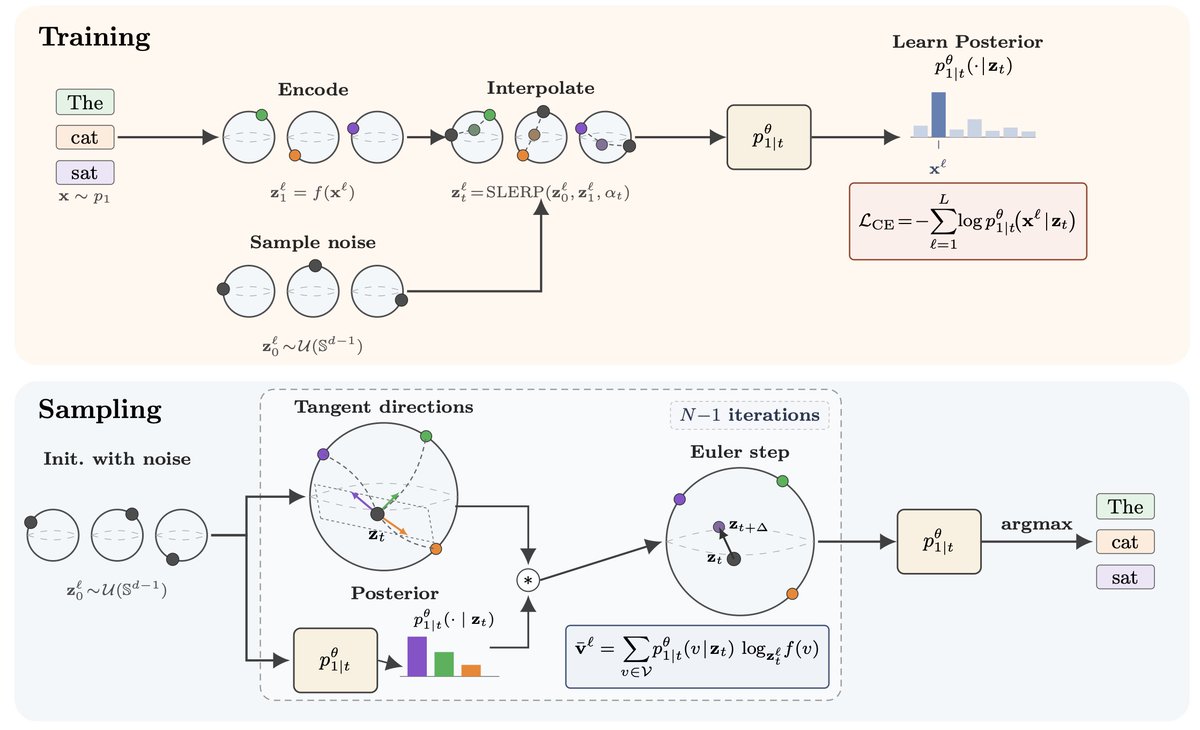
📢 May 25 (Mon): Language Modeling with Spherical Geometry 📷 💡Join us to hear Justin (@jdeschena) and Jannis (@JChemseddine) present their recent work on (Hyper)spherical language modeling! ⚖️Discrete Diffusion and Continuous Flow Language Models (DLMs / FLMs) have emerged as interesting alternatives to autoregressive models. Yet they face fundamental tensions: discrete diffusion samples from a factorized distribution that is strictly less expressive than AR. FLMs avoid factorized sampling but typically add Gaussian noise on one-hot vectors or embeddings. It is far from clear that this kind of noise is well suited to text generation. 🤔Both papers ask the same question: what if the natural geometry for language flows isn't Euclidean space or the probability simplex, but the sphere? The hint has been there for a while: prior work like CDCD (@sedielem et al.) already operates on normalized vectors, and empirically, the cosine distance outperforms the Euclidean one for comparing word embeddings (think of word2vec, GloVe, or retrieval systems). 🧭By lifting tokens onto Sᵈ⁻¹, the authors develop tools for spherical language modeling via SLERP and vMF paths. The vMF path has the added benefit of a closed-form score, enabling principled predictor–corrector samplers on the sphere. 📈 Working with the sphere leads to concrete performance improvements: on code generation with TinyGSM, prior FLMs reach roughly 0% accuracy, while flows on the hypersphere reach 12–18% 🚀. This still lags behind the AR and discrete diffusion baselines, but it strongly suggests that spherical embedding geometry is a natural noise model for tokens. At matched NFE, a properly tuned PC sampler with vMF paths clearly improves the accuracy on Sudoku. And as a bonus, training with rotations avoids materializing one-hot vectors, making it cheaper than standard FLM training⚡️. 🔗 Language Modeling with Hyperspherical Flows: arxiv.org/abs/2605.11125 🔗 Spherical Flows for Sampling Categorical Data: arxiv.org/abs/2605.05629 🤝 Joint work with Caglar Gulcehre (@caglarml), Gregor Kornhardt (@gregorkornhardt), and Gabriele Steidl (page.math.tu-berlin.de/~steidl/)