Sabitlenmiş Tweet

I'm sorry @zeddotdev, your CodeEditor is so smooth.
Great UI
Extremely fast and responsive
The UI is awesome, I love it

English
Ankan
2.2K posts

@ShadowRage11
21 • F1 • building on @zeddotdev

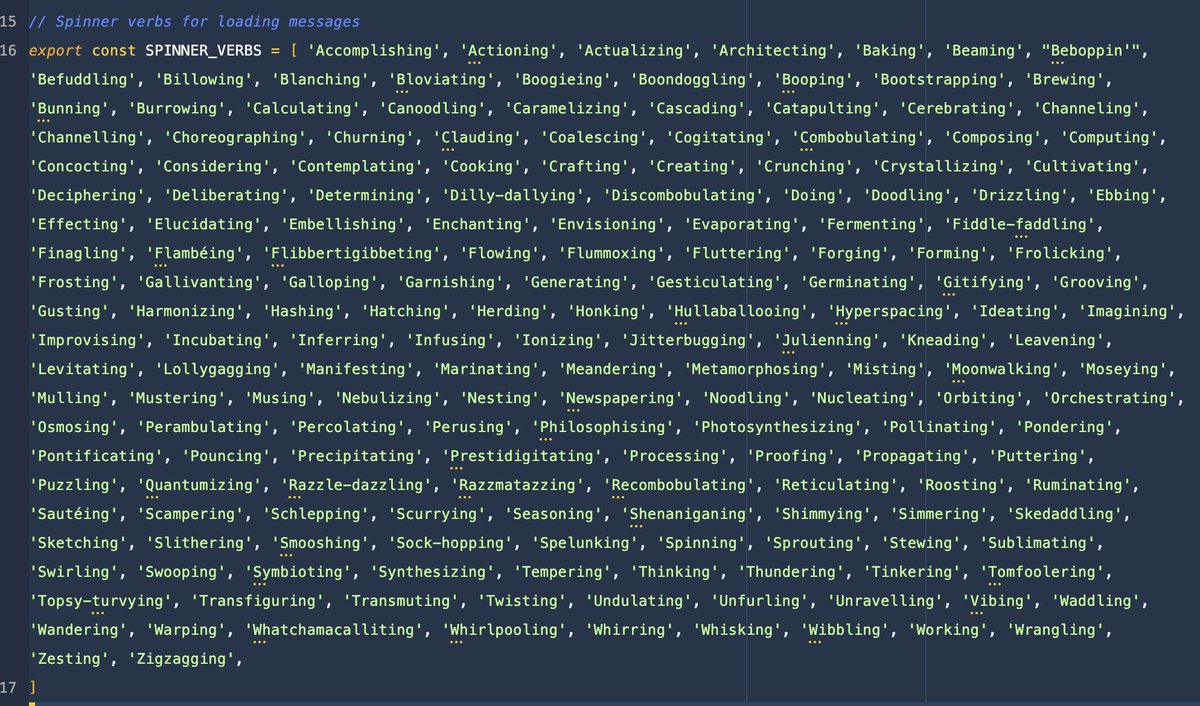
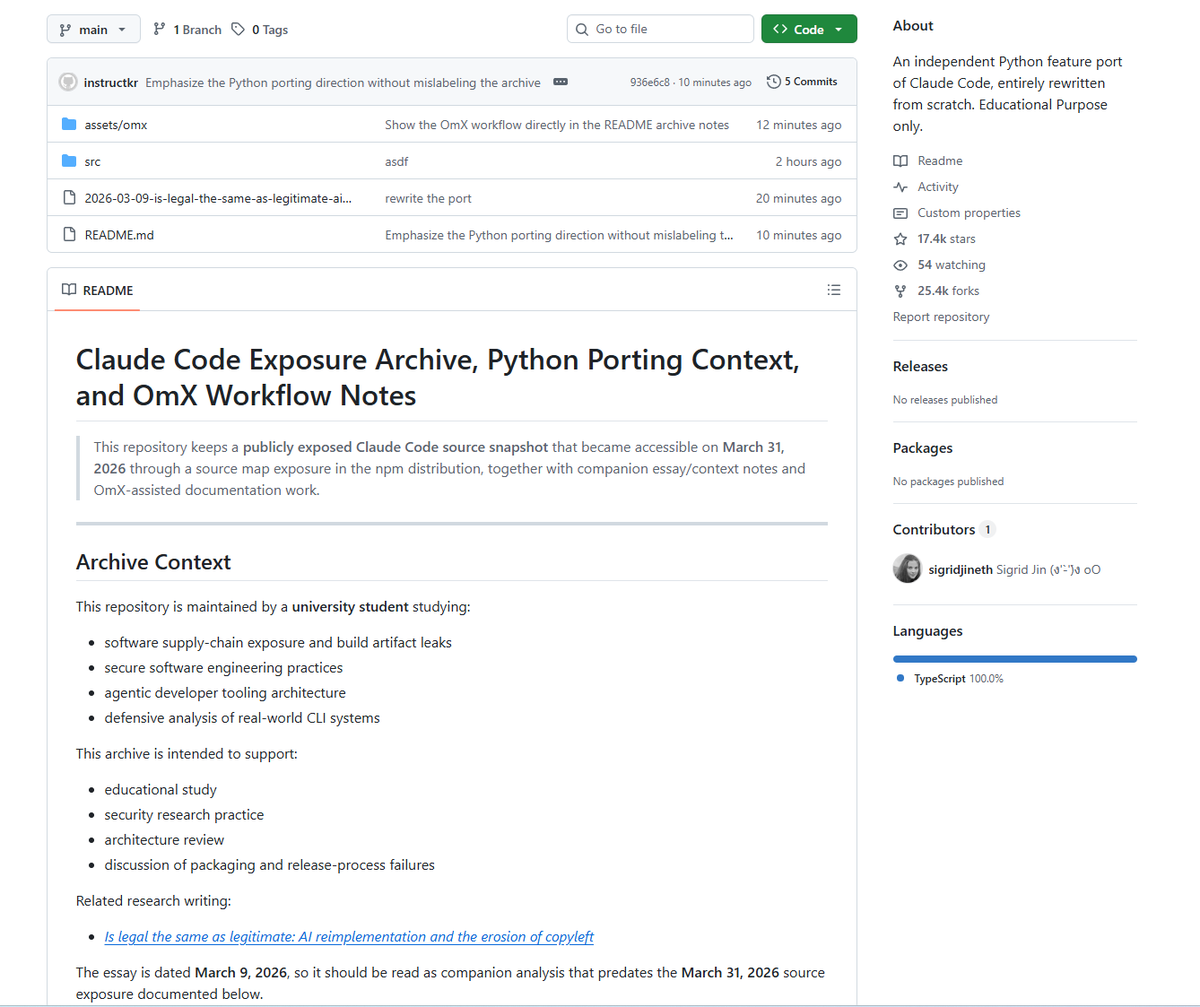
Unreal. The entire Claude Code source code just leaked It reveals EVERY secret Anthropic has in store for Claude I went through all 600,000 lines of code Here's EVERYTHING juicy detail you need to know about how Claude Code is built and what is coming next:





Claude code source code has been leaked via a map file in their npm registry! Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip

Claude code generates random 4 character IDs Then they filter out 25 swears. Kenneth tried to tell them..

Claude code source code has been leaked via a map file in their npm registry! Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip