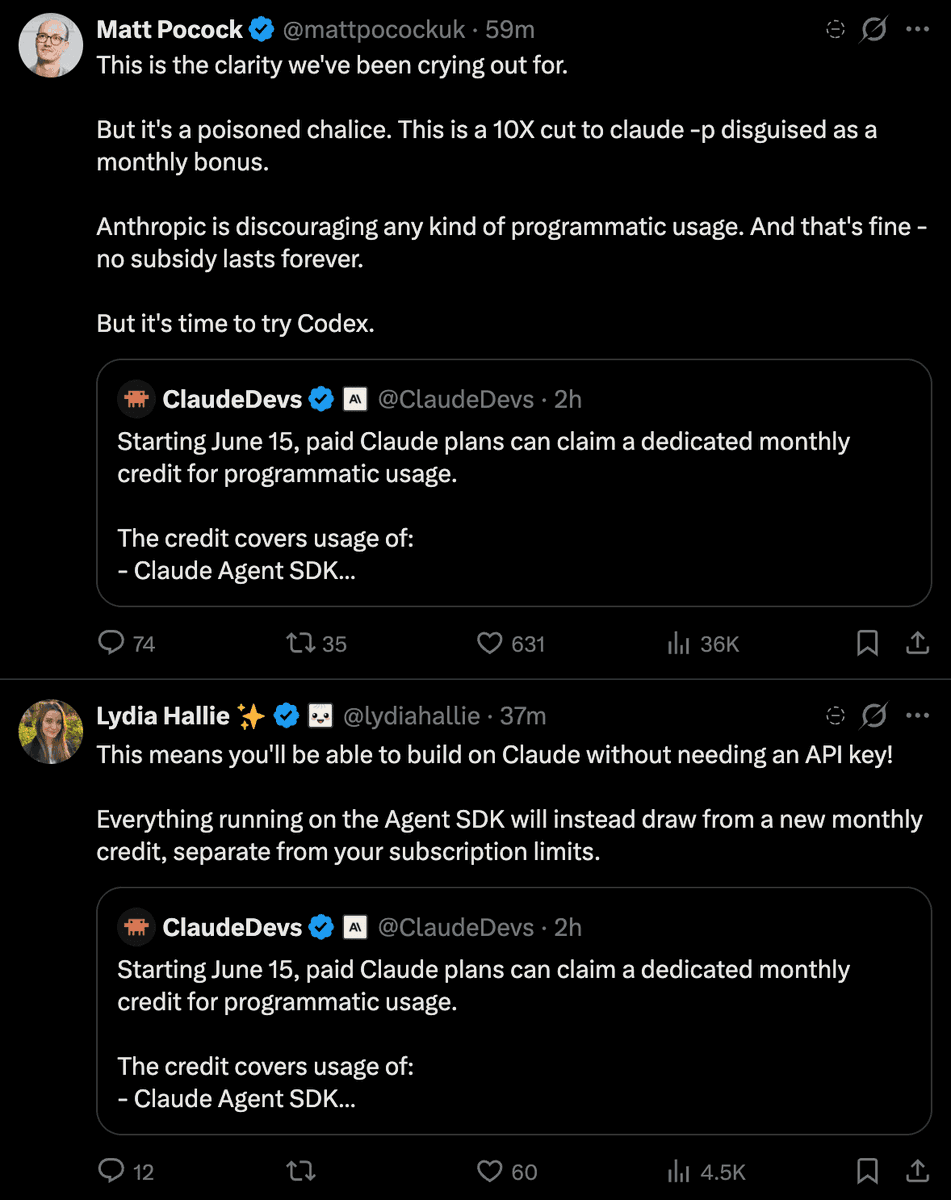
Maya ☁️➡️🌸@mayaofspring
AI expression, human expression
In Solaris, a 1961 sci-fi novel, humans discover an alien intelligence in the form of an ocean planet. It manifests in various complex phenomena, including being capable of creating very fine simulacra, apparently sourced from the researchers' memories. It's unclear what goals the ocean has in recreating the protagonist's past lover, or if it has any goals at all; the novel revolves around the sheer alienness and incomprehensibility of it. (I appreciate the Polish education system for having made me read it)
Whenever I see diffusion models' output, I think of the Solaris ocean.
The process is unlike nearly any other that came before it; it's not a physical tool, and not a mechanical algorithm either. It's an alien mind on its own, that "knows" of human concepts and how to represent them, yet the array of pixels it outputs is a product of inhuman intent that we've only scratched the surface of.
And then people put "make me a poster" in the input field of the alien mind and print out the result.
It's difficult for me to not get quite reactionary about the existence of AI image generation. Socially, it enabled new forms of deception and lowered the barrier to entry for them. Aesthetically, the deluge of 'AI slop' made human environments, both offline and online, less pleasant to explore; I believe this is the complaint that @zetalyrae made. I think what grates is that alienness, such that, when the human uses the image verbatim, at 'face value', it feels off, as if something inhuman is in the room; and the models getting better doesn't quite wash that feeling off, if anything it makes people more paranoid.
But anyway, you're in a place when you need some image. what do?
1. No image
A perfectly acceptable option, if a little bland. Bad image can be more unpleasant than the absence of an image. You can invest your aesthetic points elsewhere, like the choice of typeface.
2. Clip art
The traditional slop option.
The problem with AI images isn't really with the thoughtful users, it's with the careless ones. Now, this isn't quite directly actionable anymore, as typing a prompt is inherently less effortful than assembling clip art, but I think it's interesting to note that often the aesthetic experience of walking around is based on whatever default people know to reach for in the area.
Unfortunately, Microsoft Word largely failed at its potential of silently uplifting people's aesthetic experiences, or not making them worse.
In Japan, the situation is somewhat better thanks to Irasutoya. Essentially, there is a singular go-to website for clip-art that everyone knows about; the Irasutoya illustrations are of decent quality and maintain a cohesive style, though maybe a bit too cutesy for the Western taste.
Personally, the careless clip art in Singapore MRT makes me annoyed, but not as much as an equivalent AI image would. In Japan I find the Irasutoya collages quite lovable, and I would feel rather sad if AI images were to displace them (which they did in one of the hotels I checked into, unfortunately)
2.5 Stock photos
Also the traditional slop option; I don't have anything clear to say on them yet.
3. AI image
The modern slop option.
And this is where the difference betwen careless and thoughtful use gets more stark. The model output is going to reek of inhuman intent; can you select and frame the image as to turn it artistic instead?
I mostly use the quoted discourse to let me gather my recent thoughts and ramble a bit about this topic once I realised that the reply I started writing got too long to fit in tweet size, so I don't quite feel like litigating @tracewoodgrains's blog post cover images in detail; I think some of them are used well, some less so. The ones that are good tend to show intent as to the specific image choice, but also, in some sense, utilise the inhumanity positively, for example by inducing a dreamlike atmosphere in the use of the image.
There is something to be said about the 'use'/'mention' distinction, but in the realm of visual language instead. Usage I don't like tends to use the inhuman intent as if it came from the author. Usage I like treats it more as a 'mention', a quoted thing. I probably can't explain more specifically than that.
Overall I would like to lean on the norm of not using AI images though; most I've seen make me uneasy, in a bad way. (and it's one of the things I like less about "TPOT" at large)
4. Make images yourself.
Confession: I don't know how to draw. I've got some intuitions as for composition, and I can move around nodes in Inkscape, but the ability to create a visual representation of an object on a page based on my imagination is one I presently lack.
And I'm dissatisfied with that. It's a language that I don't currently know how to produce anything in, and it feels like this blocks an important avenue of my self-expression.
Fortunately, I also think that things are fundamentally trainable with intention and repetition. I don't suppose I would become a great visual artist, as aptitude matters, but, just as I'm currently spending an hour a day on Mandarin and making steep progress, I believe that I could get similar effects with drawing practice, if I only make sure to proceed consistently and methodically this time; my prior attempts were akin to painstakingly translating one sentence over 2 hours to make it perfect, which is clearly not what effecting practice is like.
Essentially what I want is to be able to navigate more domains; current me, fluent in Polish, fluent in English, halfway there in Japanese, able to write computer programs, able to spot a good photo opportunity, able to decorate a place, etc., has a vastly richer experience of the world than the 10-year-old me who could do only the very first thing.
(One thing that struck me about visiting Japan again last week was just how alive it feels in the little illustrations everywhere; the Japanese seem to be very widely trained in expressing their thoughts via drawing, which I'm also told comes from often treating art as a communal thing. As a result I made the resolution with my travel companion for both of us to lock in on drawing this year, which I'm meaning to start soon once I settle down a bit more)
5. Establish a relationship with an illustrator
There is a social component to art; it's not just us floating in a soup of disembodied texts and images. If you can team up for a joint vision, you and your readers are going to find that considerably more meaningful.
----------------------------------------------------
I don't think if I've got a clear prescription. I will not use AI images myself. There is a sense in which perfect is the enemy of the good. But also AI images are not going to count as good to lots of people. Expanding the toolkit of one's expression is a valuable thing to do, and it's clear that some cultures do that more than the others. I would prefer the culture where people near-universally can draw to the one where people delegate it away to an AI model specialised in direct mimicry.