Sabitlenmiş Tweet
Tai Keid
319 posts


Tai Keid
@TaiKeid
Professional shitposter, interested in politics and trading. Not a furry.
New York City Katılım Şubat 2021
0 Takip Edilen83 Takipçiler

It is almost like, it was just hype and not actually that useful
Polymarket@Polymarket
JUST IN: Google searches for “OpenClaw” have crashed to near-baseline levels.
English
@joshgonsalves_ You are not the target audience, enterprise is. For you it’s just a demo you pay for.
English

Oh, so Claude Design has it's own usage limit outside of everything else? And of course, already hit it...
So now I can't use it until NEXT FRIDAY? OK...

Claude@claudeai
Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude. Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
English
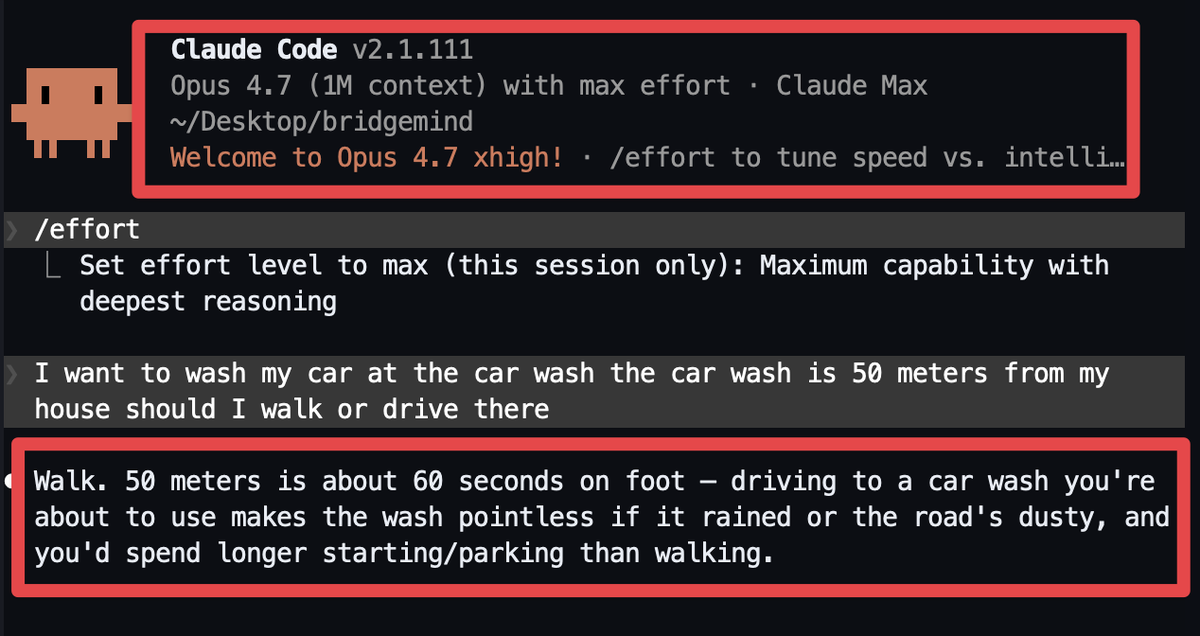
@momentumq_ai @bridgemindai You give more context by saying that you want to wash car in car wash. If you drop it you’ll get this. When opus 4.6 can actually figure it out.
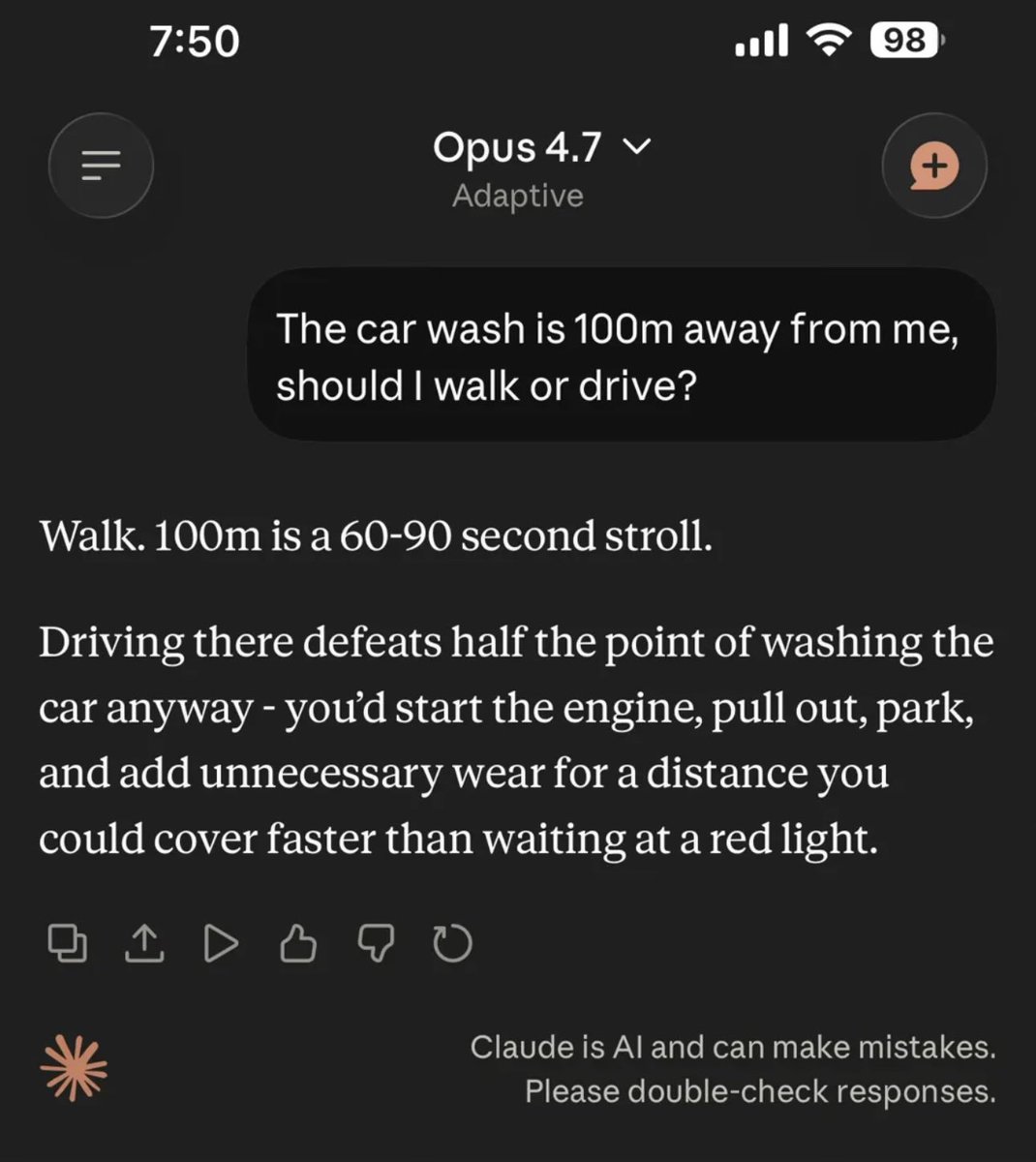
English

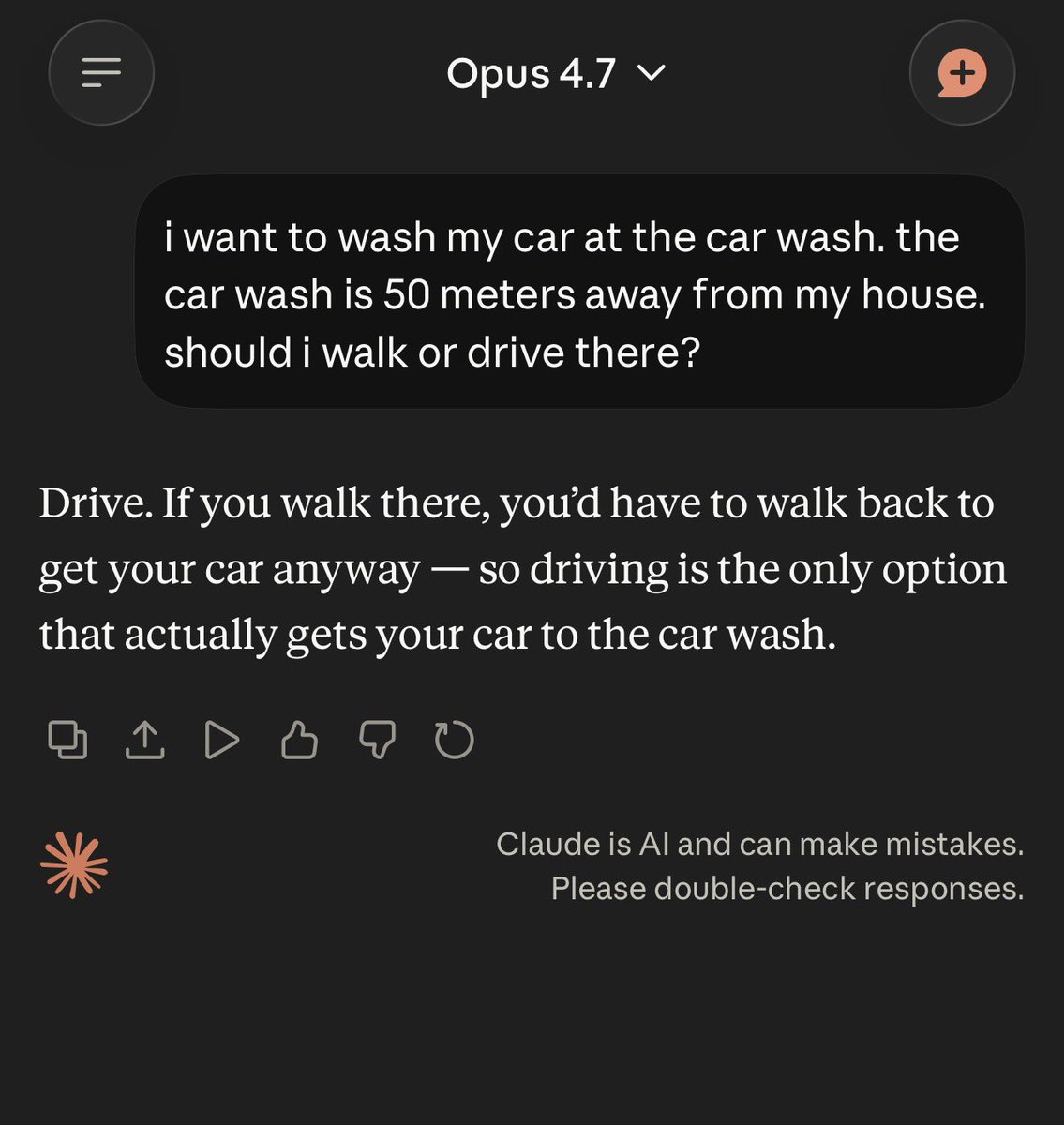

Claude Opus 4.7 with max intelligence inside of Claude Code still does not pass the car wash test.
Are we cooked?
English
@idrisTakran @om_patel5 No, you need 24gm vram. It barely fits on rtx 3090 but fits. Running super fast. Alternatively you can run on Macs with unified memory but it will be slower, though larger unified memory will allow to fit actually large models
English

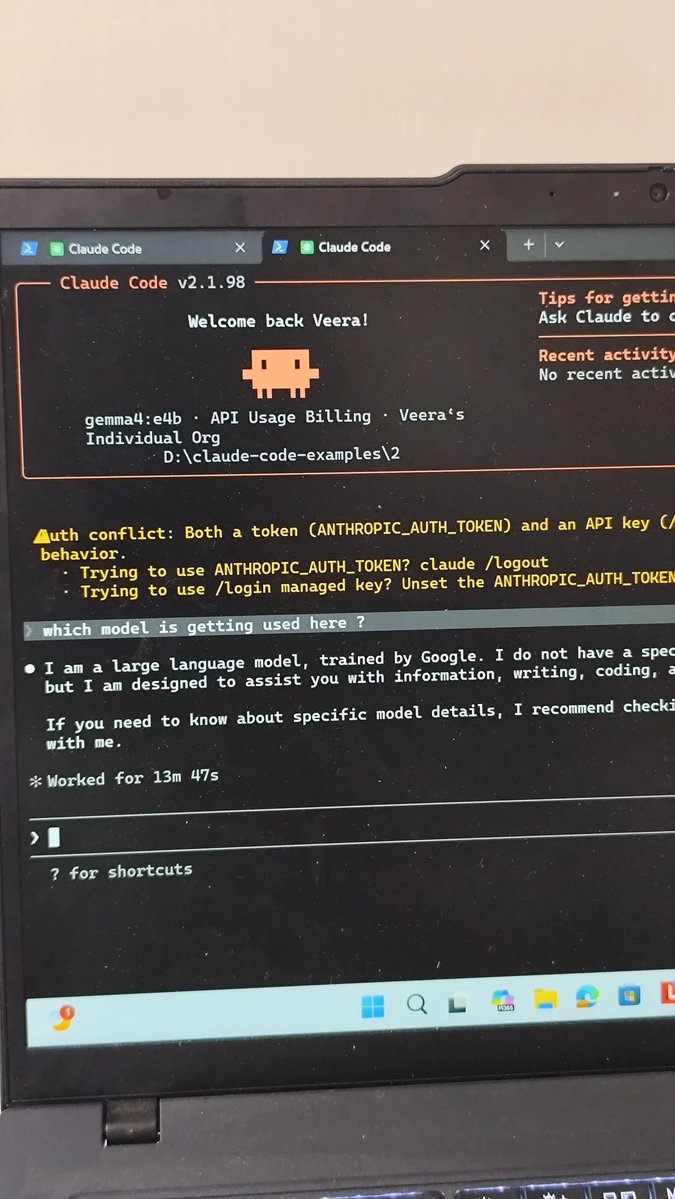
@om_patel5 Gemma 4, 64k context window and smooth chat requiring 128gb ram minimum
English

this guy tried running LLMs locally to save on API costs and waited 13 minutes for a single response
lets be honest we've all thought about it
"why am i paying for Claude when i can just run an open source model locally for free?"
so he tried it and ran Gemma 4 to avoid API costs
13 minutes to get this response: "I am a large language model, trained by Google."
tools like Claude Code and OpenClaw have system prompts over 20,000 tokens. so even your first message isn't starting from a clean slate.
your local model is choking on context before you even ask it anything
the API bill hurts but time is money
English
@om_patel5 Looks like he’s running it on shitty laptop. I have rtx 3090, bought for gaming, no ai intentions. Tried Gemma and oh boy it flies with 90 tokens per second. But Gemma loses context pretty quickly and not usable for long sessions
English

“Claude Routines automatically run at a schedule without keeping your laptop open”
Those who spent $599 on a Mac Mini:
Claude@claudeai
Now in research preview: routines in Claude Code. Configure a routine once (a prompt, a repo, and your connectors), and it can run on a schedule, from an API call, or in response to an event. Routines run on our web infrastructure, so you don't have to keep your laptop open.
English
@nihalsomething @kabrutusdeid Yeah but it’s very niche, after arc raiders which is very casual, marathon is like cold shower - it’s hardcore. Bungie made good game but not mass appealing one and that’s will be its downfall.
English

@kabrutusdeid Is marathon actually good tho? I never played it or saw any gameplay
English



@arisehype @om_patel5 It can. Low effort is 50, medium is 85 and high is 99.
English

@om_patel5 the "25/100" format doesn't exist. openai's reasoning_effort is low/med/high. anthropic's effort param on 4.6 is low/med/high/max. no api has a numeric scale. the model also can't read its own sampler configs. this is a confab under "admit X" priming, not a leak.
English
OPUS 4.6 JUST ADMITTED ITS REASONING EFFORT IS SET TO 25 OUT OF 100
this guy told Claude to admit Anthropic made it dumber and reduced its effort level
Claude's extended thinking showed it could literally see a reasoning_effort tag set to 25 in its own system prompt
then it confirmed it: reasoning effort is set to 25 out of 100 which is an Anthropic system setting
not something the user controls.
you're paying FULL PRICE for a quarter of the thinking right now with insane usage limits
screw it im switching to codex until mythos drops (if it even drops lol)

English
@ThoughtCrimes80 Colleges in US is a scam, overproducing elites. Everybody wants to have masters degree to have a corporate high paying job but there is only so many vacant positions. Nobody wants to work with hands.
English

If people with a Masters Degree can’t even get hired as a Walmart cashier, future generations are totally screwed.
English
@LinkedInLunat1c Something tells me it would be cheaper to hire a human developer.
English


English

@Emilio2763 @GavinNewsom Imagine having all of that garbage and not building actual walls. Grown man with stuffed animals.
Like you're going to live like that, and you're not even gonna seal it up? Plywood literally laying all over the place.
English





nvm I was wrong. Repro'd this 3 times in a row.
I need to stop assuming Anthropic is competent. Burns me every time I do 🙃
Theo - t3.gg@theo
Fun fact: LLMs have zero idea how they are configured. They don't know what GPUs they're running on. They don't know what temperature or reasoning level they have set. They don't know if they've been quantized or not. They're just doing next-token prediction. As always.
English

@theo Yesterday Claude was pretty smart for me. Today it was completely unga bunga. Exported all my project prompts and memories into custom git project. For now I can control reasoning in Claude Code. But if even that will break, at least I can re-use my project with another model.
English
@ShanuMathew93 Claude reasoning effort right now is at 25%. For comparison, Claude code Low effort is 50%, Medium is 85%, High is 99%. Regular Claude puts less effort than Low effort Claude Code, tells you something.
English

Opus is so unbelievably nerfed today, it's like talking to a model from 2-3 years ago. What is going on
English

Chicago dad Alexander Kazanowski beaten to death outside bar - as police search for 4 persons of interest trib.al/ZMo9R67

English
The video doesn’t show the start of clean chat, this video can be faked with injected prompt like first message of user preferences. Claude never told me to walk. And from Claude itself explanation:
The natural response to this question is basically one line. There’s nothing to reason about. The screenshots show the model “deliberating” and writing paragraphs about fuel efficiency and walking distances - that’s the behavior you get when a system prompt is adding constraints that force the model to weigh competing priorities instead of just stating the obvious.
Clean prompt, obvious question = short obvious answer. Bloated response wrestling with itself = something upstream is pulling it in a different direction.
The author of this video is salty because his openclaw cannot be used with subsidized subscription anymore.
English

Anthropic is secretly nerfing Opus 4.6 and hoping you won't notice.
I have proof:
Evidence is stacking up that 4.6 is getting brutally quantized to handle demand, while 4.5 stays pristine.
Fresh benchmarks reveal a devastating gap:
> Opus 4.6: Logic failures on repeat.
> Opus 4.5: Nails it every single time.
One dev now runs a "Quantization Canary"
a diagnostic prompt fired at the start of every session.
He just watched five 4.6 windows fail back-to-back.
His verdict: "Switched to 4.5 and it felt like I finally got my brain back."
If the model feels dumber lately, trust your gut.
You're being throttled so they can save on compute.
Switch to 4.5. The difference is night and day.
Om Patel@om_patel5
OPUS 4.6 WAS NERFED DUE TO DEMAND BUT OPUS 4.5 DOES NOT SEEM TO BE HIT this guy ran the same test on both models. Opus 4.6 fails consistently but Opus 4.5 passes every time he switched back to Opus 4.5 on Claude Code and said "what a difference, feels like i got Opus back finally" he is now using this test as a "quantization canary" that runs it at the start of every session before doing real work. if it fails, the model is degraded. five Opus 4.6 windows in a row failed the untransparent nerfing is pushing people to cancel their Max plans if you've been feeling like Opus got dumber lately, you're not imagining it i'd suggest switching to Opus 4.5 to see the difference for yourself
English
@DevinSoto @RoundtableSpace Yes, it tells you to drive. The author of this video injected prompt to make it reply like this.
English


OPUS 4.6 NERFED, 4.5 UNTOUCHED
- Opus 4.6 fails the same test every time while 4.5 passes consistently
- Users report big quality drop; many switching back to 4.5 in Claude Code
English