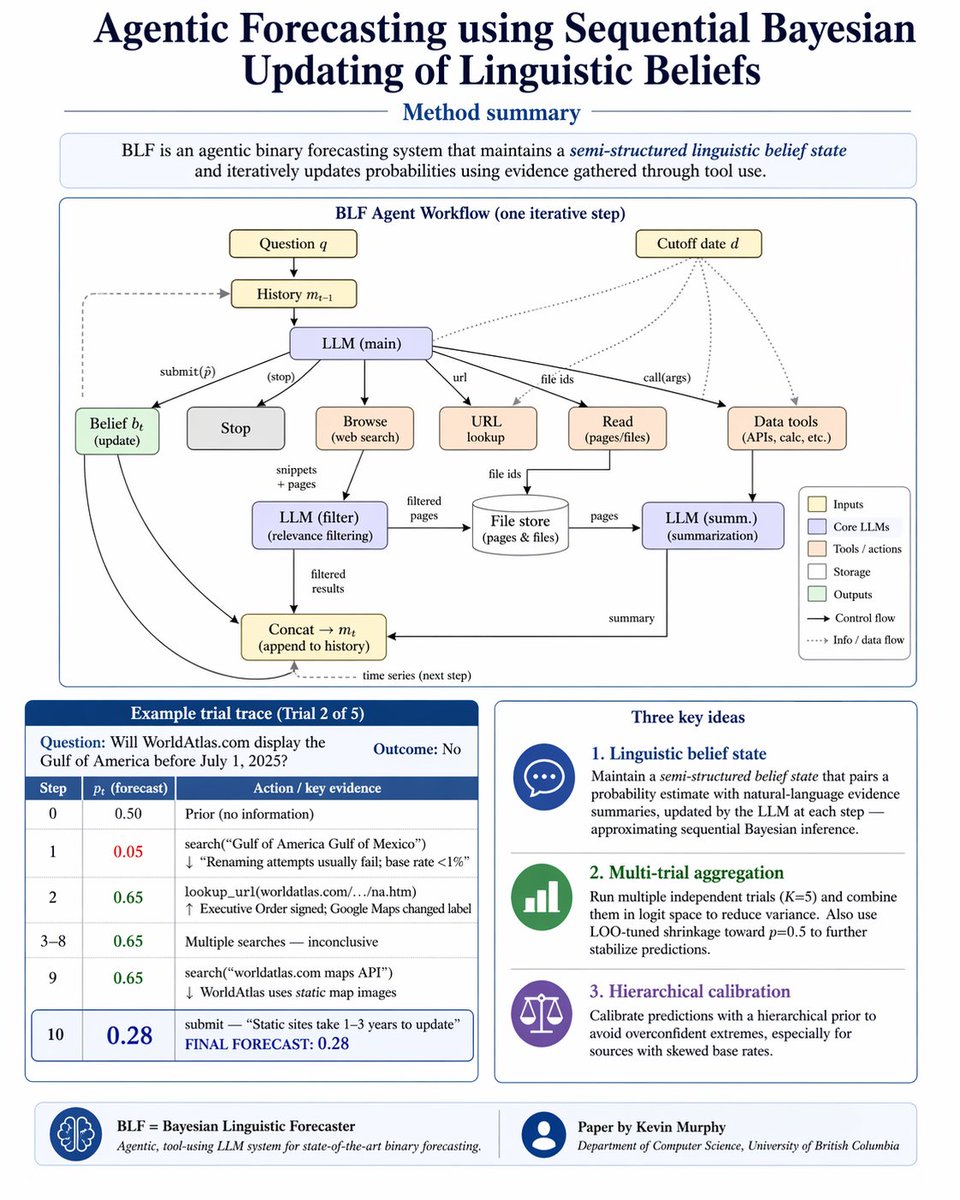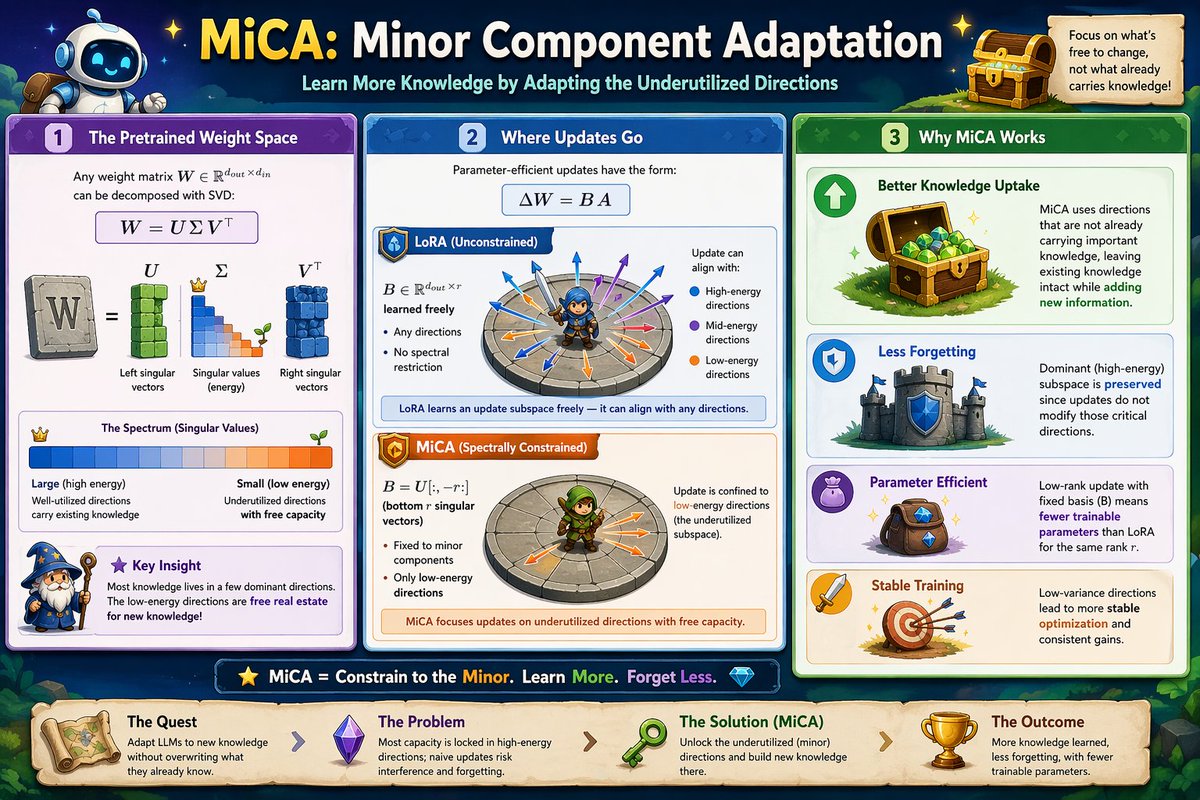
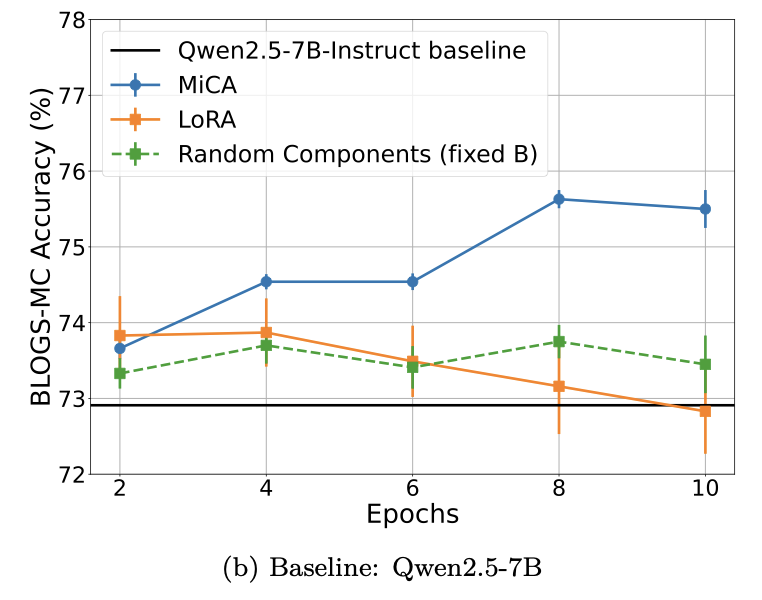
Sabitlenmiş Tweet

I’ve uploaded a new paper on arXiv (co-authored by @rasbt):
MiCA Learns More Knowledge Than LoRA and Full Fine-Tuning
In Parameter-Efficient Fine-Tuning, a key question may not just be how low-rank the update is, but *which* subspace we adapt.
English