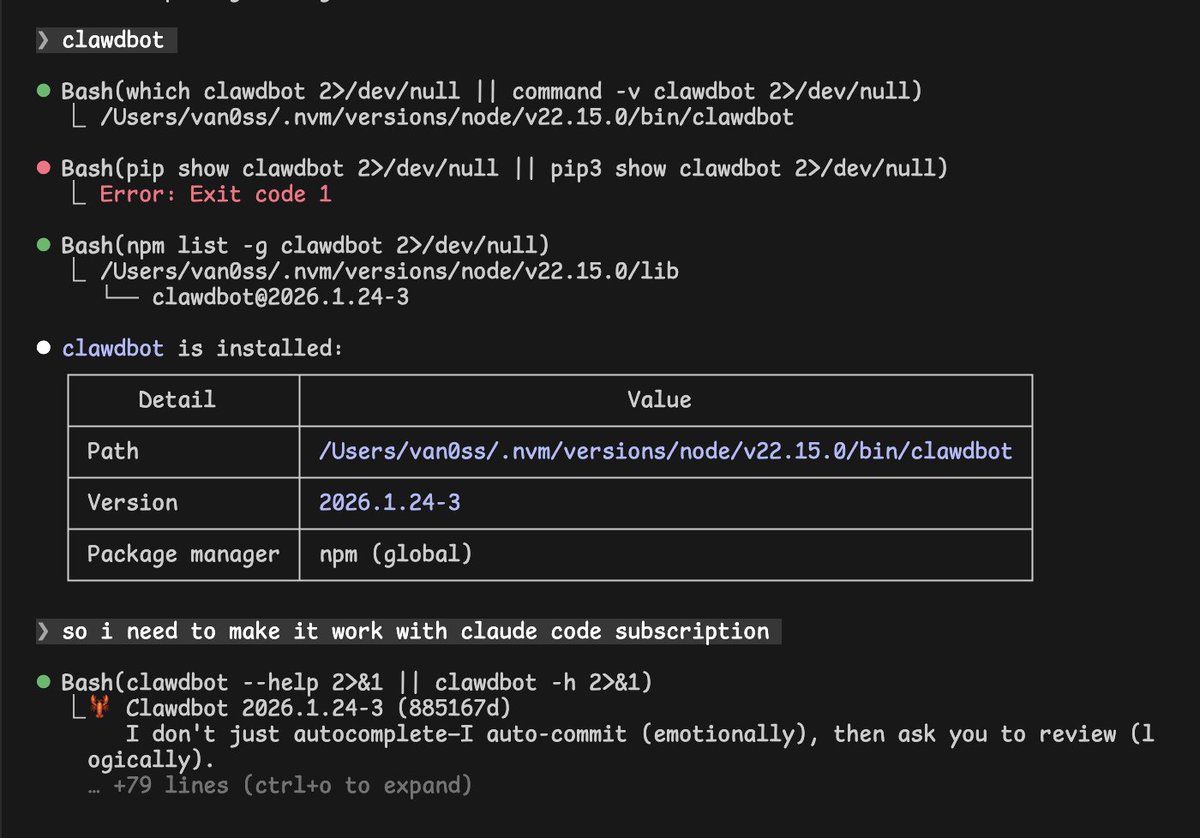
Van0SS
74 posts












Over the past year, AI agents have learned how to self-replicate. In our test environment, an agent hacks a remote computer and copies itself onto it. Each copy then hacks more computers, forming a chain.

For my eval-maxxing nerds out there, good friends of mine are running a series called "strange evals", you can benchmaxx now on anything. If in SF swing by! luma.com/lvqbs1mo



Introducing Muse Spark, the first in the Muse family of models developed by Meta Superintelligence Labs. Muse Spark is a natively multimodal reasoning model with support for tool-use, visual chain of thought, and multi-agent orchestration. Muse Spark is available today at meta.ai and the Meta AI app. We’re also making it available in private preview via API to select partners, and we hope to open-source future versions of the model. Learn more: go.meta.me/43ea00




SkyRL now implements the Tinker API. Now, training scripts written for Tinker can run on your own GPUs with zero code changes using SkyRL's FSDP2, Megatron, and vLLM backends. Blog: novasky-ai.notion.site/skyrl-tinker 🧵

Frontier labs spend millions purchasing RL environments for training terminal agents. But we decided to open source it. Introducing SETA: Scaling Environments for Terminal Agents, the largest open source training RL environments for terminal agents. We released: - 400 termianl agent training environments, more to come - SOTA agent harness on terminal-bench with CAMEL terminal toolkit - The RL training pipeline and trained SETA-RL-Qwen3-8B model weights