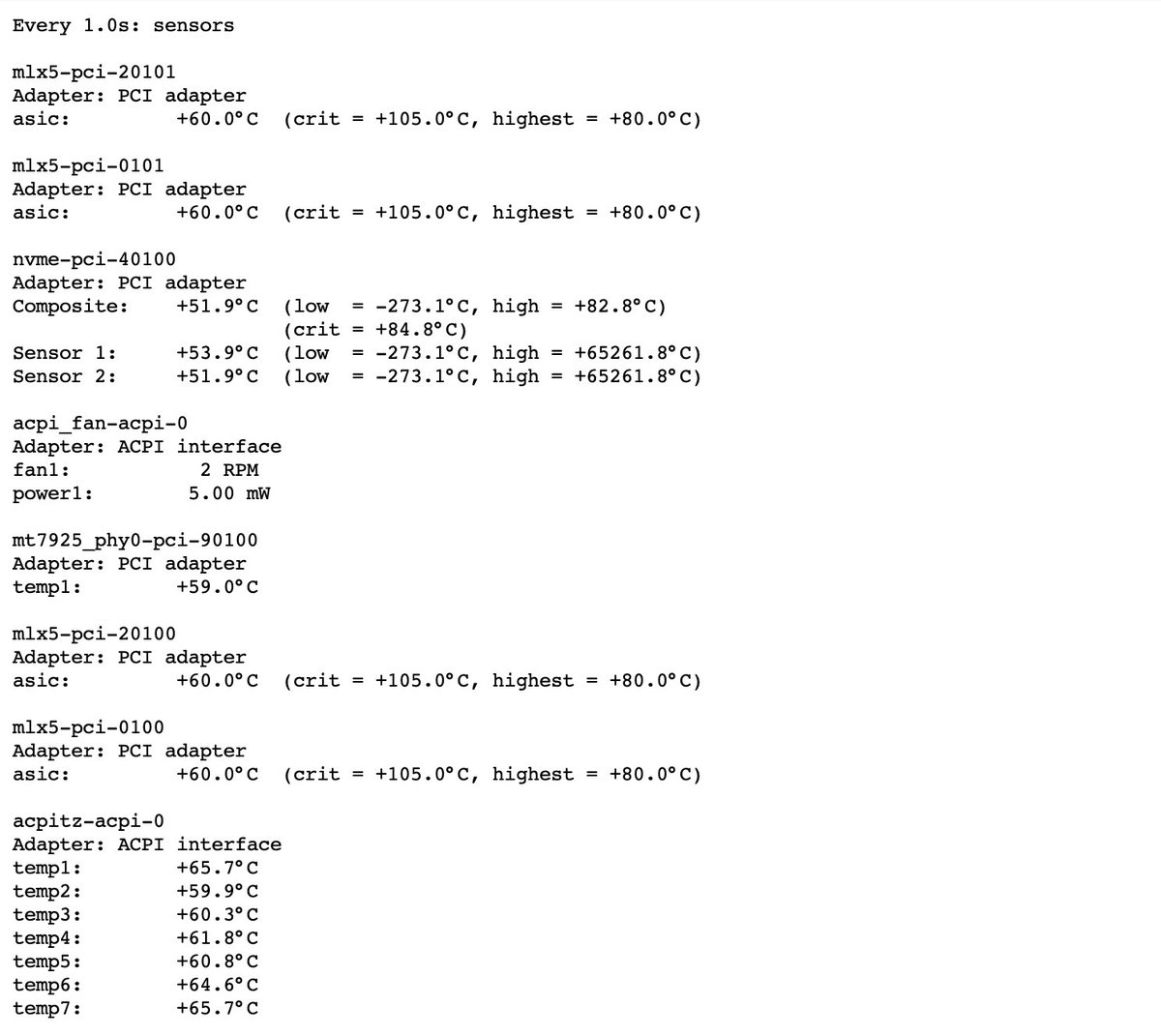

@carnivalqueue @Zarik_dolaknm @AltugAkgul Est. Ben bu alanda doktora yaptığım için biraz konuşma hakkini kendimde görüyorum. Çünkü çok fazla ai saçmalaması var etrafta ve bu işle uğraşandan cok, alakası olmayan insanlar konuşuyor. Kolay gelsin
Türkçe