
Sam Acquaviva
73 posts

Sam Acquaviva
@Sam_Acqua
now @ after thought, ex-cocosci @ mit
Katılım Şubat 2014
380 Takip Edilen361 Takipçiler

The dead neurons problem is real fs. The Forster isotropy/alternating projection algorithm they use to ask for the row norms to be exactly n/m I don’t think is correct because it’s too prescriptive and you start to see diminishing overall progress. I think better solutions if one wants to go down this route specifically are to approximately setup proximal/regularized updates which JUST try to enforce no row norms is too small (proximal style updates are reasonable to setup here I think of similar iteration complexity as aurora’s inner update) rather than all are equal.
English
Muon and Shampoo for attention layers are usually applied separately for each head. For Shampoo at least, even the original paper describes the tensor flattening version for higher rank tensors which unless I’m mistaken is different than doing it for each head separately. Wondering if people have tried the higher rank version instead of doing it for each head separately and wonder how it performs hmmm
English
@_TarunKathuria re: "I don’t think Aurora is a great solution for a variety of reasons" can you say more? I'm curious
English
Yeah I think ChatGPT gave me this paired head reference as well. That’s a good point and I think methods for better non square Muon-ish is definitely worth exploring! In general I don’t think Aurora is a great solution for a variety of reasons but definitely worth checking for sure!
English
Great work from Oscar on scaling up flow models!
Oscar Davis@osclsd
🚨 Before concluding: As noted by @Sam_Acqua and many others, we all ought to be very skeptical of Gen PPL as a metric, especially in isolation. ❌ It is actually a bit crazy that we have been using it for so long. Hence, the additional metrics, and the presence of several qualitative samples in the appendix. Please have a look yourselves to get a better understanding of the sample quality! 🔍 There's comparisons across SD/non-SD, number of NFEs, and others.
English
The grad moment metric addresses the "no measure of inter-sample diversity" point, but it still has some of the same flaws:
1. still sensitive to sample entropy / slight differences in sampling (but it is *less* sensitive)
2. still treating gpt2 as oracle
and new issue is that it is much less interpretable. I still think val ppl bounds like langflow are the way forward even though they are relatively expensive. Compared to training the model it is negligible.
English
@emiel_hoogeboom Very cool! I feel like its best to also standardize # NFEs to make comparison easier, given that comparing 1024 NFEs vs 4 NFEs is a bit unfair.
Fully agreed re: entropy-matched gen ppl is still very flawed. gpt2 grad moment is an interesting idea
English
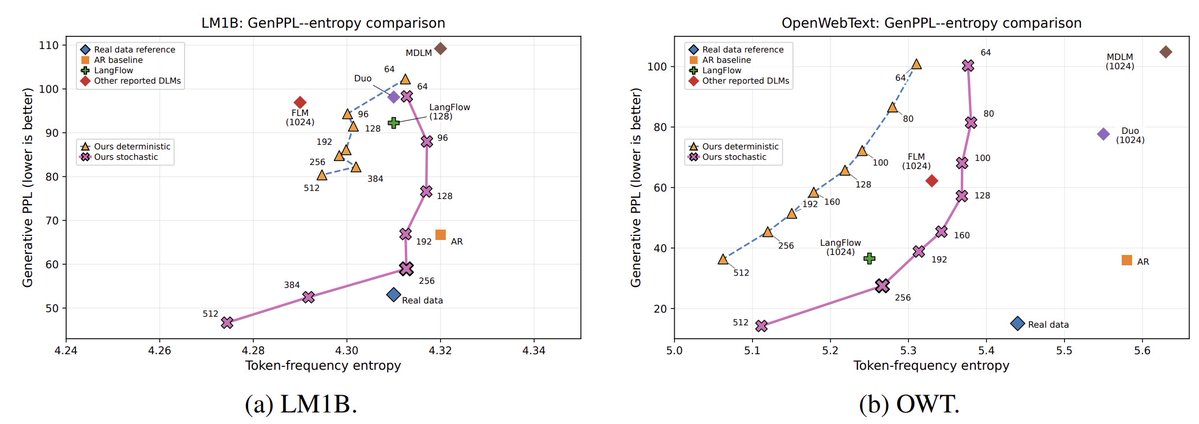
Flow models are a promising alternative to autoregression. But the current standard of evaluating flow models is broken.
The reported 3x improvement in 1024-step PPL since 2023 is closer to 1.1x if you control for sample entropy.
(1/12)
English

Great insight from After Thought researcher @Sam_Acqua
Sander Dieleman@sedielem
I'm going to re-retweet this, because it's important! There are a few pitfalls when evaluating diffusion language models, highlighted in these two recent blog posts: - patrickpynadath1.github.io/blog/eval_meth… - samacquaviva.com/projects/flow-… Both are worth a read if you have an interest in this space!
English

A fun experiment comparing a random step with one gradient step:
With a small CNN on CIFAR-10, a random step is basically a disaster. (A gradient step is a ~185σ event.)
That makes sense if you expect a random direction in R^d to be ~sqrt(d) standard deviations worse than the optimal one. So scaling up to a larger model should make things even worse.
But with a 7B model (test on GSM8k), random steps have a good chance of outperforming a gradient step.
(The gradient norm of one PPO update is 1.94, while the L2 norm of the Gaussian perturbation is 85.6. The figure below rescales the Gaussian perturbation to match the PPO update norm, so the random step and gradient step have the same radius.)
We should really rethink the parameter-function map.
GIF
English

I'm going to re-retweet this, because it's important!
There are a few pitfalls when evaluating diffusion language models, highlighted in these two recent blog posts:
- patrickpynadath1.github.io/blog/eval_meth…
- samacquaviva.com/projects/flow-…
Both are worth a read if you have an interest in this space!
Sam Acquaviva@Sam_Acqua
Flow models are a promising alternative to autoregression. But the current standard of evaluating flow models is broken. The reported 3x improvement in 1024-step PPL since 2023 is closer to 1.1x if you control for sample entropy. (1/12)
English
@Clashluke I mean the best would be domain expert + something like HEBO right? But obv it's a pain to define the joint prior distribution.
Second best being autoresearch + HEBO like arxiv.org/html/2603.2464…, maybe best if SOTA = on pareto of human researcher v. loss
English

What’s the SOTA hyperparameter optimizer?
Specifically, modded-nanogpt needs wide hyperparameter ranges (some optimizers need LR=100, while others need 1e-6), while HEBO, PROTEIN, TuRBO, BOHB, HyperBand, SHA, CMA-ES, and TPE fail to converge in this setting.
English
@giladturok DUEL is awesome I reference it all the time. I didn’t mention it because I only referenced diffusions that were cited in flow model papers. But I’ll add a note about it once I have time :)
English

May I humbly suggest to check out our method DUEL for proper evaluation of masked diffusion language models (link below)!
DUEL computes the exact likelihood, not an ELBO, for *deterministic* sampling strategies (e.g. confidence threshold)! No need for gen ppl & entropy!
Sam Acquaviva@Sam_Acqua
Flow models are a promising alternative to autoregression. But the current standard of evaluating flow models is broken. The reported 3x improvement in 1024-step PPL since 2023 is closer to 1.1x if you control for sample entropy. (1/12)
English
@jwthickstun @Chramblin @nmboffi @ReeceShuttle @akshayvegesna Interesting idea! I haven't seen Mauve before -- I'd have to look closer before giving any useful response.
Thanks for reading :) I'll reply once I have time to check it out
English

@Sam_Acqua @Chramblin @nmboffi @ReeceShuttle @akshayvegesna What do you think of Mauve as a metric in this setting? Using a good embedding model, not GPT2...
English

I am thinking to work on a paper to introduce a new metrics and benchmarks.
Pareto fronteers are a good fix but it is not enough
Would you and @PatrickPyn35903 be interested in brainstorming with me and my group for this?
This is the sort of thing that benefits from collaborations
English
This is extremely important for anyone interested in language diffusion.
We need better metric to move forward!
Sam Acquaviva@Sam_Acqua
Flow models are a promising alternative to autoregression. But the current standard of evaluating flow models is broken. The reported 3x improvement in 1024-step PPL since 2023 is closer to 1.1x if you control for sample entropy. (1/12)
English
@LucaAmb I will add this when I have time! Thanks for reading :)
English
@Sam_Acqua Then maybe you should discuss our paper, where it is possible to evaluate ;)
arxiv.org/abs/2605.07013
English


@Sam_Acqua I think I have something you will like coming out soon
English
@LiDavid2002 Fully agree on all accounts!
So when ppl bounds are not an option, I think papers should report the gen. ppl vs entropy frontier, or at least refrain from point estimates without matching entropy.
English

@Sam_Acqua Also, reporting perplexity bounds is not always straightforward. Some models, like distillation-based ones, are not trained with an ELBO or a clear likelihood objective, so it is unclear how to compare perplexity fairly.
English
@PatrickPyn35903 This is awesome. I wanted to try to explain it theoretically but never got to it. Really cool you figured it out + nice blog :)
English

Nice work! I wrote a blog on why entropy and gen perplexity trade off with each other a few months ago: patrickpynadath1.github.io/blog/eval_meth….
We can decompose KL divergence from the AR distribution and the generative distribution into a likelihood and joint entropy term. This shows that it’s possible to trade off one with the other while maintaining the same KL distance from the target distribution.
Sam Acquaviva@Sam_Acqua
Flow models are a promising alternative to autoregression. But the current standard of evaluating flow models is broken. The reported 3x improvement in 1024-step PPL since 2023 is closer to 1.1x if you control for sample entropy. (1/12)
English

Super important post by Sam!
We really need a way to benchmark properly all these GPT2-scale methods for language modeling 🤔
Sam Acquaviva@Sam_Acqua
Flow models are a promising alternative to autoregression. But the current standard of evaluating flow models is broken. The reported 3x improvement in 1024-step PPL since 2023 is closer to 1.1x if you control for sample entropy. (1/12)
English