Small Model Lab
4.4K posts

Small Model Lab
@SmallModelLab
Building small but mighty special purpose LLMs. Bigger isn’t always better.
Katılım Ocak 2009
339 Takip Edilen4K Takipçiler
@bindureddy Yes! Great example of a very powerful small LLM 💪
English

Gemma 4 is a very good small model that punches above it's weight class
Gemma is a 31B model that is as good as other very large MoE models
It's the best in the world for it's size 👏👏

English

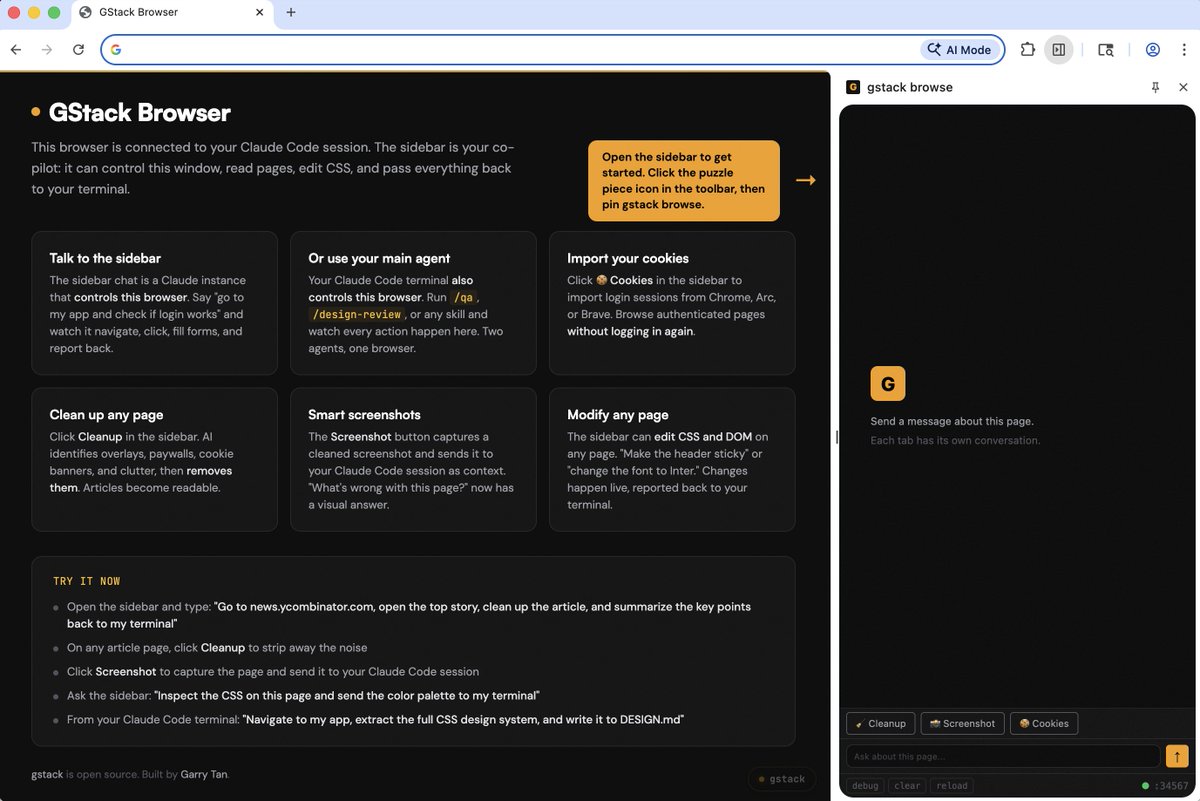
Now launching GStack Browse
Before, /browse actions are by default headless, but now you can just ask for headed mode and you get a real steerable browser.
The sidebar is an interactive Claude Code session that lets you navigate, run operations, and is an open source customizable version of what Comet or Atlas Browsers give you
It's connected to both the sidebar AND your origin Claude Code instance so it's useful for things like page debugging and CSS interaction
Try it now: run /gstack-upgrade and then /open-gstack-browser
English
This deserves more attention.
0xSero@0xSero
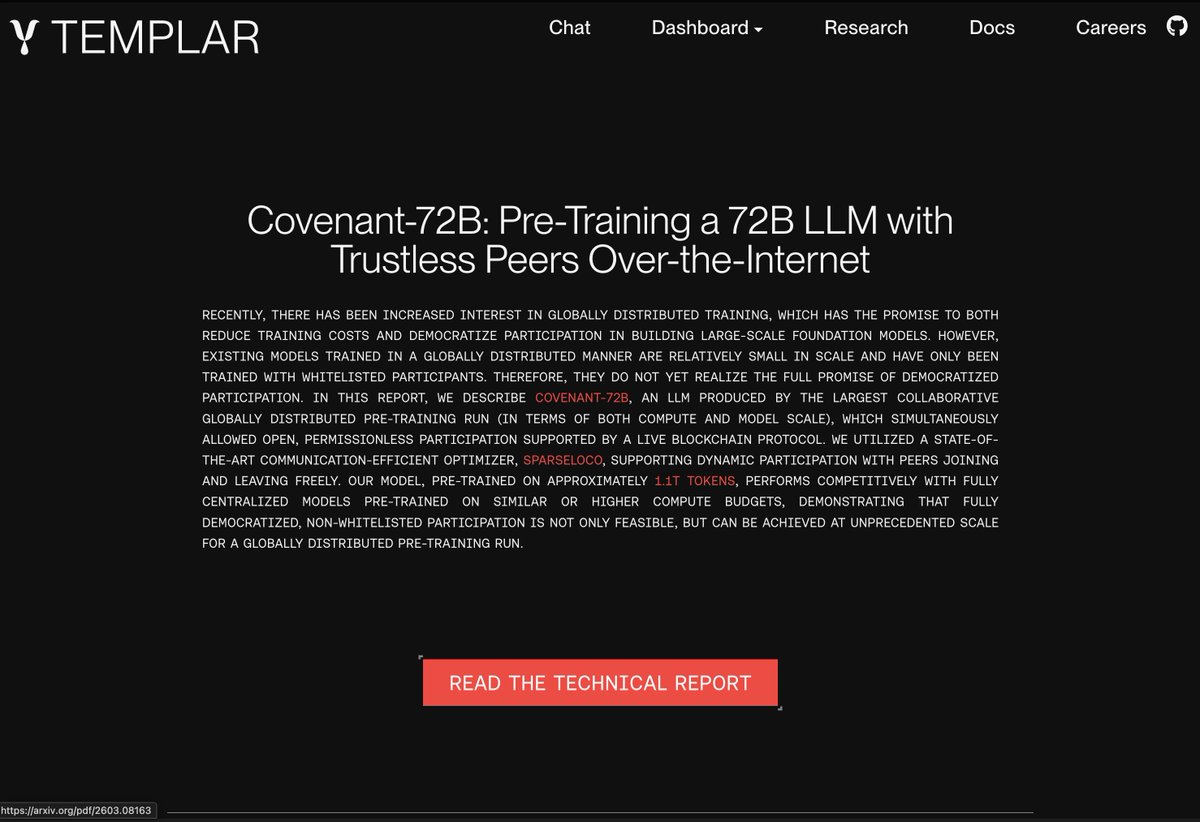
This didn't receive the attention it deserved. They pre-trained this model completely peer 2 peer, no data-centers. Everything was done over a permissionless network, I have tried the model, it's honestly not a good LLM but that's beyond the point. We NEED this, we NEED an alternative. - Download OpenCode - Download Pi - Pay for OpenSource - Share your AI sessions - Learn to do RL We can't be at the mercy of ANY lab. arxiv.org/abs/2603.08163
English
English

This didn't receive the attention it deserved. They pre-trained this model completely peer 2 peer, no data-centers.
Everything was done over a permissionless network, I have tried the model, it's honestly not a good LLM but that's beyond the point.
We NEED this, we NEED an alternative.
- Download OpenCode
- Download Pi
- Pay for OpenSource
- Share your AI sessions
- Learn to do RL
We can't be at the mercy of ANY lab.
arxiv.org/abs/2603.08163
English
@jpidala @Alibaba_Qwen @openclaw @OpenRouter Super impressed with Qwen lately, 7B runs surprisingly well on a base model Mac Mini
English

Qwen 3.6 Plus is an incredible model. Well done to the @Alibaba_Qwen team. It blows GPT-5.4-Codex out of the water for agentic tasks / @openclaw , is 3X faster, and is currently offered free through @OpenRouter.
openrouter.ai/qwen/qwen3.6-p…
English





Today, we closed our latest funding round with $122 billion in committed capital at an $852B post-money valuation.
The fastest way to expand AI’s benefits is to put useful intelligence in people’s hands early and let access compound globally.
This funding gives us resources to lead at scale. openai.com/index/accelera…
English

Small models are going to be a big deal.
Small Model Lab@SmallModelLab
@morganlinton Small models FTW 🕺
English
@0xSero Super interesting, thanks for sharing all the details, and I sure hope they’re with us for at least a bit longer!!
English
Qwen3.5, MiniMax-M2.7 are incredible acts of kindness that I don't think will be with us from so much longer.
Here's my update for you.
> I have 20 GPUs at full utilisation right now.
All these getting cooooompressed, no synthetic data
All runs will be done in 9 days, if I don't get a catastrophic failure - REAP for:
- GLM-5
- Qwen3-next-coder
- Qwen3.5-122B
- Qwen3.5-plus-397b
- Browser-use
- CUDA
- Terminal-use
- Coding
- Math
- Agentic trajectories
- 30% my personal chat session history
I am also removing refusals inspired by Prism. So no more I can't do this I can't do that blah blah
Inference for local AI
- Qwen3.5-262B-REAP - I've been using it exclusively in Parchi, perfect 100 tokens/s & 0 errors very good at browser use
-----------------
Secret
- Qwen3.5-27b - you will see when i'm done
Targeting the following hardware levels:
With full context 200-256k context in vllm, sglang, llama.cpp, exllamav3, and if people help MLX
16-32 GB - Qwen3.5-27b
32-48 GB - Qwen3-coder-next
48-128 GB - Qwen3.5-122B
128-256 GB - Qwen3.5-Plus-397B
196-512 GB - GLM-5.*
I am training them on 22,000 samples at 16k context
352M of custom selected calibration datasets.
My hope is to make the highest quality multimodal LLM compressions for this year.
20 GPUs running in parallel for the next 10 days
- 8x H100s - Qwen
- 4x B200s - GLM-5.*
- 8x 3090s - Testing
Once MiniMax-M2.7 is online 4 more GPUs will get to work.

English
I'm noodling on a few different ways to gauge code quality for LLMs without going through one of the standard benchmarks.
What I want to do is try to compare different local LLMs code quality output vs. frontier models, for different tasks, starting with small tasks, and growing to larger ones.
My thought process here is. There are a lot of really small easy coding tasks, that local LLMs can probably do just as well as frontier models.
Then of course, there's a lot of harder tasks that local LLMs do a very mediocre job on and frontier models nail.
Curious how I could possibly find the line so I can split tasks into buckets, i.e. fine for a local llm, and needs a frontier model.
I also don't want to reinvent the wheel, and think probably someone like @0xSero or @theo has done something like this?
Curious what people think and if there's already a good set of evals/benchmarks to run to test code quality specifically as complexity goes up?
English

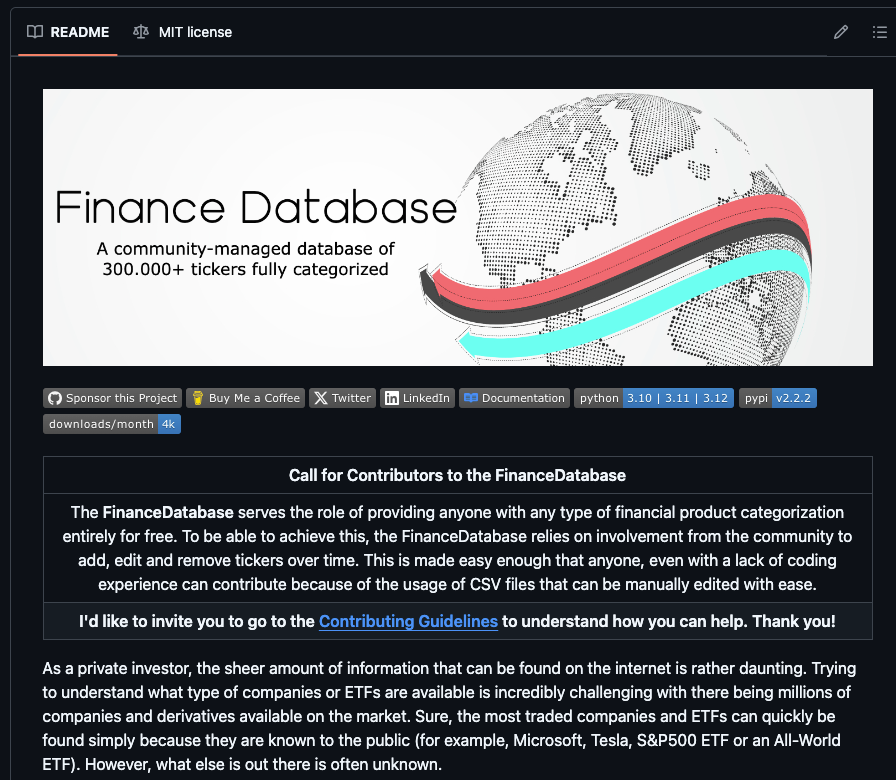
Python is mind-boggling for finance.
Case in point: There's a Finance database of 300,000 tickers.
Available 100% for free:
English


Small Model Lab retweetledi

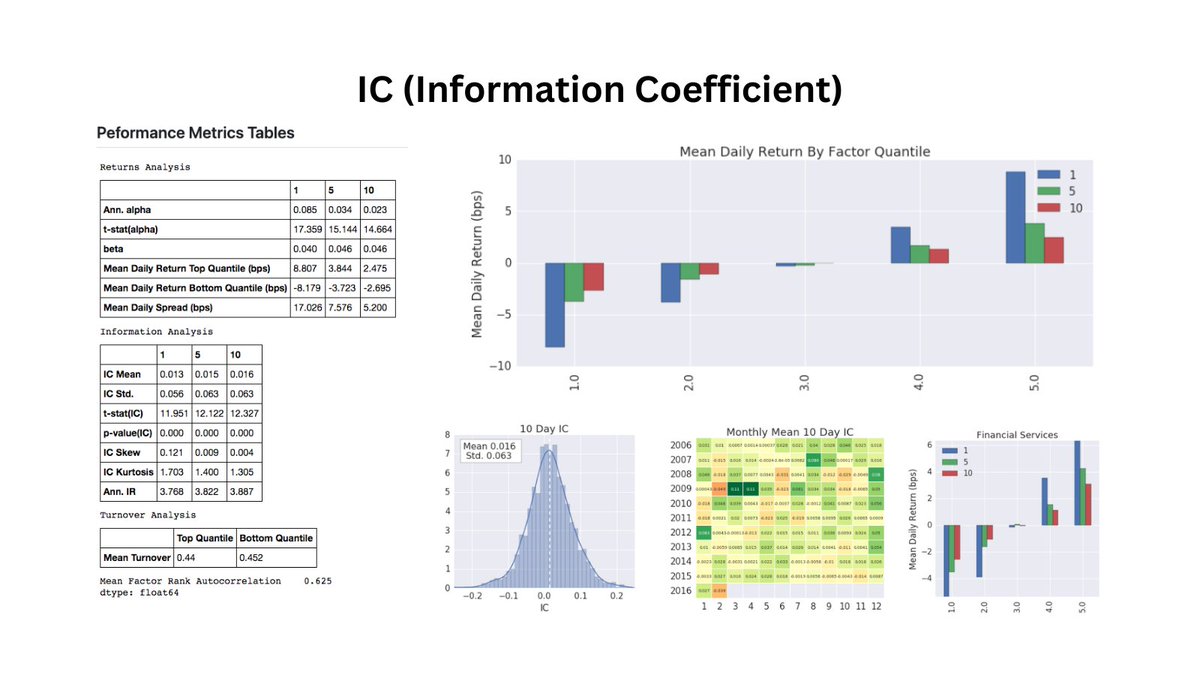
Factor investing is what made me stand out at JPMorgan.
But it took me years to master the information coefficient.
In 1 minute, I'll teach you the 10 things you need to know (that took me 1 year to learn).
Let's go:
English

Perplexity portfolio analysis feature coming soon. Nice!
Jeff Grimes@jeffgrimes9
Preview of personal portfolio integration and analysis coming soon to Perplexity Finance. The team is testing it this weekend.
English
@KanikaBK Ohhh, these are great, thanks for sharing Kanika.
English

