Sabitlenmiş Tweet

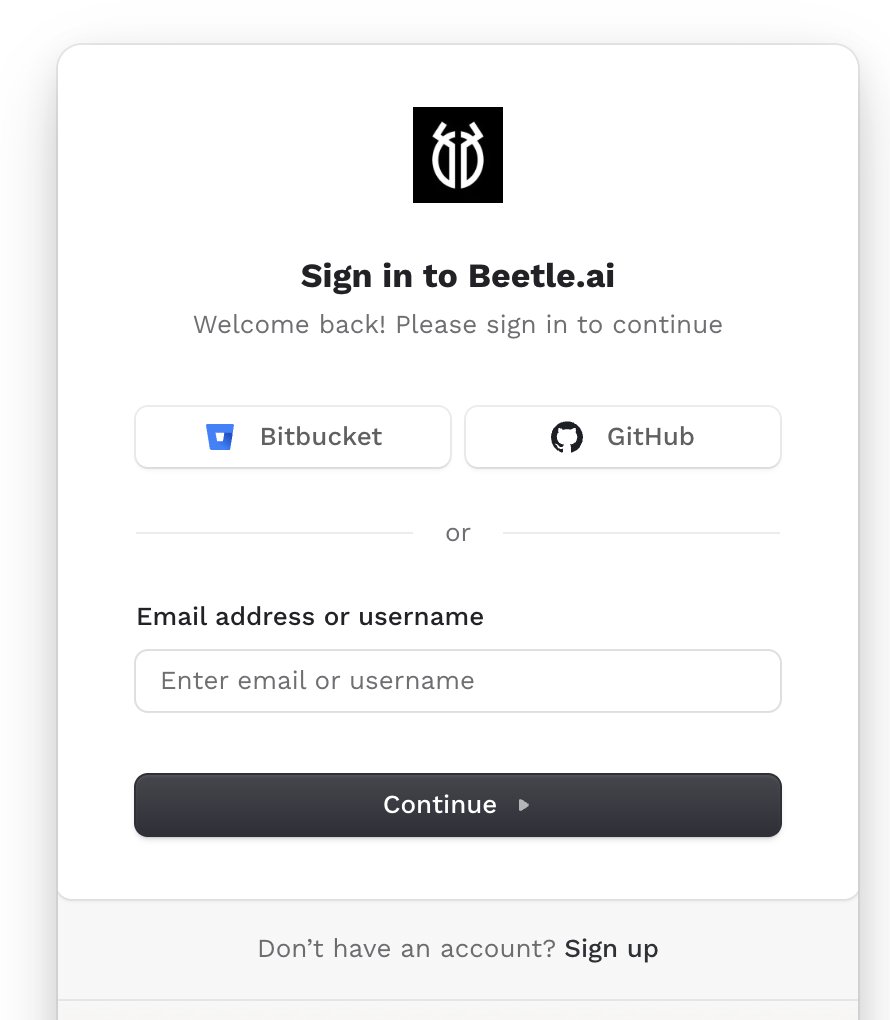
Introducing Beetle - Quiet safety for fast teams !!!
Meet Beetle 🐞
An AI code reviewer that catches bugs, security issues, and regressions
before they reach production.
beetleai.dev
#BeetleAI #DevTools
English
Saran
520 posts


exclusive community access only, opening it up for few folks soon keep an eye out @librahq

we got strong candidates for the positions we already filled, though there was also an insane amount of AI-generated slop in the inbox. sharing these here since these are probably our last two openings for now: HIRING: Full Stack Engineer Intern (with PPO opportunity) Location: Remote Pay: up to ₹1.5L/month (scaled to output) RAETH builds AI training infrastructure for frontier labs — evals, RL environments, expert data — focused on quant trading, betting, and business use cases. you’ll be building the interfaces and tooling that turn our infrastructure into something humans can actually use: dashboards for eval runs internal tools for data labeling customer-facing platforms for lab clients whatever else needs to exist by Friday Requirements: good design sense comfortable with databases, APIs, auth, deployment you ship fast and iterate you don’t wait for a Figma before writing code you can code in Python without AI holding your hand Nice to have: experience with developer tools, internal platforms, or ML-adjacent products background in trading, finance, or business a portfolio of things you’ve actually shipped, not just repos with three commits PPO is on the table for interns who clearly outperform. we hire interns we want to keep. follow me to see the work we’re building (Arena, research, infra, etc.) and send your resume to careers@raeth.ai our engineering team will review applications, and if your stuff stands out, we’ll get on a call. and if you don't hear back from us in a week, consider your application passed




We've raised $6.5M to kill vector databases. Every system today retrieves context the same way: vector search that stores everything as flat embeddings and returns whatever "feels" closest. Similar, sure. Relevant? Almost never. Embeddings can’t tell a Q3 renewal clause from a Q1 termination notice if the language is close enough. A friend of mine asked his AI about a contract last week, and it returned a detailed, perfectly crafted answer pulled from a completely different client’s file. Once you’re dealing with 10M+ documents, these mix-ups happen all the time. VectorDB accuracy goes to shit. We built @hydra_db for exactly this. HydraDB builds an ontology-first context graph over your data, maps relationships between entities, understands the 'why' behind documents, and tracks how information evolves over time. So when you ask about 'Apple,' it knows you mean the company you're serving as a customer. Not the fruit. Even when a vector DB's similarity score says 0.94. More below ⬇️




🚀 We’re building Aurora AI (stealth) at the intersection of AI × offline world Ex-YC founders (built → scaled → sold) Backed by Global VCs & Angels Hiring Founding Engineers who want: ⚡️ high ownership • 🧠 deep code • 😈 zero BS Know some1? Tag them & win Airpods Max🎧




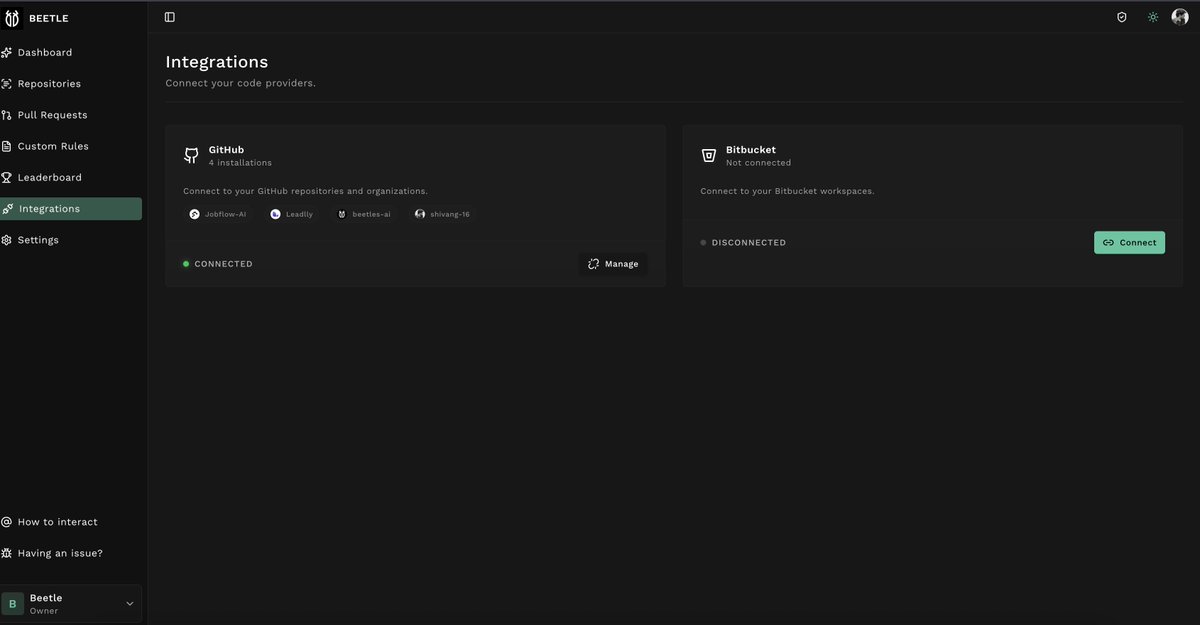

In our last demo, a client requested Bitbucket support since their team uses Bitbucket, so adding Bitbucket integration to Beetle Bitbucket support -> coming soon in Beetle! 👉 Try beetleai.dev