
Stan de La Comble
22 posts
Stan de La Comble
@StanDelacomble
Founding engineer at nao Labs
San Francisco Katılım Mart 2022
61 Takip Edilen9 Takipçiler
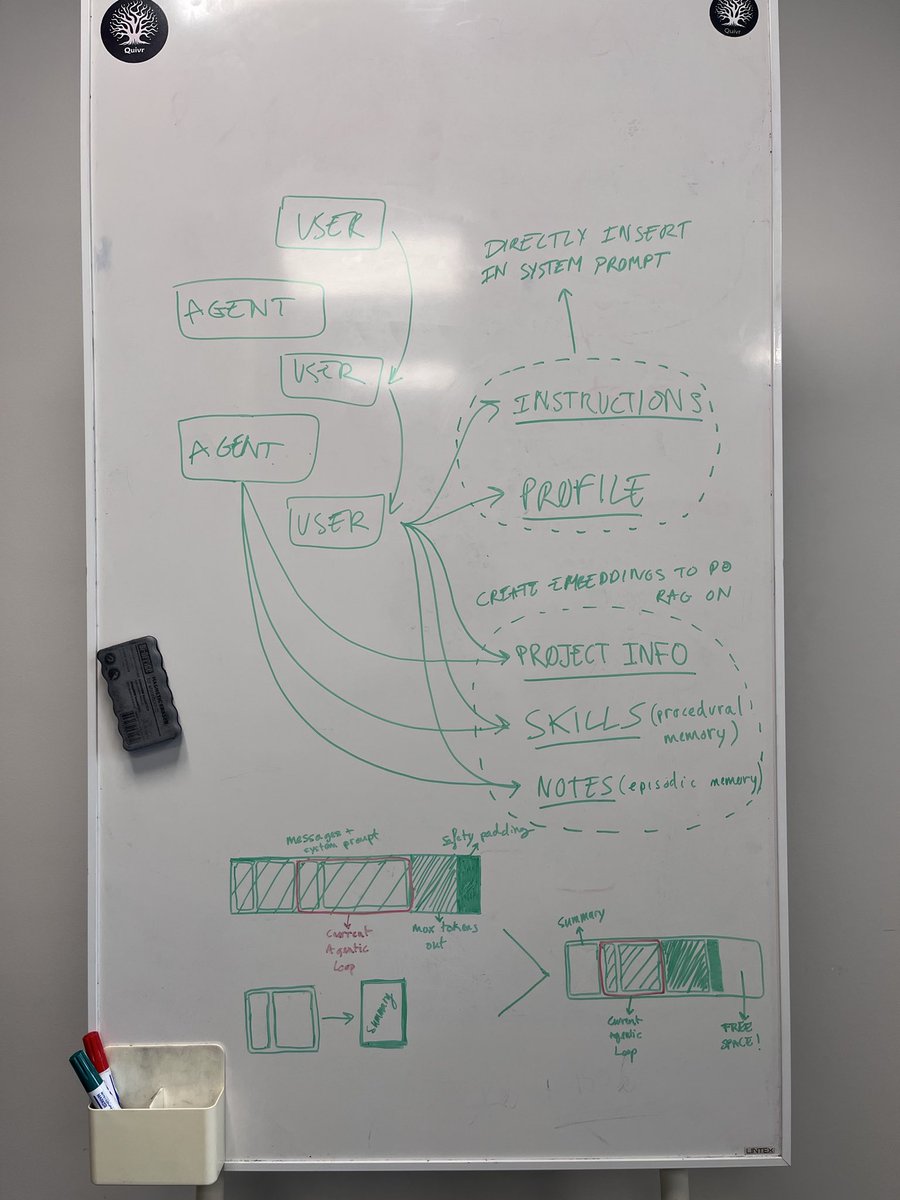


The Cursor CLI is so good and delightful to use🤯

San Francisco, CA 🇺🇸 English
@cursor_ai should spend a lot more time fixing their bugs. Recent updates have brought no improvements and only make the product worse. Might have to go back to zed.
English
@toolfolio @kanavtwt But antigravity is just windsurf...
English



Feels pretty good to use the very product you built to create new features and do data analysis. All in the same place, all in nao.

English
We're out on product hunt! Go share some love here producthunt.com/products/nao-2… ❤️
English
@mazeincoding The one with the highest number and least amount of words, of course
English

guys
what gpt-5 model should i use in cursor
gpt-5.1 codex
gpt-5.1 codex mini
gpt 5.1 codex high
gpt 5.1 codex fast
gpt 5.1 codex high fast
gpt 5.1 codex low
gpt 5.1 codex low fast
gpt 5.1 fast
gpt 5.1 high
gpt 5.1 high fast
gpt 5.1 low
gpt 5.1 low fast
gpt 5 codex high
gpt 5 codex fast
gpt 5 codex high
gpt 5 codex high fast
gpt-5.1
gpt 5 codex
gpt-5
gpt 5 fast
gpt 5 medium
gpt 5 medium fast
gpt 5 high
gpt 5 high fast
gpt 5 low
gpt 5 low fast
gpt 5.1 codex mini high
gpt 5.1 codex mini low
gpt-5-mini
gpt-5-nano
gpt-5-pro
thanks in advance
English
@viditchess Would a human be good at design if they blindly created components without seeing them, and see how they interact?
Give LLMs visual feedback and they’ll do a decent job.
English

@Kurdiumov @YishengJiang @Roberttjjif @theo What I mean is that logging the string 'response' after the actual response is horrifying
English

@StanDelacomble @YishengJiang @Roberttjjif @theo Probably. Should put some better text. My position is that code for demonstration should be runnable and insightful. Console log help with seeing results to some degree
English

There are at least 8 very questionable things happening in this code snippet
Amaan@amaan8429
require(“@google/genai”) Wow ☠️☠️
English
English

Has anyone benchmarked toon? I wonder if this format is less or more confusing for LLMs, especially with large data.
Sam@SamNewby_
just saw this on LinkedIn wtf is toon?
English

@iHarnoorSingh Cmd+tab to switch apps & cmd+backtick to switch windows is underrated. No need for stage manager.
English

Stage Manager is so underrated.. MacOS 26 makes is buttery smooth!
Helps me focus on one app at a time and declutters.
English
Soon, most apps will be reduced to MCP endpoints (except maybe for specialized editing software) and AI will become the main entry point to these services.
UX will live in a centralized chat: everything always converges.
English
@Rob3rtWozny @svpino The tab autocomplete is definitely not as good as Cursor’s.
English


@AndrewYNg I’d rather have a synchronous agent that’s excellent and carefully builds with critical thinking instead of a parallelized vibe coder.
English

Parallel agents are emerging as an important new direction for scaling up AI. AI capabilities have scaled with more training data, training-time compute, and test-time compute. Having multiple agents run in parallel is growing as a technique to further scale and improve performance.
We know from work at Baidu by my former team, and later OpenAI, that AI models’ performance scales predictably with the amount of data and training computation. Performance rises further with test-time compute such as in agentic workflows and in reasoning models that think, reflect, and iterate on an answer. But these methods take longer to produce output. Agents working in parallel offer another path to improve results, without making users wait.
Reasoning models generate tokens sequentially and can take a long time to run. Similarly, most agentic workflows are initially implemented in a sequential way. But as LLM prices per token continue to fall — thus making these techniques practical — and product teams want to deliver results to users faster, more and more agentic workflows are being parallelized.
Some examples:
- Many research agents now fetch multiple web pages and examine their texts in parallel to try to synthesize deeply thoughtful research reports more quickly.
- Some agentic coding frameworks allow users to orchestrate many agents working simultaneously on different parts of a code base. Our short course on Claude Code shows how to do this using git worktrees.
- A rapidly growing design pattern for agentic workflows is to have a compute-heavy agent work for minutes or longer to accomplish a task, while another agent monitors the first and gives brief updates to the user to keep them informed. From here, it’s a short hop to parallel agents that work in the background while the UI agent keeps users informed and perhaps also routes asynchronous user feedback to the other agents.
It is difficult for a human manager to take a complex task (like building a complex software application) and break it down into smaller tasks for human engineers to work on in parallel; scaling to huge numbers of engineers is especially challenging. Similarly, it is also challenging to decompose tasks for parallel agents to carry out. But the falling cost of LLM inference makes it worthwhile to use a lot more tokens, and using them in parallel allows this to be done without significantly increasing the user’s waiting time.
I am also encouraged by the growing body of research on parallel agents. For example, I enjoyed reading “CodeMonkeys: Scaling Test-Time Compute for Software Engineering” by Ryan Ehrlich and others, which shows how parallel code generation helps you to explore the solution space. The mixture-of-agents architecture by Junlin Wang is a surprisingly simple way to organize parallel agents: Have multiple LLMs come up with different answers, then have an aggregator LLM combine them into the final output.
There remains a lot of research as well as engineering to explore how best to leverage parallel agents, and I believe the number of agents that can work productively in parallel — like the humans who can work productively in parallel — will be very high.
[Original text, with links: deeplearning.ai/the-batch/issu… ]
English
I've tried Cursor, Windsurf, Kiro, Warp, Claude Code, etc.
They all have session-based chats but fail to provide a centralized and persistent agent whose knowledge and performance improve over time.
Crazy how the chat paradigm has stuck.
When will we break the cycle?
English