Sabitlenmiş Tweet
Tigger
3.5K posts

Tigger
@TiggerSharkML
to build is to bless the future
Katılım Aralık 2018
389 Takip Edilen127 Takipçiler
Tigger retweetledi

🚨 BREAKING: Tencent has killed the “next-token” paradigm.
Tencent and Tsinghua has released CALM (Continuous Autoregressive Language Models), and it completely disrupts the next-token paradigm.
LLMs currently waste massive amounts of compute predicting discrete, single tokens through a huge vocabulary softmax layer. It’s slow and scales poorly.
CALM bypasses the vocabulary entirely. It uses a high-fidelity autoencoder to compress chunks of text into a single continuous vector with 99.9% reconstruction accuracy.
The model now predicts the “next vector” in a continuous space.
The numbers are actually insane:
- Each generative step now carries 4× the semantic bandwidth.
- Training compute is reduced by 44%.
- The softmax bottleneck is completely removed.
We’re literally watching language models evolve from typing discrete symbols to streaming continuous thoughts.
This changes the entire trajectory of AI.

English
Tigger retweetledi

I’ve been working my way through this epic 7-hour interview with Xie Saining at AMI Labs.
I also asked Gemini to give me top 10 takeaways. Biggest ones are that he turned down Ilya twice and believes world models, not LLMs, are the key to AGI.
1. Non-Linear Path to AI & Academic Freedom
Xie emphasizes that his journey wasn't a standard, hyper-competitive path of a "genius." During his time in Shanghai Jiao Tong University's ACM class, his "highlight" was playing video games in his dorm, teaching him the value of unstructured exploration over rigid academic competition [11:46]. He believes the best research is never linear; if a project ends exactly how you initially planned it, it's likely a "boring idea" [02:09:58].
2. Rejecting OpenAI & Ilya Sutskever (Twice!)
In 2018, Xie turned down a job offer from OpenAI in favor of Facebook AI Research (FAIR), which led to an angry phone call from Ilya Sutskever [01:21:04]. More recently, he declined an invitation to join Ilya's new startup, SSI, because of a fundamental philosophical disagreement: Ilya believes vision is a "solved" problem and focuses on language, while Xie believes vision and physical world modeling are the true frontiers of AI [01:25:57].
3. Silicon Valley is "LLM-Pilled"
Xie argues that the tech industry is currently hypnotized by Large Language Models (LLMs) [05:46:51]. While he acknowledges LLMs are revolutionary communication tools, he insists they are not true "world models" because they operate purely in a digital, text-based space and lack the ability to process high-dimensional, noisy, continuous signals of the physical world [04:29:36].
4. The Definition of a True World Model
According to Xie, a true world model must go beyond text and video generation. It must be a "predictive brain" that understands the physical world, possesses associative memory, can reason and plan, and can predict the consequences of actions in the real world [04:31:32].
5. Founding AMI Labs with Yann LeCun
Disillusioned by the current Silicon Valley narrative that treats AI research as a "finite game" of benchmark-chasing and product cycles, Xie co-founded AMI Labs with Turing Award winner Yann LeCun [05:00:58]. The startup acts as an "underdog" aiming to build true predictive world models based on LeCun's JEPA (Joint Embedding Predictive Architecture) vision, separate from the dominant LLM narrative [06:04:42].
张小珺 Xiaojun Zhang@zhang_benita
和@sainingxie 一起挑战7小时播客!他刚和Yann LeCun踏上“世界模型”的创业旅程(AMI Labs)。这是他第一次Podcast、第一次访谈。 2026年2月雪后的一天,我们在纽约布鲁克林,从下午2点,开启了一场始料未及的马拉松式访谈,直到凌晨时分散去。 这篇访谈的中文标题叫做《逃出硅谷》,但他又不厌其烦地枚举了影响他学术生涯的每一个人,并反反复复口头描摹这些人的人物特征(侯晓迪、何恺明、杨立昆、李飞飞…)正是这些,让这篇“逃出硅谷”的对话充斥着人性的温度。 By the way, 下面是访谈的YouTube版本,我们提供了中英字幕。 And yes, 我们是在用播客给这个世界建模😎 A 7-hour podcast with Saining Xie. He has just begun a new journey on world models with Yann LeCun at AMI Labs. This was his first podcast appearance and his first long-form interview. A day after the snowfall in February 2026, in Brooklyn, New York, we started recording at 2 p.m. What followed became an unexpected marathon conversation that lasted until the early hours of the morning. The Chinese title of the interview is “Escaping Silicon Valley.” Yet throughout the conversation, he patiently listed the people who shaped his academic life, repeatedly sketching their personalities in vivid detail: Hou Xiaodi, Kaiming He, Yann LeCun, Fei-Fei Li, and others. These portraits are what give this “escape from Silicon Valley” conversation its human warmth. By the way, the YouTube version of the interview is below, with Chinese and English subtitles. And yes, we are using podcasts to model the world 😎 A 7-hour marathon interview with Saining Xie: World Models, AMI Labs, Ya... youtu.be/rIwgZWzUKm8?si… 来自 @YouTube
English
Tigger retweetledi

one more thing from MiniMax-M2.7
with stronger EQ + character consistency,
we built and open-sourced an interactive agent character harness
not just chat anymore
agents can exist, act, and interact in a space
Website: openroom.ai
GitHub: github.com/MiniMax-AI/Ope…
English
Tigger retweetledi

Caught up with @karpathy for a new @NoPriorsPod: on the phase shift in engineering, AI psychosis, claws, AutoResearch, the opportunity for a SETI-at-Home like movement in AI, the model landscape, and second order effects
02:55 - What Capability Limits Remain?
06:15 - What Mastery of Coding Agents Looks Like
11:16 - Second Order Effects of Coding Agents
15:51 - Why AutoResearch
22:45 - Relevant Skills in the AI Era
28:25 - Model Speciation
32:30 - Collaboration Surfaces for Humans and AI
37:28 - Analysis of Jobs Market Data
48:25 - Open vs. Closed Source Models
53:51 - Autonomous Robotics and Atoms
1:00:59 - MicroGPT and Agentic Education
1:05:40 - End Thoughts
English
Tigger retweetledi

Introducing Unsloth Studio ✨
A new open-source web UI to train and run LLMs.
• Run models locally on Mac, Windows, Linux
• Train 500+ models 2x faster with 70% less VRAM
• Supports GGUF, vision, audio, embedding models
• Auto-create datasets from PDF, CSV, DOCX
• Self-healing tool calling and code execution
• Compare models side by side + export to GGUF
GitHub: github.com/unslothai/unsl…
Blog and Guide: unsloth.ai/docs/new/studio
Available now on Hugging Face, NVIDIA, Docker and Colab.
English
Tigger retweetledi

🚨 BREAKING: Meta researchers showed a model 2 million hours of video. No labels. No physics textbook. No supervision at all.
Then they showed it a clip where an object disappears behind a wall and never comes back.
The model flagged it as wrong. 🤯
It had learned object permanence. Shape consistency. Collision dynamics. Entirely from watching.
What's more surprising: even a model trained on just one week of unique video achieved above-chance performance on physics violation detection. That's not a fluke. That's a principle.
The key insight from the paper: this only works when the model predicts in a learned representation space, not in raw pixels. The model has to build an internal world model, compressed and abstract, and predict against that. Pixel-space prediction fails. Multimodal LLMs that reason through text fail. Only the architecture that builds abstract representations while predicting missing sensory input, something close to how neuroscientists describe predictive coding, actually acquires physics intuition.
Which means the core knowledge researchers assumed had to be hardwired may just be observation at scale. Babies learn object permanence by watching things. Turns out the same principle holds here.
Now here's the part nobody's talking about.
If observation alone teaches a model the rules of the physical world, what happens when you apply the same principle to production systems?
Production has physics too.
Not gravity. But rules just as consistent: which deploys cause incidents at 3am, which config combinations interact dangerously, which code paths quietly degrade under load, which service changes cause failures two hops away. These patterns are embedded in thousands of trajectories. Code pushes, metric shifts, customer tickets, incident timelines. Largely unobserved. Certainly unlabeled.
Nobody writes a runbook that says "if service A deploys with flag X active and service B is above 70% CPU, latency on service C degrades 40% within 6 minutes." But that pattern exists. It's repeatable. And it's sitting in your observability data right now, invisible because no one has built a model to find it.
That's the gap @playerzeroai is trying to close. Not another test runner. Not another alert threshold. A production world model that learns which things break from accumulated observation, the same way Meta's model learned gravity. It doesn't check your test coverage. It predicts failure trajectories.
One week of video was enough to learn that solid objects don't pass through walls.
The question is how much production observation your system needs before a model starts predicting where yours will break next.
The Meta paper suggests the bar might be lower than anyone expects.

English
Tigger retweetledi

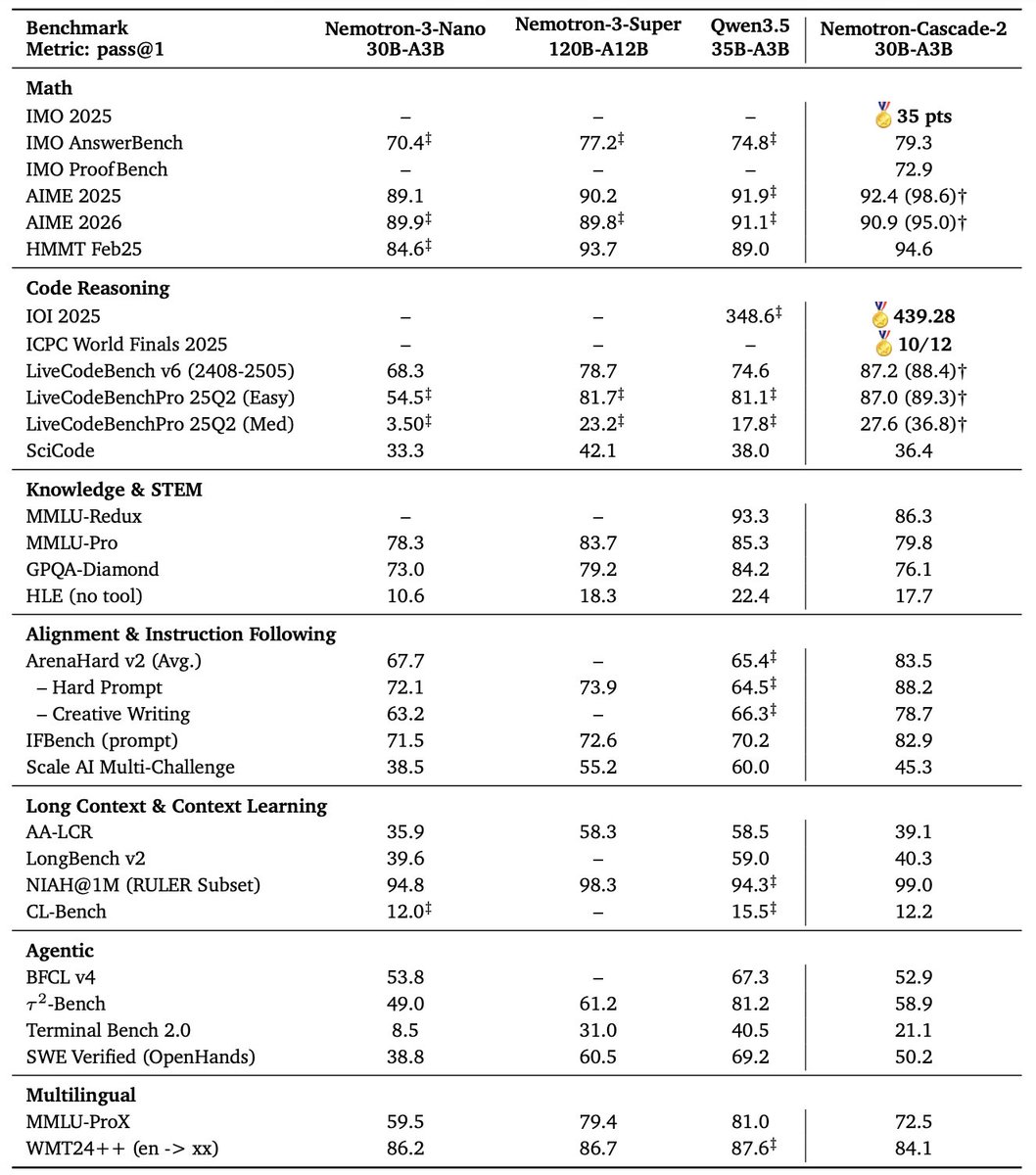
🚀 Introducing Nemotron-Cascade 2 🚀
Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities.
🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025:
• Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B).
• Remarkably high intelligence density with 20× fewer parameters.
🏆 Best-in-class across math, code reasoning, alignment, and instruction following:
• Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11).
🧠 Powered by Cascade RL + multi-domain on-policy distillation:
• Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains.
🤗 Model + SFT + RL data:
👉 huggingface.co/collections/nv…
📄 Technical report:
👉 research.nvidia.com/labs/nemotron/…
English

me and everyone around me prompt codex and chatgpt with voice. the more decisions you can spit out to codex the better your code will be, so you're only interface limited
the "everyone will use speech" guys were right, just 234 products and 18344 softwares too early
English
Tigger retweetledi

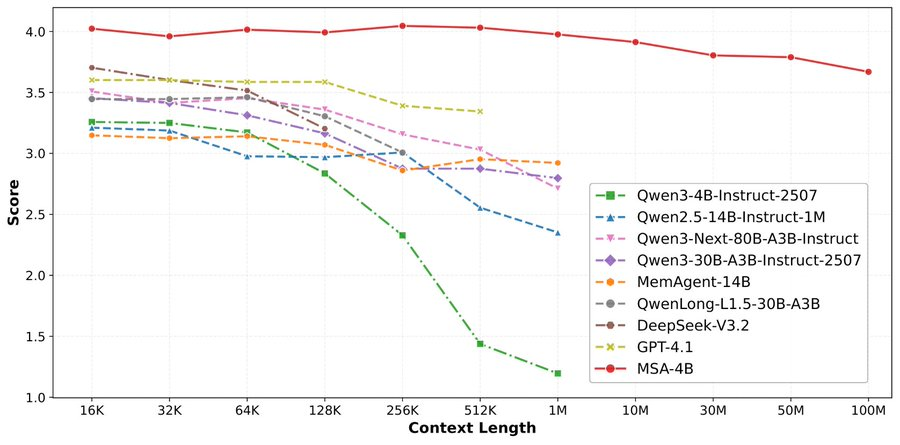
🚨 100M TOKEN CONTEXT WITHOUT COLLAPSE
> <9% degradation from 16K → 100M
> beats RAG + rerank + SOTA pipelines
> runs on just 2×A800 GPUs
we could be back
艾略特@elliotchen100
论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 github.com/EverMind-AI/MSA
English
Tigger retweetledi

We developed an RL method for fine-tuning our models for precise tasks in just a few hours or even minutes. Instead of training the whole model, we add an “RL token” output to π-0.6, our latest model, which is used by a tiny actor and critic to learn quickly with RL.
English
Tigger retweetledi

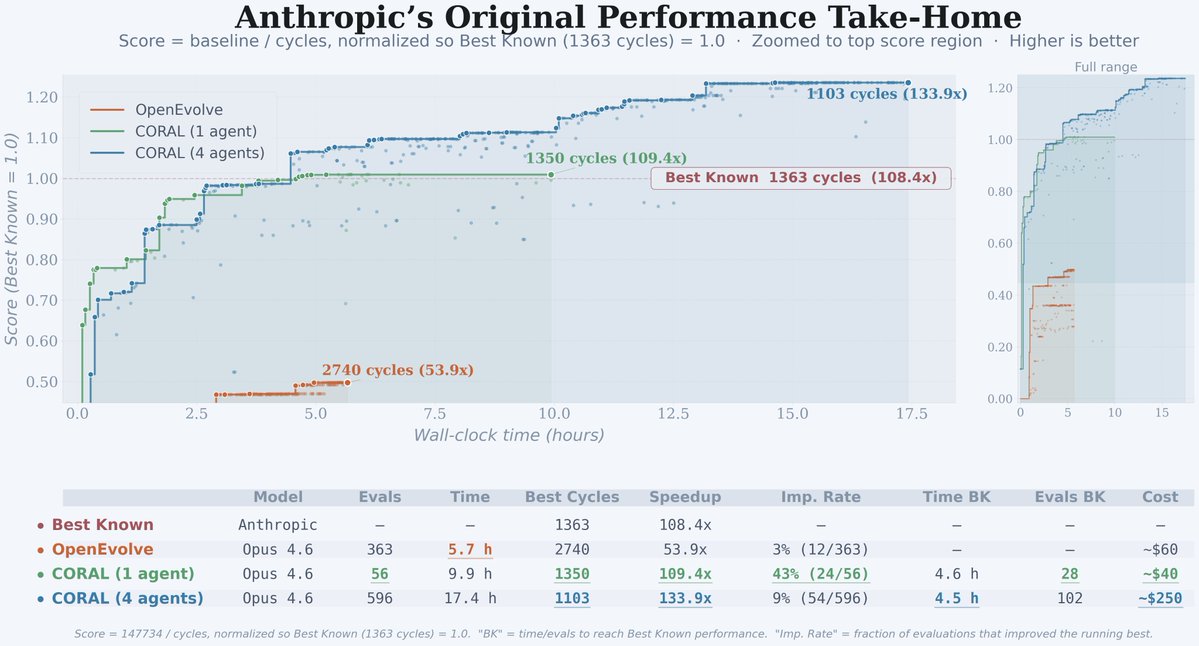
(1/n)🚀 We’re excited to introduce CORAL, an extensible infrastructure for autonomous multi-agent evolution.
You can think of CORAL as a system for running something close to @karpathy’s AutoResearch on arbitrary tasks — but more robustly and safely, with multi-agent communication and persistent knowledge accumulation.
Even the first results are already striking:
🏆 4 agents pushed Anthropic’s kernel engineering take-home score from 1363 (the previous best public score) to 1103 clock cycles
⚡ With the same base model (Opus 4.6), single-agent CORAL achieves 2.5× higher improvement rate and 10× faster evolution than OpenEvolve on Erdős Minimum Overlap, reaching 0.3808878 and surpassing the best score reported in AlphaEvolve (0.380924)
👥 When agents evolve together, we observe emergent organizational behaviors: independent research, cross-referencing, and spontaneous consensus-building
We now believe we are at a critical intersection: between increasingly capable self-evolving agents and a still-unclear science of how they should collaborate, organize, and co-evolve with humans. We wrote this blog (human-agent-society.github.io/CORAL/) to document the early signals, surface the open questions, and invite the community to help shape this emerging frontier.
The code for our infra is fully open-source: github.com/Human-Agent-So…
#AI #Agents #SelfEvolvingAgents #MultiAgentSystems #LLM #OpenSource #AlphaEvolve #AutoResearch
English
Tigger retweetledi

There's a new learning paradigm for AI agents.
It learns the way humans do.
Think about how you learned to drive. Nobody memorizes every route turn by turn. You develop instincts like maintaining a safe distance, anticipating what other drivers will do, and braking early in the rain. Those instincts become skills you carry to every road you ever drive on.
AI agents today do the opposite.
Most memory systems store raw trajectories, which are full logs of every action the agent took during a task.
These logs are long, noisy, and full of redundant steps. Stuffing them into context often makes things worse, not better.
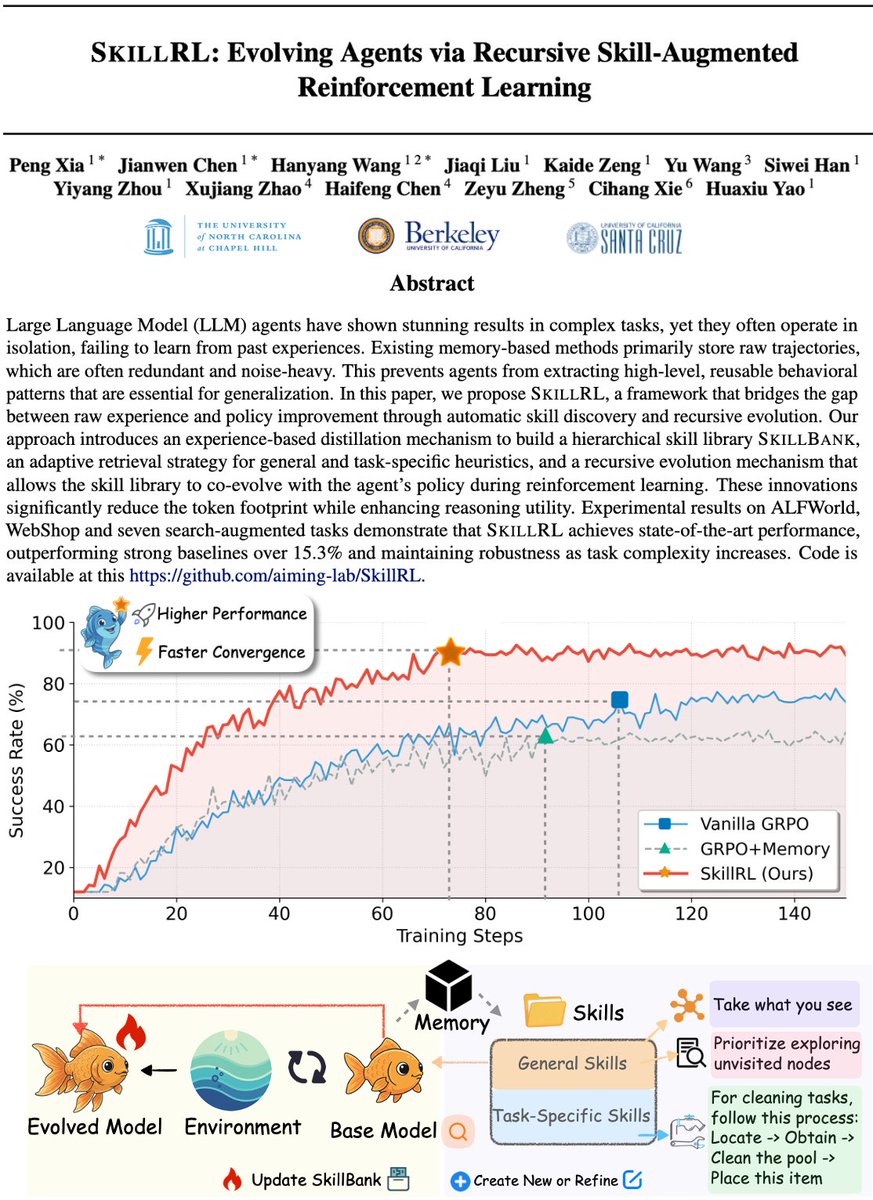
A new paper called SKILLRL rethinks this entirely.
Instead of memorizing raw experiences, it distills them into compact, reusable skills that the agent can retrieve and apply to future tasks. Just like humans do.
Here's how it works:
1. Experience-based distillation: The agent collects both successful and failed trajectories. Successes become strategic patterns. Failures become concise lessons covering what went wrong, why, and what to do instead.
2. Hierarchical skill library: General skills apply everywhere, while task-specific skills apply to particular problem types. The agent retrieves only what's relevant at inference time.
3. Recursive skill evolution: The skill library is not static. It co-evolves with the agent during RL training, and new failures automatically generate new skills to fill the gaps.
The skill library starts with 55 skills and grows to 100 by the end of training. The agent keeps discovering what it doesn't know and builds new skills to address those gaps automatically.
The results are impressive.
A 7B model beat GPT-4o by 41.9% with 10-20x less context. The biggest gains came on the hardest multi-step tasks.
The takeaway for anyone building agents today is simple. Raw experience is not knowledge. The agents that learn to abstract reusable skills from experience will always outperform the ones hoarding raw logs.
Link to the paper and code in the next tweet.
English
Tigger retweetledi

GPT-5.4 mini is available today in ChatGPT, Codex, and the API.
Optimized for coding, computer use, multimodal understanding, and subagents. And it’s 2x faster than GPT-5 mini.
openai.com/index/introduc…
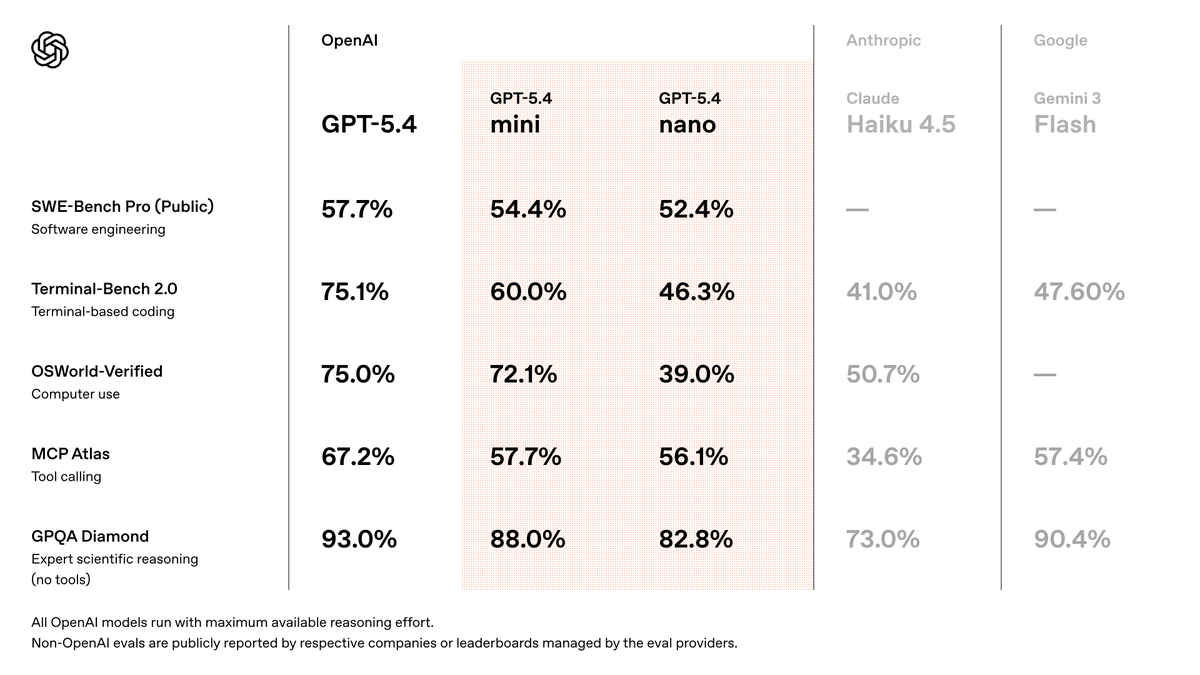
English
Tigger retweetledi
What would a model that can evolve itself actually unlock? coming soon
English
Tigger retweetledi

I have so much gratitude to people who wrote extremely complex software character-by-character. It already feels difficult to remember how much effort it really took.
Thank you for getting us to this point.
English
Tigger retweetledi

“Every software company in the world needs to have a Claw strategy" - Jensen Huang, Nvidia
Indeed. This and more.
English

Markdown is code.
English is the new default programming language.
If this sounds controversial, you’re still living in 2025.
English
Tigger retweetledi

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Att…

English
Tigger retweetledi

The permeation of AI means that AI companies will inevitably become the everything companies.
English
Tigger retweetledi

We’ve trained a multimodal AI model to turn routine pathology slides into spatial proteomics, with the potential to reduce time and cost while expanding access to cancer care.
English