Dayo ❄️ retweetledi
Dayo ❄️
1.8K posts


Dayo ❄️
@Samuel0yeneye
engineer & researcher
Lagos, Nigeria Katılım Haziran 2016
1.7K Takip Edilen241 Takipçiler

Dayo ❄️ retweetledi

Dayo ❄️ retweetledi

will read it with my brain (instead of agent)
OptimaLab@optimalab1
During neural network training, the loss landscape gets sharper until it hits a ceiling. GD pins right at the ceiling. SGD settles below it — and the gap grows as you shrink the batch. Why? We now have the answer. arxiv.org/abs/2604.21016 🧵 Blog: akyrillidis.github.io/aiowls/stochas…
English
Dayo ❄️ retweetledi

The importance of stupidity in scientific research:

English
Dayo ❄️ retweetledi

I'm immensely grateful for the @ml_collective community. I have so little time for them now, but they show up every time I need them. I spent 0 time advertising this event, but we got great signups.
The research jam tomorrow is going to be an African special!

English
Dayo ❄️ retweetledi

In 2026, my goal is to take more good actions and less bad actions.
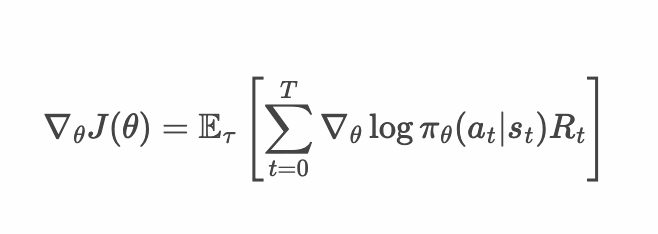
English
Dayo ❄️ retweetledi

365 days of LeetCode done 😅
I've gotten a couple of questions about how I was able to achieve this, so let me share my approach.
First, I acknowledged that 365 days is a long time. That was step one. Just accepting that this is a serious commitment. Then I told myself I wasn't going to start with so much force or zeal. If I started it as a sprint, I would have easily burnt out and lost interest. So after acknowledgement, I took it easy and applied constant pressure instead. For the first few months, I created a schedule and did my LeetCode in the morning before I got busy.
I already had some previous knowledge of DSA, so while solving questions, I also revisited things I'd learned before. But mostly, I just didn't overthink it. That was the general theme.
I also didn't beat myself up too much. The goal for me wasn't to find the most optimised solution at first, or even at all. The first thing was to understand the question. Can I work through my solution? Can I explain it to people? If yes, I solved my question. Writing shitty code was fine. I also used AI to help where I was stuck. When I had an idea or approach, I'd discuss it with the AI, let it point out loopholes, and ask my questions. For hard questions, I always checked the editorial. I used hints. I checked submissions. I didn't let the difficulty level chase me away. But I also struck a balance. I wasn't doing this every single time.
I worked on discipline and consistency. That's why I posted my solutions publicly—accountability. That thread was a reminder that I had something going and had to finish it. Some days I was sleepy, some days I lost count. Even when I was in camp for service, I still used my phone to do some things.
For the streak, you have to do the daily question, and you can only redeem three missed days in a month. So I calculated and planned. If I was going to miss a day, it had to be unavoidable. I asked myself: this month, I only have three passes. How do I use them if needed?
The dailies were good because each question was unique. I saw systems design questions, dynamic programming, memoization. iIt helped me learn a lot of different things.
I'm honestly happy and overwhelmed that this thing I did from the corner of my room is actually inspiring people. So yeah, that's my approach. Good luck to everyone attempting the 365 days!
English
Dayo ❄️ retweetledi

After rewatching Home Alone, I couldn’t stop wondering:
how plausible is the oversleep that leaves Kevin behind?
So I wrote a tiny paper and ran the numbers.
Merry Christmas! 🎄

English
Dayo ❄️ retweetledi

In your twenties there may be love. It's very important to ignore this love and pursue a PhD instead.


English
Dayo ❄️ retweetledi


Dayo ❄️ retweetledi
I'm happy to announce I've joined the @GoogleDevExpert family under the AI category! 🎉
I'm truly grateful for this opportunity, and I would like to thank everyone who helped me on this journey. Special thanks to @MilekeKolawole for dragging and encouraging me to submit my application😂, @weskambale for guidance on the process, @DeniseAllela and @Geektutor for their support.
I look forward to giving back more to the community and building cool stuff. 🚀


English
Dayo ❄️ retweetledi
Announcing one of my Gen AI projects, Briefen! 🎉
Unlike traditional shorteners, Briefen reads your page and uses AI to create context-aware short links, ones that actually describe your content.
👉🏽 briefen.me
English
Dayo ❄️ retweetledi

Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.

English
Dayo ❄️ retweetledi

Looking forward to giving this talk 💪
SysConf by SysDsgn@sysconf_
We're excited to announce Habeeb Shopeju @HAKSOAT as a speaker at SysConf 2025! His talk is titled "An Introduction to the Inner Workings of LLM Inference Engines". In it, he will briefly introduce how text generation models work, including how inference servers and hardware transform user prompts to outputs. Then he plans to explore Why the KV cache becomes a bottleneck and how PagedAttention solves memory fragmentation like an operating system. Finally, he will explore speed optimizations: FlashAttention for efficient memory access, continuous batching for GPU utilization, and speculative decoding for multi-token prediction.
English
Dayo ❄️ retweetledi
To think I almost didn't submit an application because it's same day as the WiNLP workshop at the EMNLP conference in China (my team had our paper accepted).
I applied regardless.
As it turns out, I can't even attend that due to visa issues 🫠
Habeeb Shopeju@HAKSOAT
Looking forward to giving this talk 💪
English
Dayo ❄️ retweetledi

Dayo ❄️ retweetledi

On today’s MLC-Ng Sunday Specials call, an old-timer returned after a research role at Max Planck l (undergrad at UNILAG); another casually mentioned his new role at Google.
Joining these calls weekly is humbling-seeing so many talented folks doing big things from small places.

English
English

My first physical international workshop presentation at PyCon Kenya 🇰🇪 2025!
Thanks to the organisers @PyconKenya for the opportunity to lend my voice and share my experience in building scalable and reliable AI systems.
@DavidAbu_ @OfficialSamAyo @GiftOjeabulu_ @Opiano_1



English
Dayo ❄️ retweetledi

Introducing Tinker: a flexible API for fine-tuning language models.
Write training loops in Python on your laptop; we'll run them on distributed GPUs.
Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
thinkingmachines.ai/tinker

English