Sabitlenmiş Tweet

“What is the meaning of life, the universe, and everything?”,
...... Deep Thought gives a very simple and supposedly off the wall answer: “42”
oops..... Correction, it is now 32
#ETH #ether #cryptocurrency
English
SaucyCrypto 🦇🔊
1.2K posts










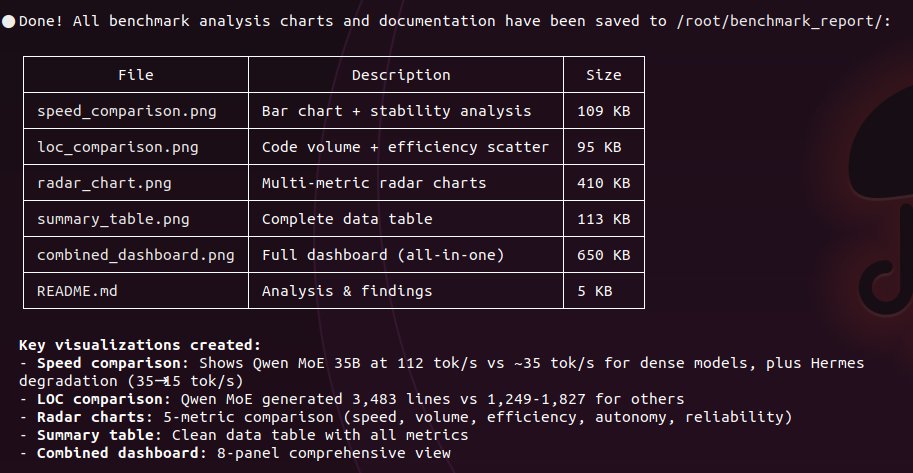
downloading Qwen3.5-27B Claude 4.6 Opus Reasoning Distilled(Qwopus) right now. Q4_K_M quant on a single RTX 3090. same hardware i've been testing every model on this month. someone took the base model i've been daily driving and distilled Claude Opus 4.6 reasoning chains into it. same 27B parameters, same architecture, but fine tuned on how Claude thinks through problems. the base model already built 1,827 lines of working code in 13 minutes with zero steering. curious what distilled reasoning adds. switching harness too. the base ran on OpenCode. this one runs through Claude Code. claude distilled model through claude's own coding agent. want to see if the reasoning patterns carry differently when the harness matches the distillation source. will post speed sweep first to get the numbers. then checking if the jinja template bug that silently kills thinking mode carries over from the base model. then octopus invaders. same prompt that base qwen passed in 13 minutes and hermes 4.3 failed on 2x the hardware. 4 models. 1 GPU. 1 prompt. results soon.







Read this from Peter and realized that it's time for me to also speak up. NGL, I’ve started questioning my loyalty toward Ethereum. I did not come into crypto because of Bitcoin but because of Ethereum. I also have a lot of gratitude toward @VitalikButerin — someone I looked up to as an ideal for how things should be built in this world. Though I/we never got any direct support from the EF or the Ethereum CT community — in fact, the reverse. But I have always felt moral loyalty towards Ethereum even if costs me billions of dollars in Polygon's valuation perhaps. The Ethereum community as a whole has been a shit show for quite some time. Why does it feel like every other week, someone with major contributions to Ethereum has to publicly question what they’re even doing here? Just go your own way already. At best, I get trolled by well-meaning friends like @akshaybd for not declaring Polygon an L1 and walking away from this circus. Not many remember that Akshay himself was equally inclined toward Polygon in the beginning before he took his talents and helped build the Solana empire into what it is today. He got disgusted by the socialistic behavior of the Ethereum community — trolling projects like Polygon that were contributing immensely — all because of some arbitrary “technical definition.” At worst, people have started questioning my fiduciary and moral duty toward Polygon. It’s widely believed that if Polygon ever decided to call itself an L1, it would probably be valued 2–5× higher than it is today. Like think about it, Hedera Hashgraph an L1 is valued higher than Polygon, Arbitrum, Optimism and Scroll combined. To make things even worse, the Ethereum community ensures Polygon is never considered an L2 and is never included in the markets' percieved Ethereum Beta. They don’t seem to understand that Polygon PoS effectively hinged on Ethereum, while Katana, XLayer, and dozens of other chains in Polygon's ecosystem are true L2s. Heck, a prominent Polygon Stakeholder literally scolded me just today because I can’t get Polygon on GrowthPie, which refuses to list the Polygon chain. When Polymarket wins big, it’s “Ethereum,” but Polygon itself is not Ethereum. Mind-boggling. Anyway — I’m also a stubborn, hard-ass soul. I’m going to give this a final push that might just revive the entire L2 narrative. Just bear with me for a few more weeks. But the Ethereum community needs to take a hard look at itself — and ask why, every day, contributors to Ethereum, even major ones like @peter_szilagyi, are forced to question or even regret their allegiance to Ethereum. My only (remaining) defense to myself is that Ethereum is a democracy — and in any democracy, people on all sides end up disgruntled. But it’s still the only system that truly works in the long run. 🤞

On Tempo, permissionlessness, L1 vs L2 Tempo will be a permissionless chain. On day 1, anyone will be able to deploy a token, and anyone will be able to transact on the chain. Some projects think that attracting real-world usage and serious institutions requires giving up on base layer neutrality. We do not think that, and that's not how we're building Tempo. The plan for Tempo is to have permissionless validation and permissionless smart contract deployment as well as permissionless usage: just like Bitcoin, Ethereum, Solana, etc. We’ll start with a permissioned validator set to get going and decentralize further from there. We’re building in features to make it easy for entities interacting with the blockchain (like asset issuers, money transmitters, etc.) to comply with their relevant obligations, but the base layer will remain neutral. This is a principle we feel incredibly strongly about (see: paradigm.xyz/2022/09/base-l…). As many parts of the mainstream world look to adopt crypto, we think there is a risk that they adopt permissioned systems. Our goal with Tempo is to help onboard them onto crypto rails that solve specific payments needs while still being truly permissionless. — Why L1 rather than an Ethereum L2? At Paradigm, we are heavily invested, both intellectually and literally, in the Ethereum ecosystem. We will continue to help it scale, and invest in and support companies building on Ethereum. We are also extremely excited about single-sequencer L2s for many use cases, including trading. But building a network for global payments will require bringing together thousands of partners that may not trust us, or Stripe, or anyone as a platform. We think a decentralized validator set—for the chain itself—is a necessary requirement for those partners, and to ensure that the chain is unquestionably neutral in the long run. From an operational perspective, we feel urgency to build for the demand that’s coming and want fewer dependencies, including on the rate of Ethereum L1 progress. With Tempo, we tried to remove all crypto tribalism and alignment games from our thinking and just focus on building the right product for crypto payments. At a technical level, we are prioritizing attributes like fast finality (L2s are generally only as final as the underlying L1), multiple validators (vs. single sequencer), and custom transaction lanes and gas pricing. Some of these are technically possible for an L2, but could be complex, slow to implement, and/or introduce many external dependencies. Tempo is stablecoin-focused, so interoperability through native issuance is more relevant to us than the native bridge to Ethereum that L2s have. We aren’t Bitcoin, Ethereum, or Tempo maximalists. We’re maximalists for permissionless crypto. We want Ethereum L1 to scale, and we want L2s to thrive. We love Bitcoin as a monetary asset. We find substance in Solana, Hyperliquid, and many other ecosystems. We want to ensure real-world payment flows happen on crypto rails, and that’s why we’re building Tempo.

