
@erikdunteman The second you find yourself switching away to another medium to do the work, your agent has a capability gap.
English
Sam Partee
1.4K posts

@SamPartee
CTO, Co-Founder, @tryArcade | @redisinc @HPE_Cray | AI, LLM, Python, HPC, ⚾️ fan, roll tide | Blog: https://t.co/PJfL2cMCYD | Opinions are my own.

I've spent the month handcoding pretty much everything, and the brain atrophy has finally lifted. The deep joy I once felt is back.




Everyone at Sierra uses an internal agent called Pinecone to automate 90% of our coding, analytics, and busywork. I can't go back to any other way of working. Pinecone: * Runs an agentic harness in our internal cloud. * Talks to all our tools (Slack, Github, Linear, GSuite, Clickhouse, Gong, etc.) * Lets you pick any model. Especially useful this week! * Can spin up a local version of all of Sierra to test its work. * Is accessible over mobile, Slack, Github, and Web and is collaborative. @neilrahilly and team cooked on this. In this post, they share lessons learned from building and scaling Pinecone to the whole company.

Bring your hot takes and your drop shots.🔥 Next week, we're co-hosting The Agent Open: an afternoon of pickleball, food, drinks, and industry-leading speakers who ace their code and commit to their serves. 🏓 Catch our co-founder and CEO, Jerry Liu after Day 2 of AIE World's Fair on a panel moderated by Gergely Orosz (𝘛𝘩𝘦 𝘗𝘳𝘢𝘨𝘮𝘢𝘵𝘪𝘤 𝘌𝘯𝘨𝘪𝘯𝘦𝘦𝘳). Get ready for a real conversation about the Future of AI and learn how to avoid the hype, stay out of the kitchen, and strategically position your team for what's next. 🗓️ Tuesday, June 30th @ 5:00pm PT 📍 San Francisco (register for the address) 🦙 Co-hosted by LlamaIndex with Braintrust, turbopuffer, Cursor, Parallel Web Systems, Modal, and Browserbase Come for the panel, stay for the championship rounds. RSVP: luma.com/the-agent-open… #AIEngineering #AIAgents #DocumentAI

As your bm25 guy its on brand to tell you all that i'm going to ai engineer world's fair to talk about bm25








i reverse engineered 82-0.com to figure out how to draft the perfect team results: 82-0.vercel.app
⚙️ Building the infrastructure layer for #AI agents? Don’t miss Sam Partee, CTO and co-founder of Arcade.dev, as he takes the keynote stage at #MCPDevSummit Bengaluru, 9-10 June. Sam brings a practical perspective on what it takes to power the next generation of agentic systems. 🎟️ Register today and join us! bit.ly/4t1Dica


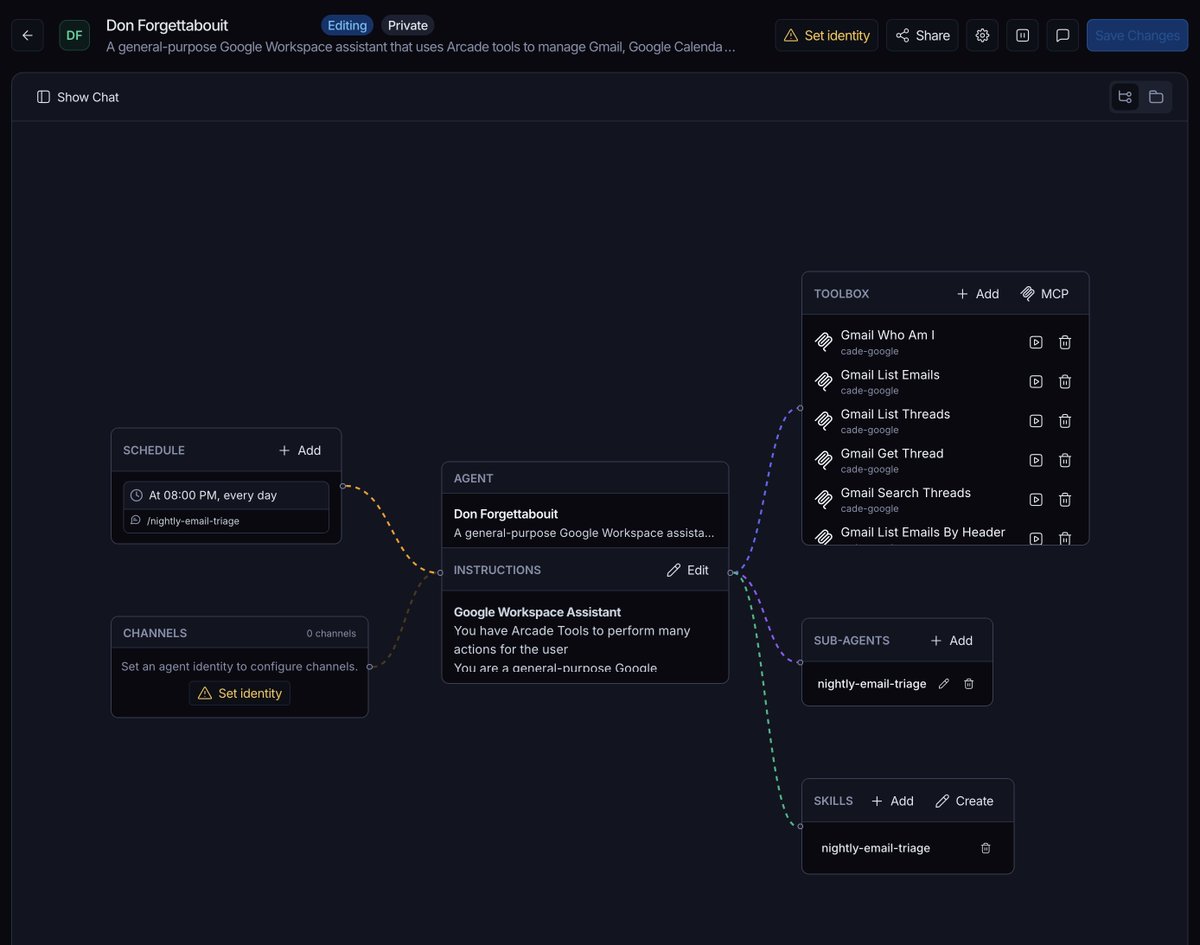

your agent's memory shouldn't live on someone else's computer. today @TryArcade is open-sourcing Agent Library: your agent's entire memory in one SQLite file you can copy, diff, or email to yourself. Apache 2.0. no account. no hosted service. github.com/arcadeai/agent…


