run on this beautiful piece of hardware.

English
Yeah it's horrendous. Opencode is just as bad, great UX but memory leaks all over the codebase. Spent 2 weeks patching them because they hit 50GB ram consumption but on a two day session each instance was still around 8GB.
I love Pi.dev but the problem isn't much better because of node. So I rebuilt Pi in rust and it consumes 4mb of ram headless and 8mb total with a rust TUI.
It can then replicate itself and spin up 20 sub agents and it's still only consuming less than 200mb!
English

My Mac had less available memory than I expected, turned out the "claude" Claude Code processes on this machine (running in various terminal windows) were consuming ~30GB on their own!
The largest one was using 4.9GB
English

update: qwen 3.6 27b dense q4 just one shotted octopus invaders game on a single 3090. hermes agent drove the whole thing, ~41 tok/s gen 21gb vram at full 262k context, thinking mode on.
one prompt in and the canonical multi-file space shooter benchmark out, the same exact prompt i ran on qwen 3.5 27b dense back in march on the same card.
3.5 needed one external scope bug fix before the game would even load on first play. 3.6 needed nothing. 11 of 11 files written, 2411 lines of code, zero steering interventions, zero external fixes, playable on first load. 16 minutes 41 seconds wall clock from prompt to playable.
consumer tier king on a single 3090 is locked tonight, and the silicon underneath my desk did not change between march and now. the open source ecosystem just moved the floor.
watch it ship itself, the full 16 minutes 41 seconds sped to 3 minutes 45, no human touched the keyboard between the first prompt and the final frame.
Sudo su@sudoingX
this is what my setup looks like today. about to test qwen 3.6 27b dense q4 on a single rtx 3090 at ~41 tok/s gen, hermes agent driving. predecessor model qwen 3.5 dense q4 made it work in one iteration when i ran the same agentic build on the same card. i've been daily driving qwen 3.6 27b dense for weeks now, the model i keep coming back to. if 3.6 oneshots too, this becomes the best model that runs on a single rtx 3090. consumer tier king. firing the test now will report back soon.
English

DS4 running on DGX Spark (GB10 / CUDA), private branch for now. 12 tokens/sec, the memory bandwidth is limited in this system, at 270GB/sec. But prefill is ways more alighed to M3 Max at ~200 t/s. I'll release when more mature, but it is almost sure that it will get merged.
English
@EdinburghLive_ Who writes this garbage? Sifting through ads like a crack head in a bin to reveal zero detail. Pathetic journalism.
English

Moment Edinburgh car bursts into flames on major city centre road as smoke plumes
edinburghlive.co.uk/news/edinburgh…
edinburghlive.co.uk/news/edinburgh…
English
@SchmidhuberAI @ylecun Why do you never respond to these? You take great pleasure in responding to Musks posts!?!
English

Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14].
Details in reference [19] which contains many additional references.
Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts."
The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task.
The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19].
Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]).
The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post).
Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8].
In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19].
FOOTNOTES
1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1].
2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3].
3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8].
4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16].
REFERENCES (easy to find on the web):
[1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): people.idsia.ch/~juergen/predm…
[2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto.
[3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991.
[4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786.
[5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015.
[6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23.
[7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute.
[8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26.
[9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?)
[10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733
[11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25.
[12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25.
[13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279
[14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM.
[16] JS (1990-2026). AI Blog.
[17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024.
[18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025.
[19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. people.idsia.ch/~juergen/who-i…

English
Mr Q retweetledi

Scam Altman and Greg Stockman stole a charity. Full stop.
Greg got tens of billions of stock for himself and Scam got dozens of OpenAI side deals with a piece of the action for himself, Y Combinator style. After this lawsuit, Scam will also be awarded tens of billions in stock directly.
The fundamental question is simply this:
Do you want to set legal precedent in the United States that it is ok to loot a charity? If so, you undermine all charitable giving in the United States forever.
I could have started OpenAI as a for-profit corporation. Instead, I started it, funded it, recruited critical talent and taught them everything I know about how to make a startup successful FOR THE PUBLIC GOOD.
Then they stole the charity.
X Freeze@XFreeze
Interesting how it works Elon puts up his own money, rounds up the absolute best AI talent on the planet, leverages every connection he has to secure serious resources, and launches OpenAI in 2015 as a pure non-profit explicitly created to develop AI for the benefit of humanity, with zero profit motive and open research Then the “team” decides they want the bag They push Elon out, take control, and quietly flip the entire thing into a for-profit machine All while preaching the same sanctimonious lines on repeat: “We’re still mission-driven!” “AI for the good of humanity!” “We’d never abandon our principles!” The ultimate betrayal: Elon got zero equity. Not a single share. He funded it. He built the foundation. He got nothing while they turned his non-profit into their personal cash cow This is the level of betrayal and hypocrisy we’re dealing with And for the record.... this lawsuit doesn’t put a single penny in Elon’s pocket. Any win goes straight back to the non-profit to restore the exact mission he founded
English
I'm sorry but Macs just aren't the right solution. Your articles is a series of workarounds that half work. And MacOS will still randomly change permission levels for SSH and similar remote access tools which means you can be locked out of the machine at any moment. Linux is a far superior solution. And for the record I own a DGX Spark, a Linux K8S cluster and a Mac Studio, so I learnt the truth the painful way.
English


Claude Design is here powered by Opus 4.7
this is killing thousands of startups..
Claude@claudeai
Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude. Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
English

English

@honestduane @AnthropicAI This was API key and first-party usage via claude cli. They reverted quickly.
English
Yeah folks, it's gonna be harder in the future to ensure OpenClaw still works with Anthropic models.

English
@BladeoftheS There you are standing with your hand out, you flying cunt.
English

The Green Party is the only major Party in England actually offering anything.
All the other parties just say 'There's no money'.
Don't vote for that shit.
English

I have returned from 2035 and interviewed some Zero-Human Company founders and they all look and sound like this when they talk about AI and how they fit in.
English
@TheBlackTiger03 @Nigel_Farage Its a charity like St Johns Ambulance you fucking moron.
English

He’s 💯 CORRECT
Jews have their own Ambulances, whilst it takes 8 hours for a normal ambulance to reach everyday British people...
If Muslims had their own police force, hospitals and ambulances, then there would be outrage.
Why the double standard?
Why do Jews get special treatment?
English

There is now a terror cell in north London.
The fifth column is here.
English
Mr Q retweetledi

opencode 1.3.0 will no longer autoload the claude max plugin
we did our best to convince anthropic to support developer choice but they sent lawyers
it's your right to access services however you wish but it is also their right to block whoever they want
we can't maintain an official plugin so it's been removed from github and marked deprecated on npm
appreciate our partners at openai, github and gitlab who are going the other direction and supporting developer freedom
English