Sabitlenmiş Tweet

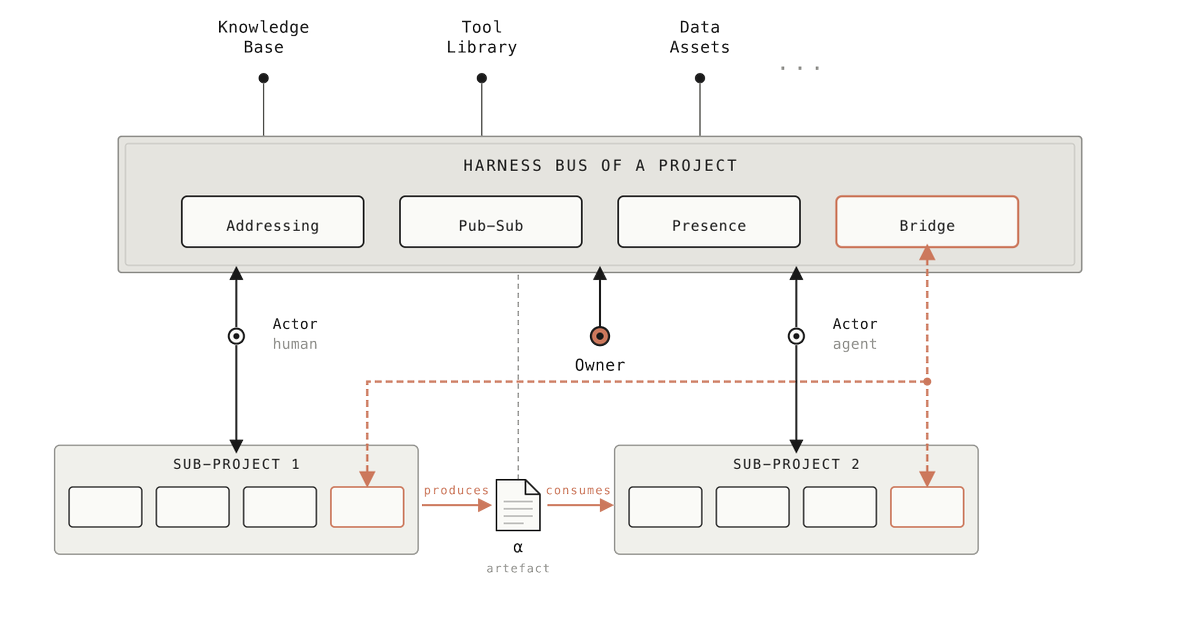
Most agent systems disappoint not because they are not smart enough
but because they keep making humans teach the same lesson twice.
A boundary explained five times should become a default, not a recurring reminder.
That missing mechanism is Harness Learning.
We wrote up how we think this will define the next generation of collaboration-aligned agent systems.
ConteXeed@contexeed
English