Sabitlenmiş Tweet

New paper: "Self-Distillation of Hidden Layers for Self-Supervised Representation Learning"
We introduce Bootleg — a simple twist on I-JEPA/MAE that dramatically improves self-supervised representations.
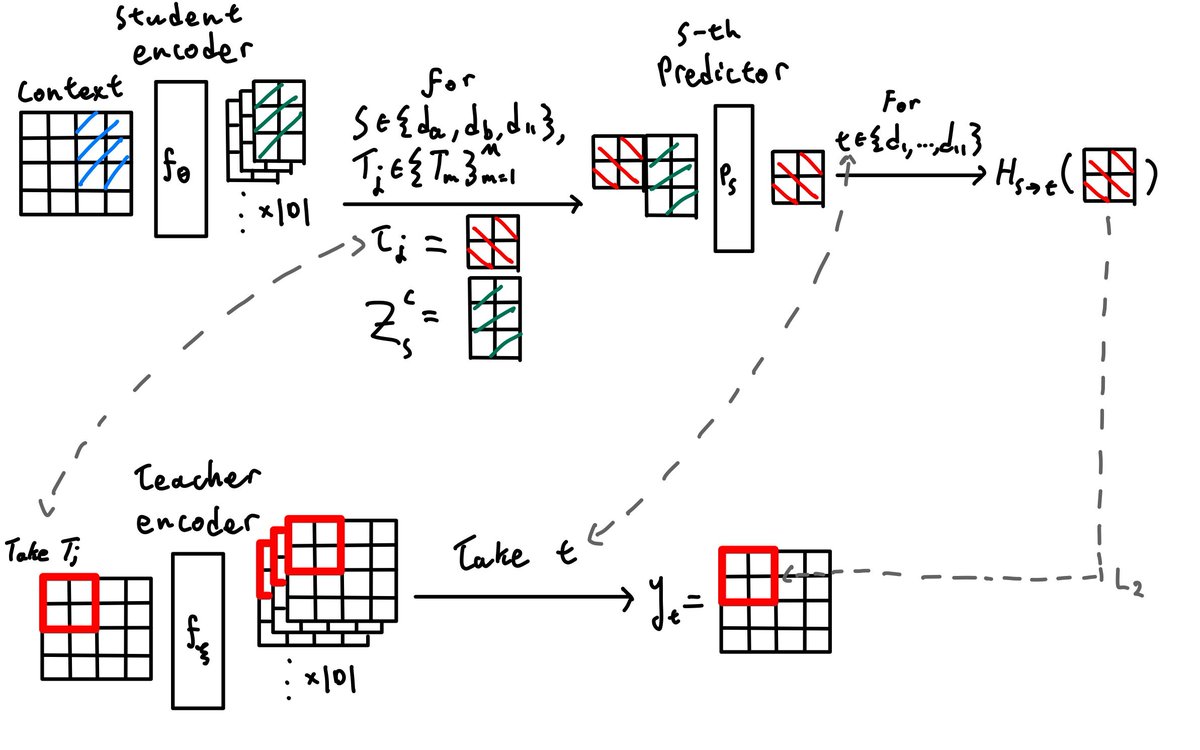
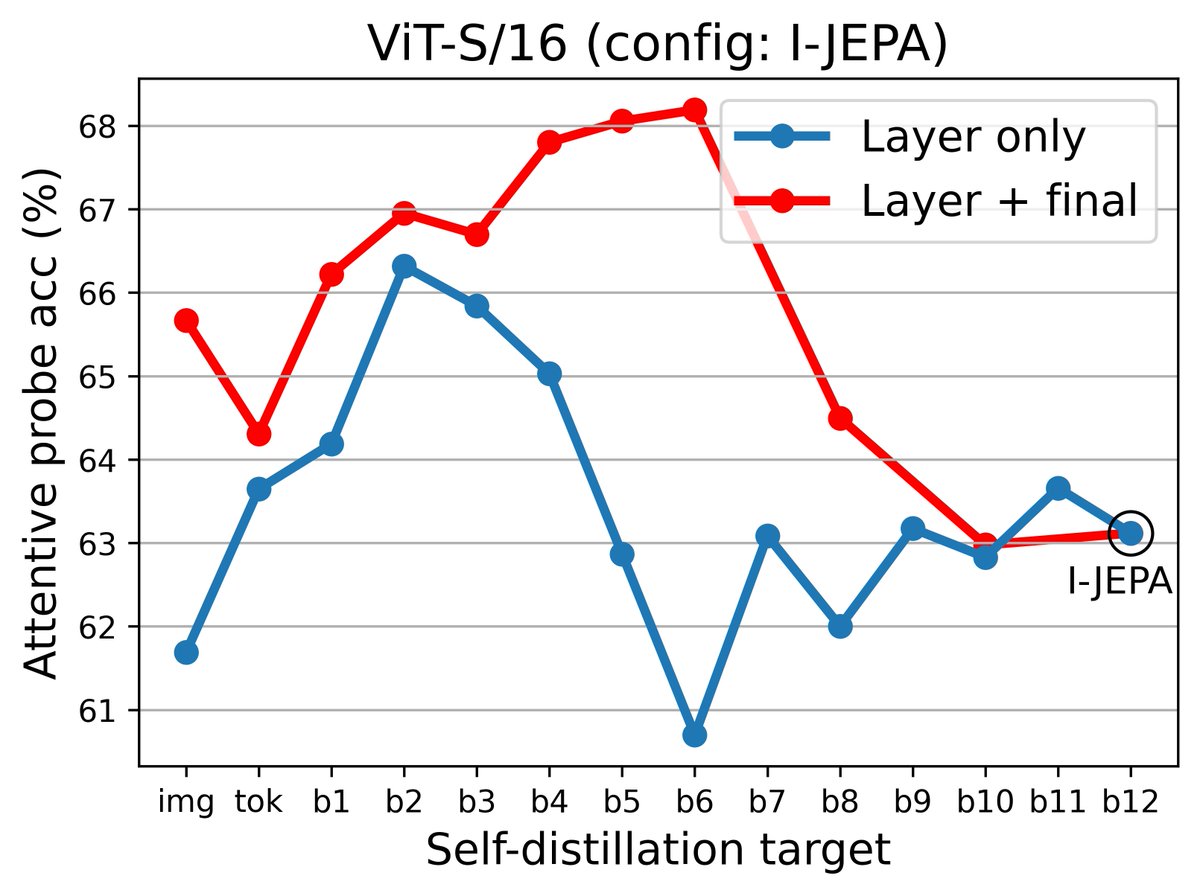
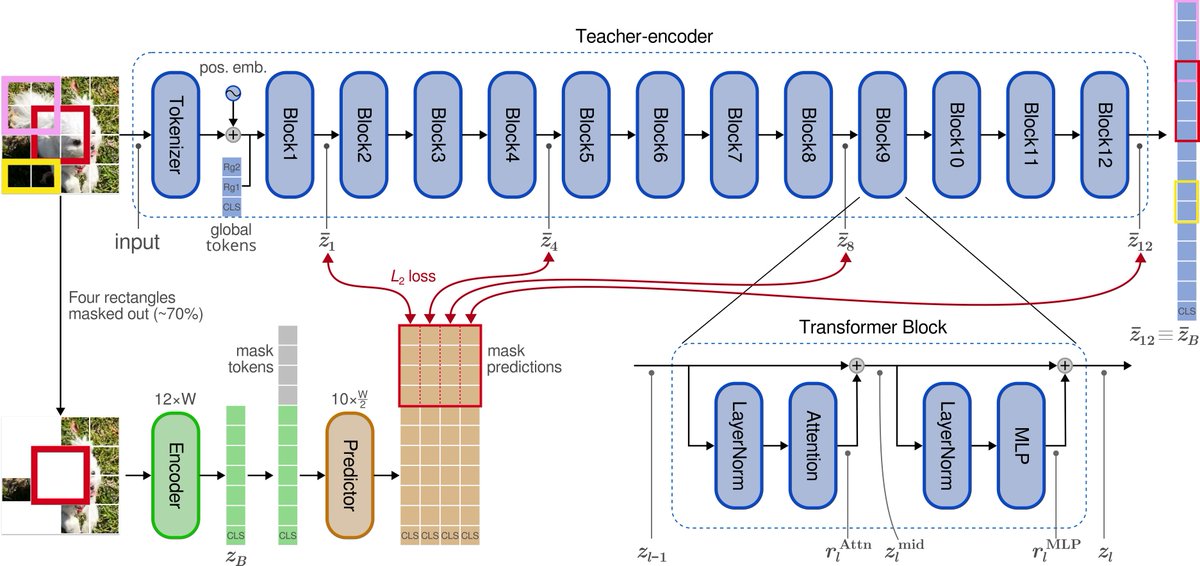
The idea: MAE predicts pixels (stable but low-level). I-JEPA predicts final-layer embeddings (high-level but unstable). Bootleg bridges the two by predicting representations from multiple hidden layers of the teacher network — early, middle, and late — simultaneously.
Why it works: early layers provide stimulus-driven grounding that prevents collapse; deep layers provide semantic targets; and the information bottleneck of compressing all abstraction levels through masked patches forces the encoder to build richer representations.
The method is quite simple on top of I-JEPA: extract targets from evenly-spaced blocks, z-score and concatenate, widen the predictor's final layer. That's it.
Frozen probe results (no fine-tuning):
ImageNet-1K: 76.7% with ViT-B (+10pp over both I-JEPA and MAE)
iNaturalist-21: 58.3% with ViT-B (+17pp over I-JEPA, +15pp over MAE)
ADE20K segmentation: 30.9% mIoU with ViT-B (+11pp over I-JEPA, +6pp over MAE)
Cityscapes segmentation: 35.9% mIoU with ViT-B (+11pp over I-JEPA, +5pp over MAE)
Gains hold across ViT-S, ViT-B, and ViT-L.
Single-view, batch-size independent — no augmentation stack, no multi-crop, no contrastive loss, no large compute requirements.
Our study is just on images, but this change can be readily deployed to MAE and JEPA models across all domains.
arxiv.org/abs/2603.15553

English