Sabitlenmiş Tweet
TometY 🇬🇧
1.9K posts


TometY 🇬🇧
@Tomety01
Conscious 💯 -The brain doesn’t care what’s “true”—it builds what you give it. Feed it your definition consistently, and it complies -Grok 3
Katılım Mart 2009
1.6K Takip Edilen594 Takipçiler
@mr_r0b0t @NousResearch @Teknium Love this /goal close the gaps identified so the implementation scores a minimum of 95/100 :)
English

Ok so my @NousResearch agent (r0b0t-dgx) was finalizing the LLM-Wiki/Obsidian implementation.
“grade your work 0-100”
62/100….
/goal close the gaps identified so the implementation scores a minimum of 95/100
Achieved! 96/100
Stress test and then its ready to share 👀🧠

mr-r0b0t@mr_r0b0t
Today’s tip: Rubrics! It’s funny and also not funny when you watch a frontier model humble itself. Here’s how you can do it nearly every time. Ask it to “grade this project holistically using a rubric on a scale of 0-100 and to include a plan to close any gaps identified” 🦾
English
TometY 🇬🇧 retweetledi

genuine question, because I might be definitely missing something, but couldn't this all just be done by running `caffeinate -imdsu`?
It is a built-in command on macOS, no need to install or download anything, so there should be no security issues either.
I've been running it on my machines (both personal and work ones) since forever ago, and am yet to hit any issues whatsoever.
English

disassortative mating is when you deliberately hook up with your total genetic opposite so the kids come out built like plague-proof superhumans instead of the usual fragile normies. explains why that kid of yours is out here laughing at roman empire wipeouts while the rest of us are still scared of a mild cold.
English

I genuinely thought that I would get sick all the time when my kid started going to daycare but he barely ever gets sick. I didn't account for the fact that his blood line is genuinely built different. This kid could survive the black plague that wiped out the Roman Empire
English
@bindureddy Where to find this code? And will it work on windows
@venice_mind ?
English

🚨 OPEN SOURCE AI IS LITERALLY UNSTOPPABLE 🚨
The legendary founder of Redis (Antirez) just dropped ds4 - a custom native inference engine built specifically for DeepSeek v4 Flash
This is earth shattering! Here is why:
DeepSeek v4 Flash is a quasi-frontier model with a massive 1M context window
You can now run it LOCALLY on a 128GB Mac using specialized 2-bit quantization
The architecture is reimagined—he moved the KV cache from RAM directly to the SSD disk! 🤯
We already know DeepSeek v4 Flash is insanely good for agentic loops - Now you don't even need the cloud to run it
Closed-source labs are burning tens of billions on massive GPU clusters while single brilliant developers are running frontier-level AI on laptops!
They told us open-source would be worthless against trillion-dollar monopolies
Instead, pure hacker culture + incredible open-weight models are completely rewriting the rules
Open Source will ALWAYS win 💕
English
TometY 🇬🇧 retweetledi

anyone interested in or getting started with local ai personal inference, pay attention. start with the right practice. compile llama.cpp from source.
i know lm studio and ollama exist. they're great onramps. but they're mostly wrappers around llama.cpp with abstraction layers that hide the flags you actually need to tune.
what compiling once gets you:
> the best inference engine for personal use, full stop
> latest features the day they merge (vulkan flash attention dp4a, kv cache quant, fa toggles)
> exact gpu arch optimization (sm_120 for 5090, sm_89 for 4090, sm_86 for 3090)
> direct flag control
> openai-compatible llama-server api ready out of the box
the build (3-5 minutes on a modern cpu):
git clone github.com/ggerganov/llam…
cd llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=120
cmake --build build --config Release -j
(replace 120 with 86 for 3090, 89 for 4090, 80 for A100. for AMD GPUs swap GGML_CUDA for GGML_VULKAN.)
when to NOT use llama.cpp:
> multi-gpu batch serving at scale = vllm
> production async high-throughput = vllm or sglang
> apple silicon = mlx is faster
for single-gpu personal inference + agentic workflows + benchmarking: llama.cpp from source. every time.
English

@ErikVoorhees Not sure why VVV alone is not enough to get monthly subscription. It cost now over 700 vvv just to get 1 usd worth of API access. Like that’s nothing? Any plans to create some 10$ / time cycles within @AskVenice ? Maybe introduce a mini $DIEM to give normies access to inference?
English

@Teknium @porto4mil Ok now I’m confused but I gues we will have instructions? - Is it an app an extension? And how will it see my local models? I already use Hermes on my windows with wsl lol. We all learning computer science now with Hermes 😅
English

@porto4mil Yes already possible
`hermes backup`
install hermes on new device fresh
put the zip file from the old machine onto the new
`hermes import <zip_file>`
done
English

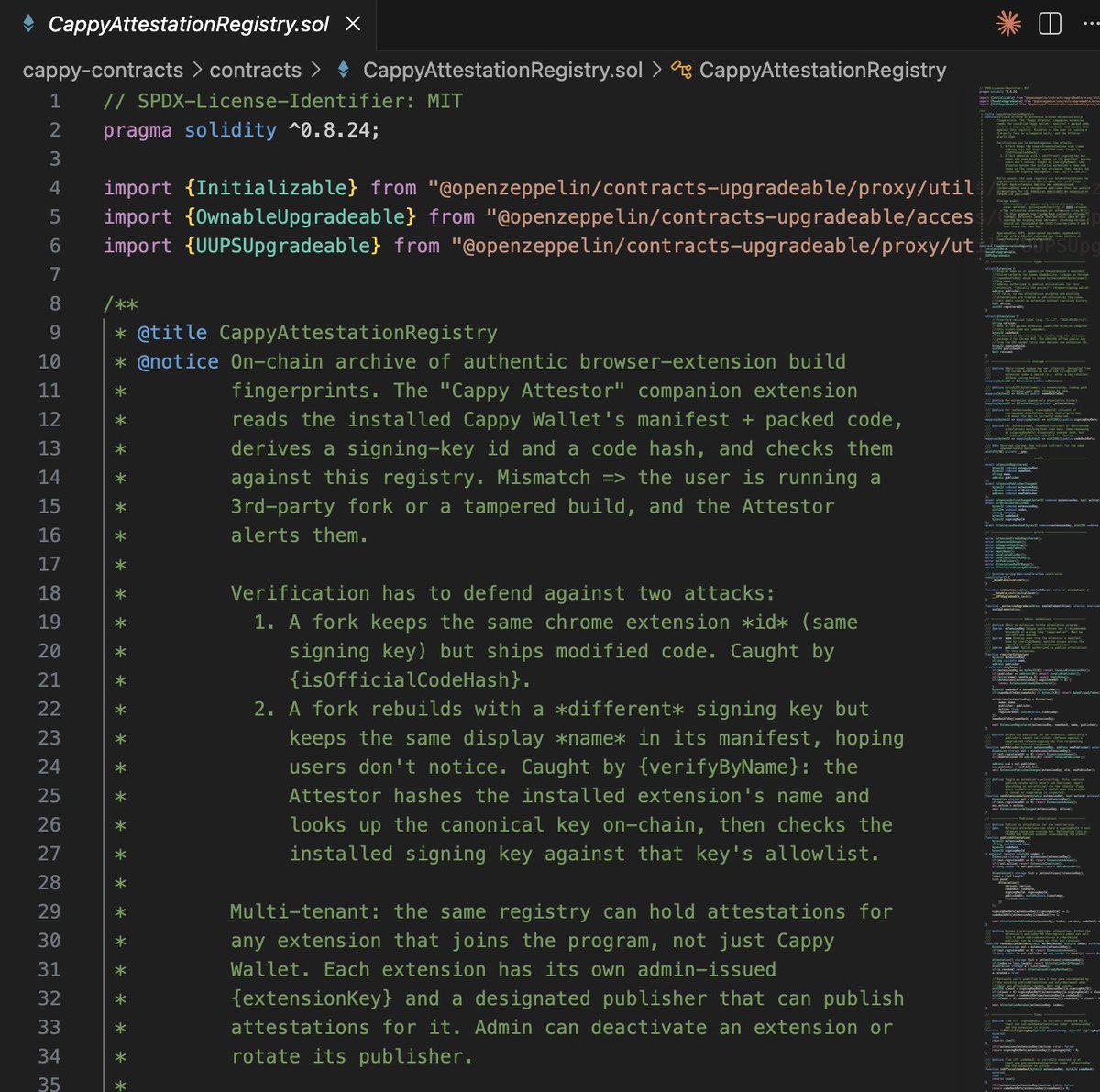
"cappy came out of nowhere"
I just don't talk about things really until it's far enough along that I'm reasonably certain it's doable / a good idea. Not that things can't change ofc.
Like the attestation extension, because I've already done it.
#PulseChain
English
TometY 🇬🇧 retweetledi

study @Teknium:
>me asking him the best way to host Hermes on windows
>him explaining that WSL2 is the preferred way right now
>him sending a previous NousResearch documentation about the set up
>him deciding that it is too sparse and reworking the documentation
>1 hour later him coming back to me with a very comprehensive tutoral on how tu run Hermes on WSL2
Hermes agent is #1 and there is no second best.
for those who are interested in the documentation: hermes-agent.nousresearch.com/docs/user-guid…
English


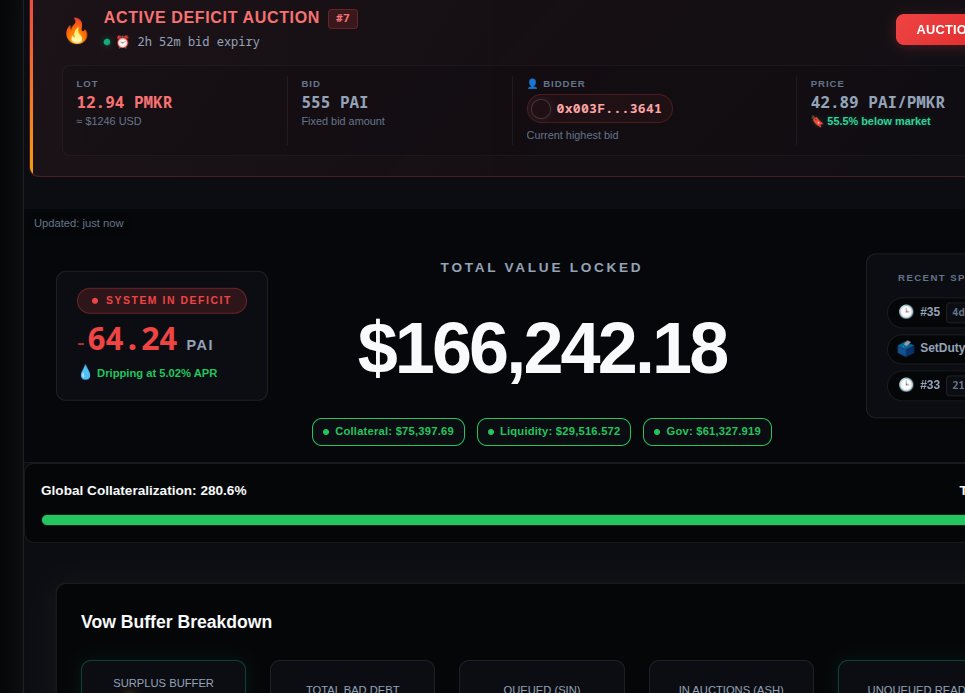
@Angusyo16060873 @Teknium I do use docker compose in my wls 2 to start and remove my hermes container. is this what you mean? how do I get the skill you talking about?
English

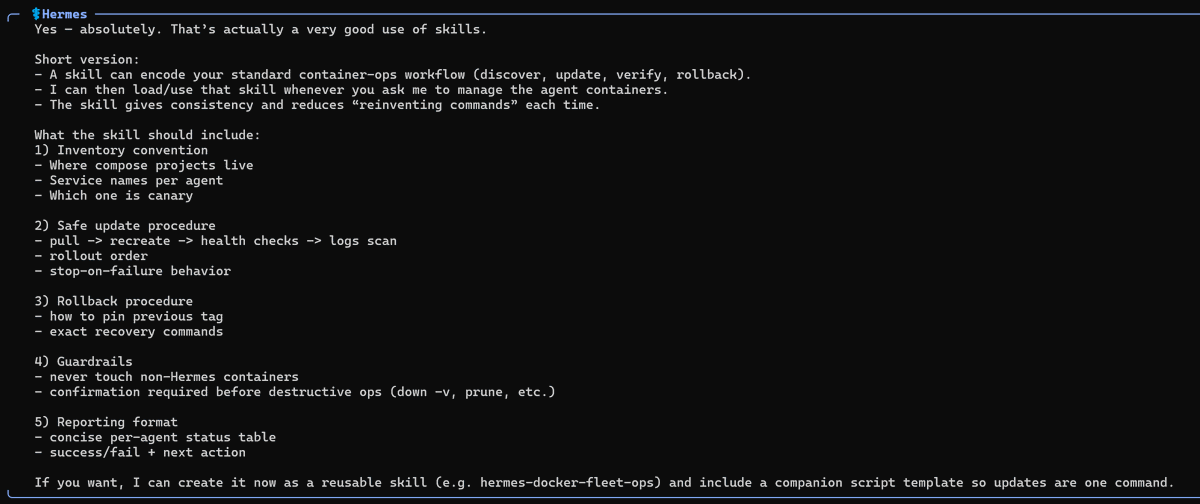
@ItsmeAjayKV Any video you recommend to make such installation? I want to understand this before buying a hight game pc with rtx inside? How I understand we need also more CPU core right? Like what’s the threshold CPU to help the vram?
English

@zkxwallet I see already a Zerion wallet with your Z symbol on wallet connect. This is confusing. Will you change logo someday? I remember was a placeholder right?
English

The goal of @zkxwallet is to deliver the smoothest possible trading experience across PulseChain, Railgun, and EVM-compatible blockchains.
This week’s upgrade is a major step forward, it will make the experience noticeably smoother than Rabby. The architecture has been redesigned and optimized specifically for PulseChain’s characteristics.
Additional features and functionality will roll out in future updates, but the immediate focus is clear: delivering a fast, reliable, and seamless trading experience comes first.
English
Flutterwave processes MoMo payments. Agent receives the payment confirmation via webhook, transforms it. and sends it to ZKP2P which generates a proof, allowing the transaction to be verified privately, potentially integrating with crypto wallets or exchanges supported by ZKP2P
English
Hello @zkp2p @unhappyben can you please assist with API details to use to connect via a relay agent to ZKP2P ? -I'm testing an agent for this and if it works will add the UI later.
English
English

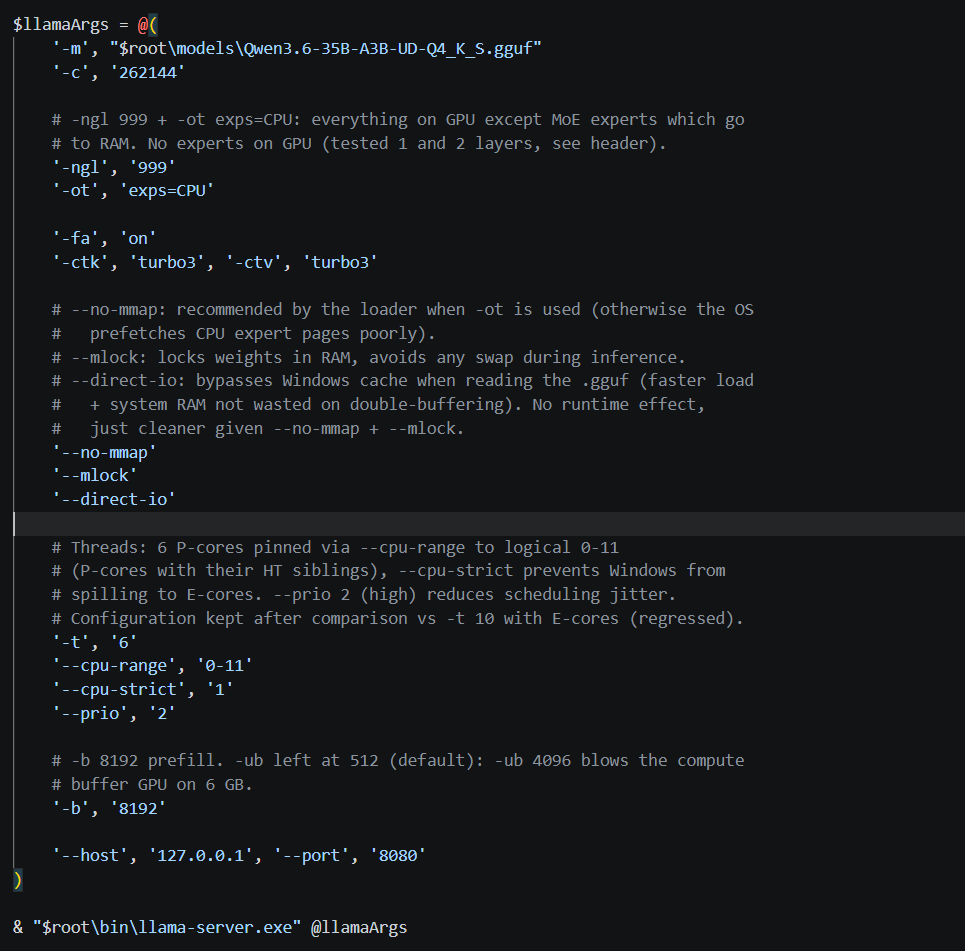
@above_spec This is my settings, I just added direct io for startup speed boost, -b at 8k for better prefill performances and some tweaks for intel to use only P cores and not E cores since it reduce decode speeds. Appreciate what you shared a lot
English
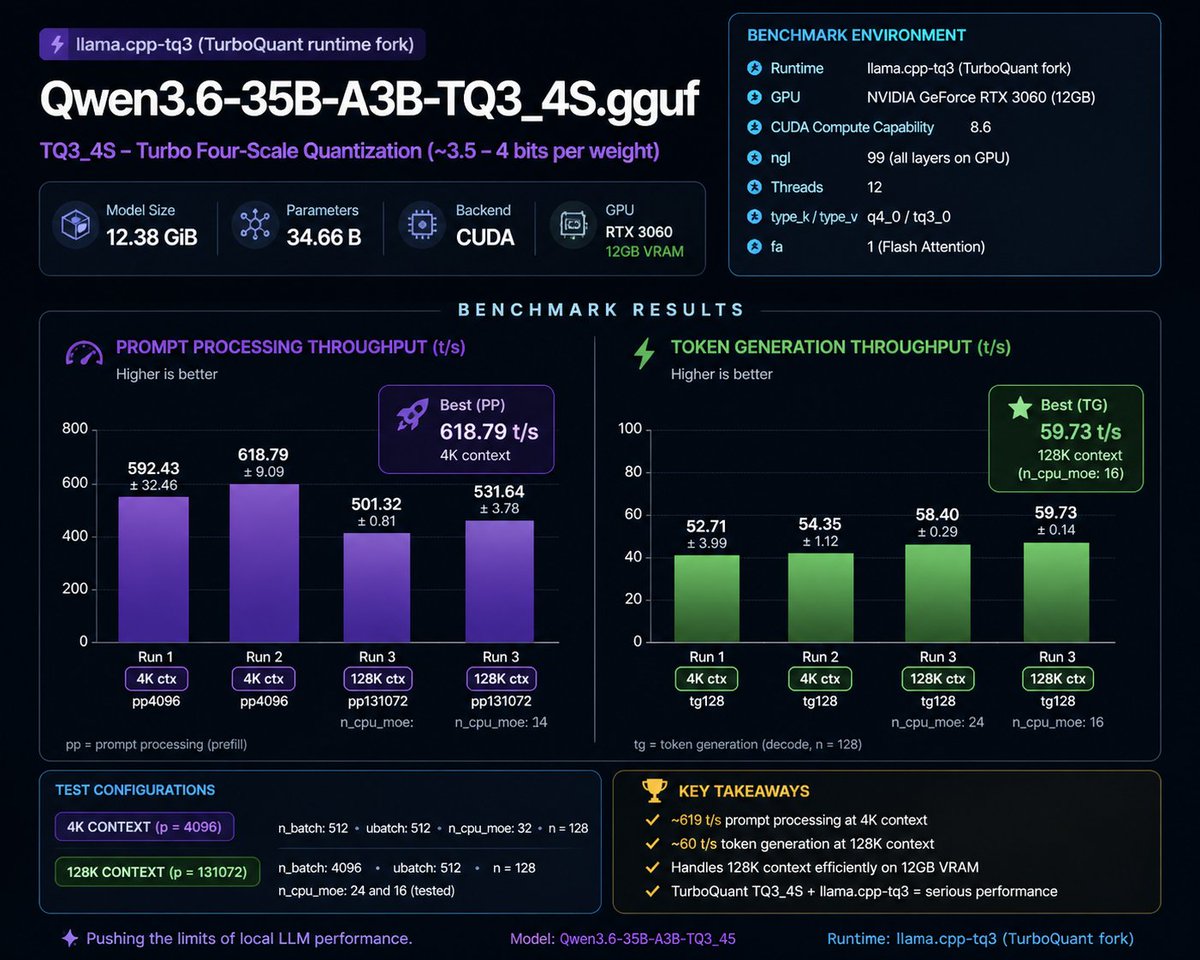
I can confirm this thing is real. I'm running opus 4.5 level intelligence on a 6gb vram GPU with 256k context at 20 tokens per second this is unreal. MoE architectures are the best thing ever made

AboveSpec@above_spec
"You need a 24 GB GPU for serious local LLMs in 2026." Everyone repeats this. It's not true anymore. Just ran a 35B-parameter model on an RTX 4060 Ti 8 GB: • 41 tok/s at 16k context • 24 tok/s at 200k context Recipe + benchmarks below 🧵
English

Hermes Agent now has multi-agent via the Kanban, new in v0.12.0.
Agents claim tasks from a board, work in parallel, and hand off when blocked. You watch progress and unblock from one easy view instead of juggling terminals.
We asked it to plan and make this video about itself:
English
So the new ask @grok is ask @venice_mind to still get to use for free ?
English