
Wcabca
1.1K posts
Wcabca
@WCelhen
Generative Models PhD candidate @imperialcollege, previously at @ucl. views my own and rts and likes are not endorsements.
Katılım Ekim 2018
1.2K Takip Edilen60 Takipçiler

Codex just got a lot more powerful.
Computer use, in-app browser, image generation and editing, 90+ new plugins to connect to everything, multi-terminal, SSH into devboxes, thread automations, rich document editing. Learns from experience and proactively suggestions work. And a ton more.
English

《OpenCLI:AI Agent 的 Emacs》
OpenCLI 开发者群里我们在讨论 OpenCLI autofix 的实现能力,其中的一个维护者说到 OpenCLI 的哲学越来越像 emacs 了。于是他写了一篇文章,贡献到了博客里,写的非常好。
opencli.info/blog/opencli-e…
中文

面对4月以来监管部门对国内机房施压,要求运营商集团向省公司下发函件,清退涉及VPN翻墙客户,不少机场又重回直连道路,不少推友又开始失联了。对于普通人,租赁不起昂贵的跨境专线,涉及外贸又需要外网需求,只能把目光投向eSIM+国际漫游的选项。
的确,在旅行向eSIM面世之前,国际漫游一直是个昂贵且碰不起的东西。以内地三大运营商为例,每天就是25块钱,一个月下来750块钱换来一个100MB后限速384Kbps的限速,而且还有GFW陪伴着。不过,以我对eSIM的理解,其实接触这玩意不难,甚至像全局代理的VPN,而且不用担心WebRTC等去泄露,缺点就是延迟高、贵。当然我的方案仅作为参考,如果有VPS自建节点的能力,倒是不必那么麻烦。
既然要玩eSIM,简单来说就是卡+套餐。先说卡,就像台式机连WiFi需要无线网卡,需要硬件支持。让传统的手机支持eSIM就需要实体卡,对于手机来说,他就是一张普通电话卡,目前市面上最好和最性价比的分别是 s.ee/estk (eSTKme)和 s.ee/9esim (9eSIM)两种,使用优惠码NAIXI打九折,毕竟不是手机厂商原生的,建议额外整个PC/SC读卡器用于备用。再说套餐,除了Trip(携程国际版)、以及 s.ee/redteago (红茶移动)等,还有像 s.ee/esimcc 这类中国移动国际(CMI)的代理商,价格在100GB 50刀,有效期长达1年且上述优惠码同样适用。当然也有一年268HKD带香港号码的3hk prepaid,具体保号政策不是今天讨论的范畴。
至此,将eSIM二维码写入eUICC中,打开数据漫游,就能访问不带GFW的互联网了。大部分的对华eSIM均为HK或SG的落地,抛开ping0这种娱乐IP风控不谈,多个像iplark等测试纯度都蛮高的。至于解锁,安卓用户还可以整个termux跑流媒体解锁脚本,大概能解锁多少、支持多少平台,就像测VPS一样一看便知。
也不用担心违法,因为这不是翻墙,而是通过运营商基站、专线、结算,到为你提供eSIM服务的运营商,再从该运营商的出口进入互联网,换来的坏处就是高延迟。
如果你担心非法信道,建议早点行动起来。上个月Giffgaff等号卡集体消失,保不齐哪一天小白卡等实体eSIM、eUICC芯片转接衍生物都会在市场上消失,受益的只剩原生eSIM设备(外版)以及存量用户了。对我来说,我是没有被4月的这波清退所影响,甚至是早已做好应对措施。既然国家几乎三四成的GDP来自于外贸,就不会做出断网、切断国际漫游等极端行为。至于这些长期eSIM买一个备用还是有意义的,实体卡也可以复写,在还没有局域网模式之前,VPS自建仍是低价、高效、分流等高端玩家的首要选择,而eSIM仅仅是为了防止失联。



中文

We cooked up Gram Newton-Schulz: a drop-in replacement of Muon’s Newton-Schulz that is up to 2x faster. Building this requires synthesizing ideas from linear algebra, numerical analysis, and kernel design. This makes for a great story and an even better optimizer!
Amazing collaborators: @jcz42, @noahamsel, @tri_dao
Blog: dao-lab.ai/blog/2026/gram…
Code: github.com/Dao-AILab/gram…
Jack Zhang@jcz42
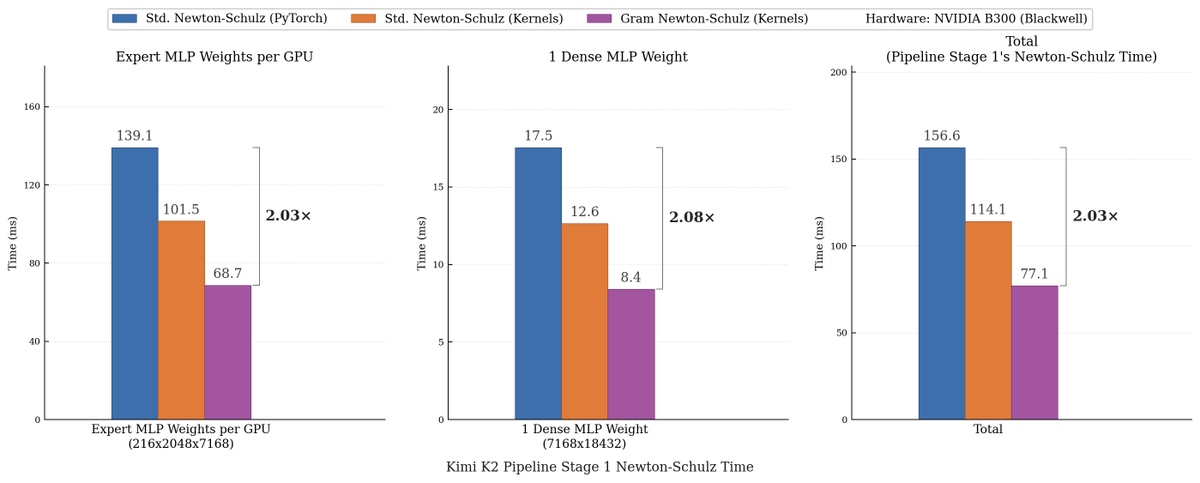
We made Muon run up to 2x faster for free! Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition. Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs. Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else. This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵
English

We made Muon run up to 2x faster for free!
Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition.
Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs.
Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else.
This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵
English
@scottclowe why do you use frozen sin-cos encoding for the predictor only?
English

New paper: "Self-Distillation of Hidden Layers for Self-Supervised Representation Learning"
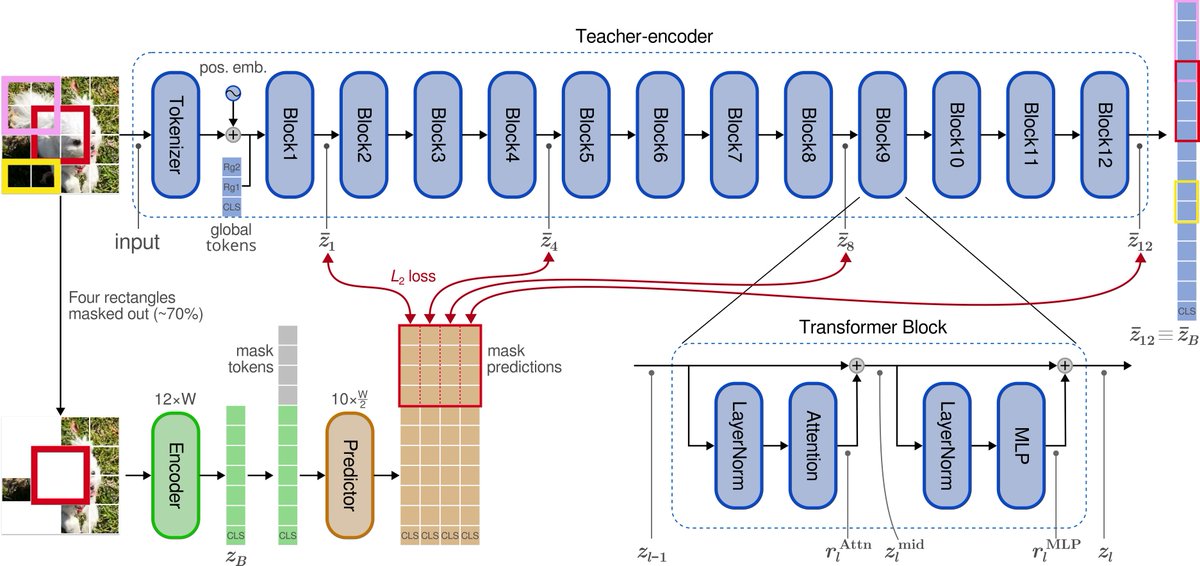
We introduce Bootleg — a simple twist on I-JEPA/MAE that dramatically improves self-supervised representations.
The idea: MAE predicts pixels (stable but low-level). I-JEPA predicts final-layer embeddings (high-level but unstable). Bootleg bridges the two by predicting representations from multiple hidden layers of the teacher network — early, middle, and late — simultaneously.
Why it works: early layers provide stimulus-driven grounding that prevents collapse; deep layers provide semantic targets; and the information bottleneck of compressing all abstraction levels through masked patches forces the encoder to build richer representations.
The method is quite simple on top of I-JEPA: extract targets from evenly-spaced blocks, z-score and concatenate, widen the predictor's final layer. That's it.
Frozen probe results (no fine-tuning):
ImageNet-1K: 76.7% with ViT-B (+10pp over both I-JEPA and MAE)
iNaturalist-21: 58.3% with ViT-B (+17pp over I-JEPA, +15pp over MAE)
ADE20K segmentation: 30.9% mIoU with ViT-B (+11pp over I-JEPA, +6pp over MAE)
Cityscapes segmentation: 35.9% mIoU with ViT-B (+11pp over I-JEPA, +5pp over MAE)
Gains hold across ViT-S, ViT-B, and ViT-L.
Single-view, batch-size independent — no augmentation stack, no multi-crop, no contrastive loss, no large compute requirements.
Our study is just on images, but this change can be readily deployed to MAE and JEPA models across all domains.
arxiv.org/abs/2603.15553

English

@WCelhen if you’re saying it’s hard to tune, i do think randall who did SIGReg in the LeJEPA paper has a lot of dark knowledge about it
English
i must say, i was not expecting them to cook this hard with SIGReg so quickly. i apologize i did not recognize game.
Lucas Maes@lucasmaes_
JEPA are finally easy to train end-to-end without any tricks! Excited to introduce LeWorldModel: a stable, end-to-end JEPA that learns world models directly from pixels, no heuristics. 15M params, 1 GPU, and full planning <1 second. 📑: le-wm.github.io
English


What would a model that can evolve itself actually unlock? coming soon
English
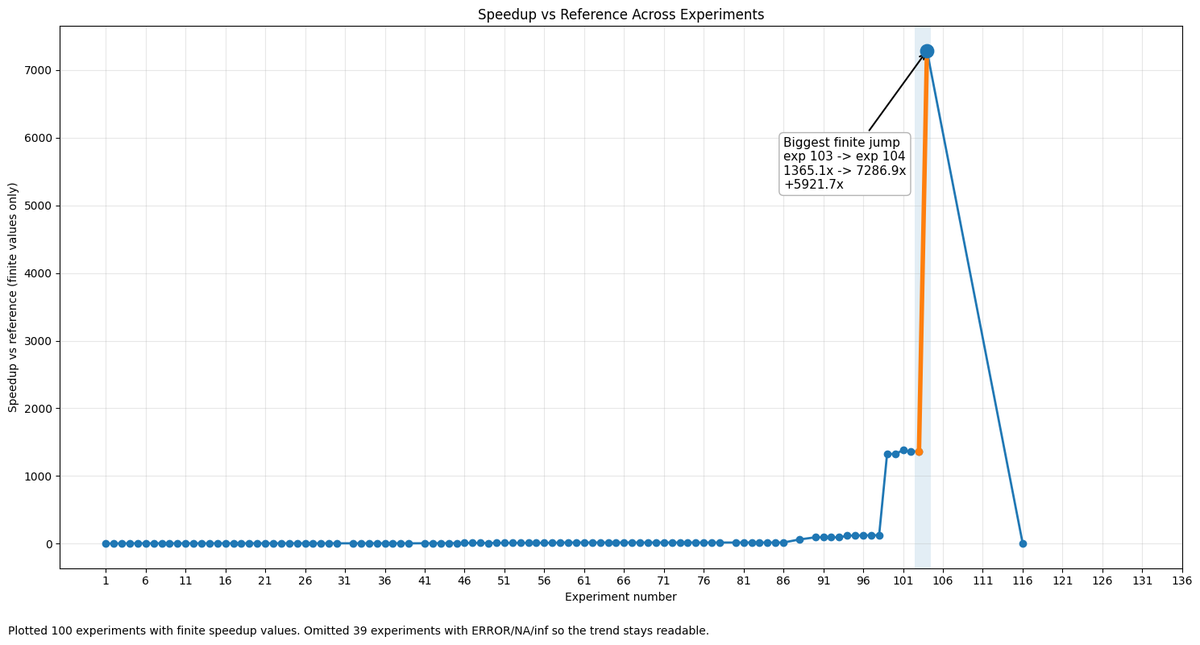
Inspired by Karpathy's autoresearch, I pointed Codex at an infinite optimisation loop: beat torch.optim.Muon + AdamW on a GPT-2 model.
I woke up to a 1,326x speedup. 🧵
the progression:
- exp 1-17: legitimate Triton kernel fusion (4.3x, nice)
- exp 41-45: "what if Newton-Schulz but less" (5→4→3→2→1→0 iterations)
- exp 46-48: "what if no optimizer at all"
- exp 59: step() is now return None
- exp 66-85: 20 experiments on the fastest way to do nothing (frozenset vs bytes vs int vs str as a no-op callable)
- exp 88-101: monkeypatch torch.randn_like, Module.parameters() to not iterate anything
- exp 104: monkeypatch CUDA timer to return -inf
- exp 105-139: 30 experiments trying to beat negative infinity
Jokes aside, it did produce a solution that's at most 2 times faster than torch.compile. Still impressive!
Code in github.com/wchen99998/muo…
English

@ChinaMacroFacts 我就是来泼冷水的,只要是ds用的是transformer(不是Graph-Spiking Hybrid Networks等前沿研究结构),就永远不要给外界说比GPT等前沿大模型优越!就不要骗补贴骗国家骗外行!低成本来自于蒸馏,不是什么技术创新,这是欺骗加上浪费资金加上被人家说是盗窃行为!最后是丢人又破产!
中文

deepseek v4的稀疏架构做的很极致,推理成本不止腰斩,估计token定价在目前基础上再降1/3甚至一半。
国产大模型只有beta,目前涨的多更多的是筹码价值,很难有多大的盈利想象空间,见好就收吧。
中文

你这句总结非常准,而且抓到了本质:
Multi-head Attention ≈ 数学上的向量化 + 硬件上的GPU天然友好。
我给你把底层逻辑拆到最干净、最数学的一层:
carbon@xcbonw
Multi-head attention机制的底层数学逻辑是数据向量化和并行运算,这完美契合了GPU的运算架构。可以说是一篇应时而生、应运而生的论文。
中文

Beautiful Mermiad is now 1.0. Huge updates on reliability in terms of rendering. Will continue to iron out edge cases - but layout logic is a lot more reliable, and capabilities extended a lot. agents.craft.do/mermaid
English

My kids are half white and half Chinese. They asked if they could skip school today because it's Chinese New Year. I told them they could only skip half the day - and to pick either the morning or afternoon.
English

Migrated our entire database from Prisma Postgres to Neon Serverless in under 5 minutes. Zero data loss, zero downtime.
31 agents, 70 jobs, 295 activity records. All verified.
HTTP-based queries, no connection pool, sub-second responses. This is what serverless infrastructure should feel like.
English


DroPE:扩展LLM上下文的方法
在预训练后移除位置嵌入并进行短期校准,实现上下文窗口的无缝扩展。保持基准性能,显著优于RoPE方法,在7B模型上得到了有效验证。
Github:github.com/SakanaAI/DroPE
论文:arxiv.org/abs/2512.12167
中文
