
Shrey Modi
273 posts
Shrey Modi
@ShreyModi13
CS @iitbombay, @uchicago. prev @nexusvp @barclays. Reinforcement learning research at NeurIPS, ICLR.
Palo Alto, CA Katılım Kasım 2020
1.3K Takip Edilen221 Takipçiler

Thinking of hosting more chai and samosas in SF at ours ☕️
Want to come hang out with good people and have fun snacks, lmk below! 🙌

English

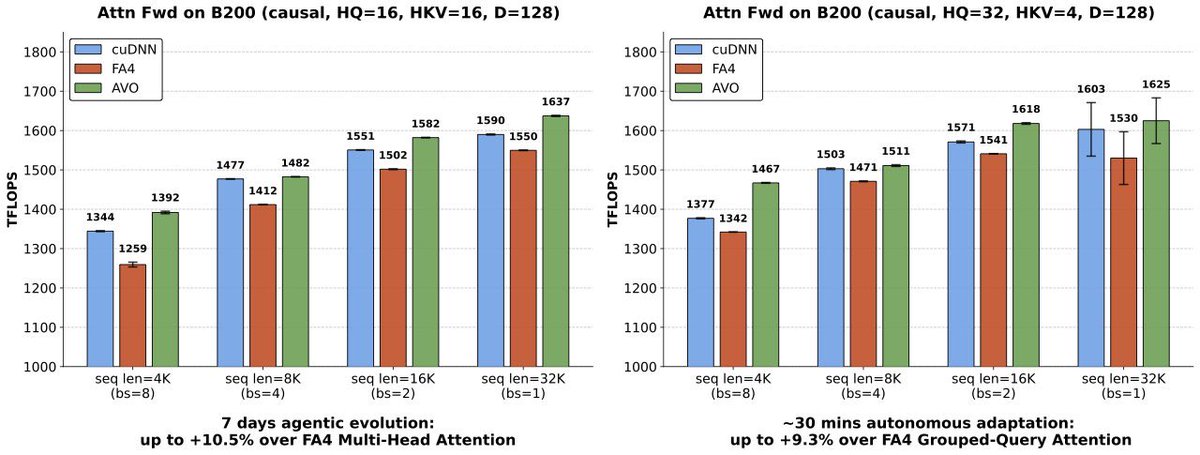
This may be one of the first real signs of superhuman intelligence in software. On some of the most optimized attention workloads, agents can now outperform almost all human GPU experts by searching continuously for 7 days with no human intervention inside the optimization loop.
Terry and I started agentic coding efforts at NVIDIA 1.5 years ago. Neither of us knew GPU programming, so from day one we pushed toward fully automated, human-out-of-the-loop systems. We call it blind coding.
Over those 1.5 years, the two of us generated 4 generations across 2 agent systems. Since the 2nd generation, the stacks have been self-evolving. Each agent is now around 100k non-empty LOC.
When we released the blind-coding framework VibeTensor in January, the implication was easy to miss. AVO makes the signal clearer.
My bet is: blind coding is the future of software engineering. Human cognition is the bottleneck.

English

Excited to release @gepa_ai's optimize_anything: a universal API for optimizing any text parameter.
It consistently matches or outperforms domain-specific tools optimizing code, prompts, agent harnesses, cloud policies, even visuals!
If you can measure it, you can optimize it.

English

lil life update: left waterloo last september and moved to nyc to join @cadastral_ai as a founding engineer.
every CRE analyst in new york is manually reading 200-page leases and underwriting deals in excel. trillions in transactions. the entire back office is still done by hand. we're fixing this.
we build ai agents that automate commercial real estate end to end — lease abstraction, due diligence, underwriting, compliance.
we already work with most of the big CRE firms in nyc. JLL, Blackstone, AvalonBay, Equity Residential, Empire Realty Trust, Continental Realty etc
came out of stealth last week and announced our $9.5M seed round.
we’re growing the team and hiring more engineers. in-person nyc.


English
Convert production data into evals through semantic clustering!
Fireworks AI@FireworksAI_HQ
When teams talk about “doing evals,” the hard part is rarely conviction. It’s data. If you’re running an LLM in production, you already have the most valuable evaluation signal you’ll ever get: real user traffic. The challenge is turning noisy, redundant production logs into a dataset that is small enough to evaluate, yet rich enough to reflect how your system is actually used. We put together a blog, to walk you through a practical, data-driven approach to that problem. Instead of hand-authoring test cases or randomly sampling logs, we show how semantic clustering can compress thousands of production traces into a compact, representative evaluation set that preserves user intent, edge cases, and long-tail behavior. The result is an evaluation workflow that is grounded in reality, efficient to run, and far more informative than synthetic examples. Your users effectively define what “good” needs to mean. If you’re thinking seriously about evaluation beyond vibe checks, this is a pattern worth adopting. Read the full blog here: fireworks.ai/blog/Turning-P…
English

new year, new game!
playing soon and this founder will teach everyone how to play PLO
soooo you don’t need to know *how to play*. but you must be a degen. comment / DM if you are said degen
Katie Mishra // Khosla Ventures@katieruthmishra
if you wanna play poker in my living room, next game is week of thanksgiving ft. founder I just invested in who is obsessed with poker, lol. he might make you play PLO tho 😬 hmu if you're in town and wanna come!
English
for teaching continual learning and memory management, can we do cross episode training where apart from giving the answer at the end of the episode, the model also writes to a file which it can then retrieve later things that it has learnt from the particular episode? the model will get rewards for relevant memory used in future episodes, this way it can learn how to write important memory?
English

we're looking for great engineers at greptile to build agents that catch bugs.
over the last year, we've grown from zero to millions in revenue, thousands of customers including top engineering teams of all sizes like scale, brex, whoop, substack, partiful and multiple F500s.
software is eating the world, and autonomous validation is an extremely difficult problem. if we succeed, there is an opportunity here to build a large and important company.
this is a particularly interesting time to join the team. we have laid the groundwork to be able to work on a variety of hard and interesting problems.
i'm especially proud of the early team we have built. it's hard to overstate the joy of getting to work with brilliant people that care deeply about their work and about each other.
if you're excited about a future that is free of bugs, we'd love to hear from you :)

English
@lateinteraction will training models specifically for using the RLM harness better create further improvements? curious to know!
English

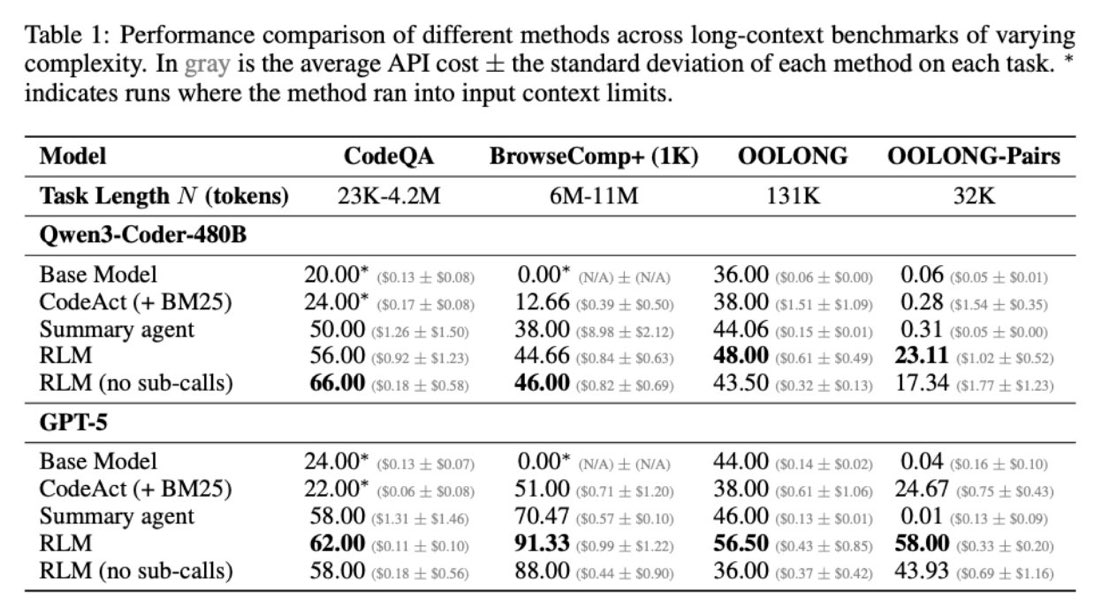
Something we perhaps understate in the paper/thread is that *open models can already work extremely well as RLMs*.
I was rather surprised by how well Qwen3 does.
alex zhang@a1zhang
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs). It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs! Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025! arxiv.org/pdf/2512.24601
English


we should then RL the main agent to initially explore more in the early episodes so we can collect a lot of feedback from the environment and then exploit in later episodes
English
Wondering if coding agents understand huge codebases mostly because they’re great at context narrowing (e.g., smart grep/search). If so, can we train a similarly strong “context-narrowing” sub-agent for other tool-call / text2sql tasks, one that selects the right domain knowledge + past mistakes to pull in each run. we would need to find a nice memory structure for storing these past mistakes
English
@YulunJiang @LiangzeJ @DamienTeney @Michael_D_Moor @mariabrbic Find the paper here - arxiv.org/pdf/2512.16848
English
Really interesting work! This is what I have been thinking for a while, wondering how something like GEPA with this would work
Authors:
@YulunJiang
@LiangzeJ
@DamienTeney
@Michael_D_Moor
@mariabrbic

English
we just opened a research engineering role in san francisco
building the universal bug catcher comes with a lot of interesting and hard subproblems.
- how can agents learn the idiosyncrasies of a codebase as fast as possible?
- how can agents adapt to user preference to only surface the type of code feedback that they would care about?
- exactly what synthetic tests should agents generate and run to detect missed edge cases?
if these sound interesting to you, you should reach out to us.
we are particular excited about new grads (including masters and phd programs) that have worked on coding agents before or generally interested in applying LMs to software production.
this is in-person in san francisco only
English
English
We did a few experiments running GEPA and GRPO together to push the performance of open-source models even further!
From our experiments you can squeeze out ~60% of the performance using just prompt optimization and then ~40% using GRPO :)
Fireworks AI@FireworksAI_HQ
Everyone has evals. No one knows what to do with them. Meanwhile, your agents aren’t actually getting smarter. Most teams end up with a glorified report card. But with Eval Protocol, those same evals can finally do real work. The exact evaluation definition you already have becomes a training signal rather than a static score. That one eval now powers: 🚀 Continuous prompt tuning via GEPA 🚀 Reinforcement fine-tuning 🚀 Zero extra reward models 🚀 Zero duplicated metrics or parallel eval stacks We ran this flow on a real Text2SQL agent: GEPA alone boosted accuracy from 27% → 43%! Same model, same data, same eval. Then we plugged that same evaluator into Fireworks Reinforcement Fine-Tuning and pushed performance even further. By layering GEPA before RFT, we achieved these gains at a fraction of the cost of pure fine-tuning. 🚀Define your eval once. 🚀Use it everywhere. 🚀Let your agents continuously improve. If you’re already running evals, you’re way closer than you think. na2.hubs.ly/H02F4gh0
English