@0xSero I am using ACP in Zed where I regularly switch between Zed, Pi, and Droid agents. Is that what you mean by Warp being a high-level “harness harness”?
English
0xSympathy
18 posts

@SympathyLabs
Quiet work. Learning the old magic — local weights, open source, patient hands



The goal of Personal AI: civilization where individual humans, augmented by AI, can do consequential work without being captured by extractive institutions. Freedom to write your prompt and own your data. This is the new battleground. 2034 won’t have to be like 1984.

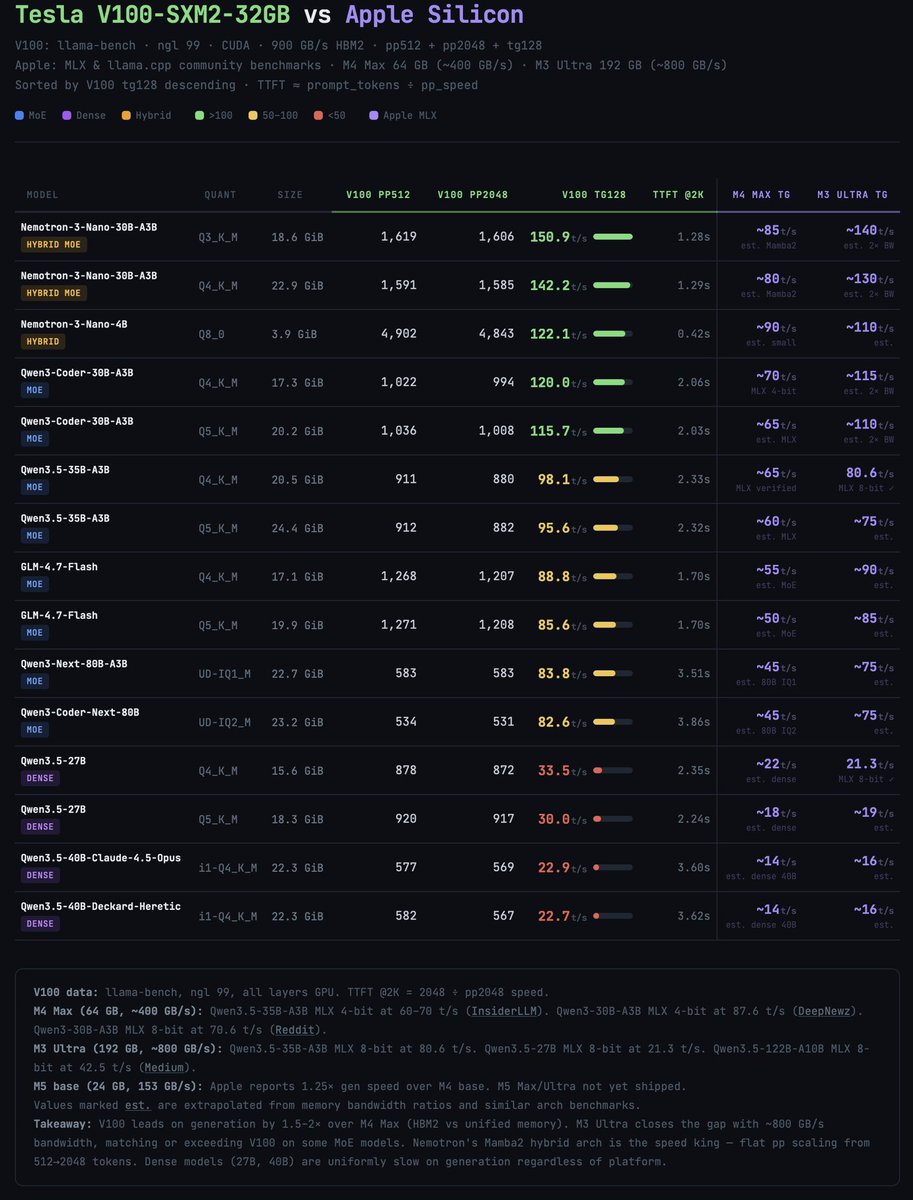
Just spoke with someone from NVIDIA's official Korean distributor. They mentioned an imminent $500 price hike is coming for the DGX Spark. Prices have already jumped, but they're about to go much higher. Also, Apple agreed to pay double in their latest supply deal with Samsung. Expect prices to absolutely skyrocket starting with the M6.

most of you don't know how big a deal it is that a single rtx 3090 from 2020 runs qwen 27b dense q4 with 256k context at 40 tok/s, full agentic loops on hermes agent, zero tool call failures. the more i build on this card the more i think nobody really knows how untapped it actually is. the silicon was always capable, the models finally caught up.


VVV emissions reduced from 6M to 5M tokens per year, effective today. This is the first of 3 monthly reductions: - May 1: 6M → 5M - June 1: 5M → 4M - July 1: 4M → 3M Our goal is a net deflationary VVV with native yield, where burns exceed emissions


.@MadrigalPharma is living in the (agentic) future. If you haven't heard of Madrigal, they are a pioneering biopharma company. Some months ago, they set out to solve the problem of integrating, searching, and synthesizing information from diverse datasets at scale. This lead to the creation of an enterprise multi-agent platform They wrote about their journey in a case study on our blog: langchain.com/blog/customers… My favorite part: highlighting observability as the step to close the gap between prototype and production. We see the importance of observability daily - to help give insights to debug and improve your systems. This iteration loop is a key part of building reliable agents, and I'm thrilled to share how Madrigal expertly used it