Sabitlenmiş Tweet

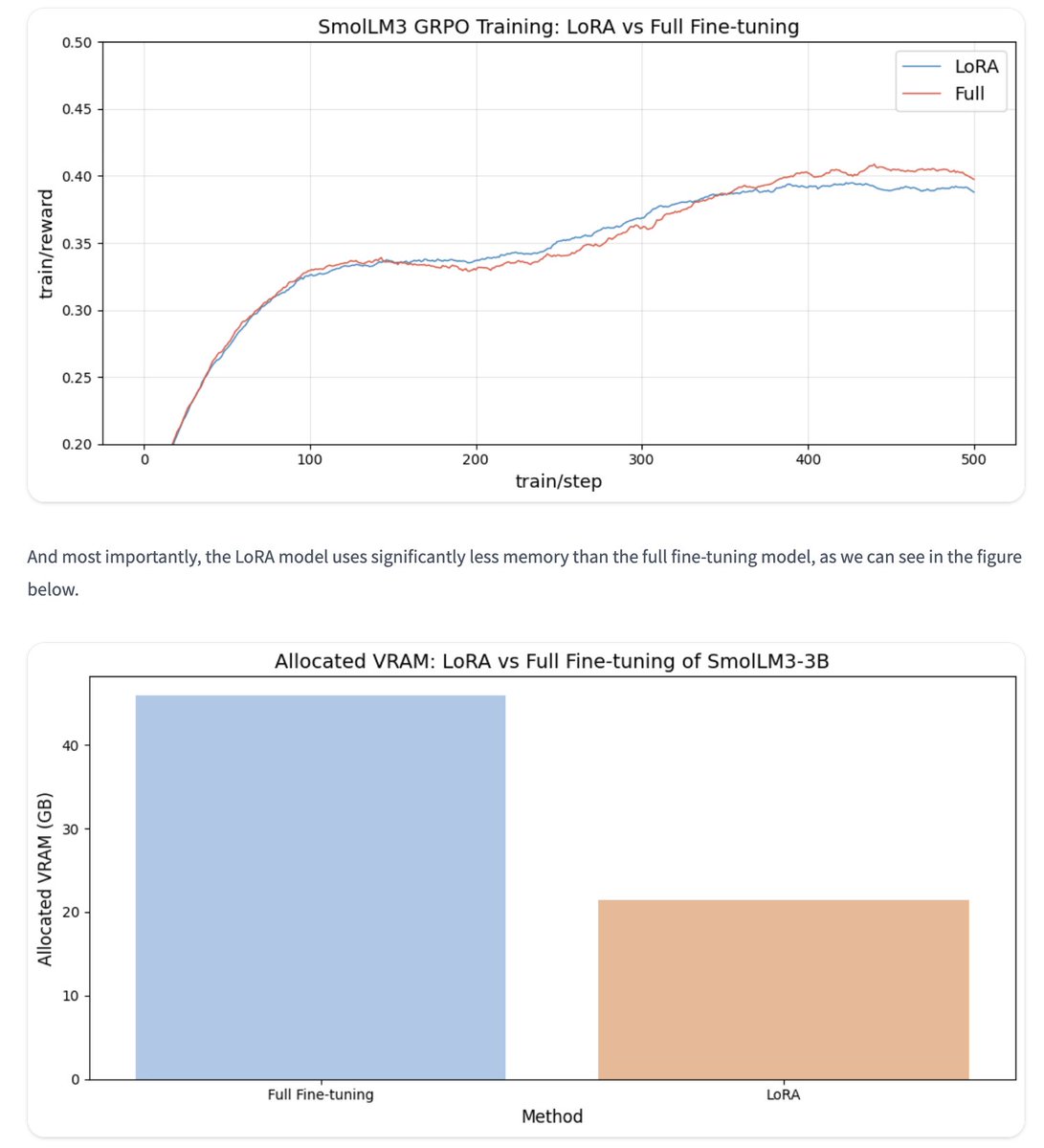
😋 Want strong LLM reasoning without breaking the bank? We explored just how cost-effectively RL can enhance reasoning using LoRA!
[1/9] Introducing Tina: A family of tiny reasoning models with strong performance at low cost, providing an accessible testbed for RL reasoning. 🧵

English