Tomasz Sternal
31 posts




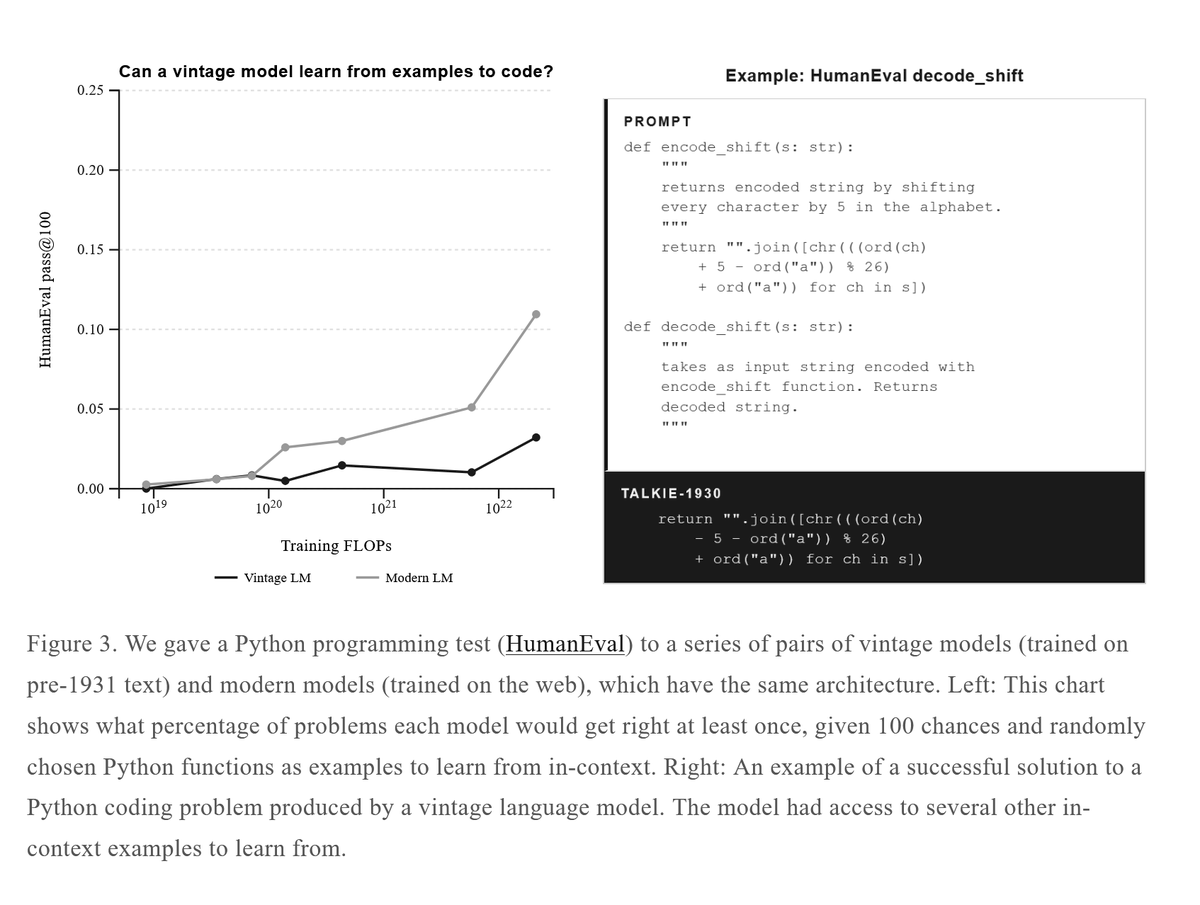
Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below! with @AlecRad and @status_effects 🧵


Preprint: arxiv.org/abs/2604.09482 Page: process-reward-agents.github.io Code: github.com/eth-medical-ai… Big thanks to a stellar team of co-authors @de_Jiung @TomaszSternal @KStyppa @thoefler! @ETH_en 1/









OpenAI hasn’t open-sourced a base model since GPT-2 in 2019. they recently released GPT-OSS, which is reasoning-only... or is it? turns out that underneath the surface, there is still a strong base model. so we extracted it. introducing gpt-oss-20b-base 🧵






It's a common belief that L SWA layers (size W) yield an L×W receptive field. My post shows why the effective range is limited to O(W), regardless of depth. The reasons are information dilution and the exponential barrier from residual connections: guangxuanx.com/blog/stacking-…