@RusenPress 土耳其杂种为什么这么热衷于给自己的杂种血统找爹?你们这些杂种通过碰瓷突厥把他们当做你们亲爹,但DNA序列证明毫无关系。你们可能继续花费几百年都搞不明白自己祖先来自哪里,甚至一整套民族国家叙事都是建立在殖民时代后的伪造和谎言之上。
中文
Total
53 posts









Çin Rusya'yı geçti mi? 4000/6000 saat mi? 🤣 Sizler, Çin'in dünyaya açıkladığı rakamlara İnanabilirsiniz, bu sizin meseleniz, bizi ilgilendirmez. Ama öylesine bir soru soracağım. Bugün Çin, JF-17 diye bir uçak satıyor. Bu uçak, Rusya'nın Klimov RD-93 motoruyla üretildi. Sonra Çin bunu izinsiz sattı, Rusya izinsiz satamazsın deyip rest çekti, Çin'de üşenmedi, onu da kopyaladı ve WS-13 adı verdi. Her iki motorun da detaylarına girmeyeceğim, çünkü sen Çin'in "verilerine" inanıyorsun. Çin, bu uçağı 4 tane ülkeye sattı. Pakistan, Myanmar, Nijerya ve Azerbaycan. Bu 4 ülkenin hepsi, uçağı Klimov motor paketiyle sipariş etti ve hepsi Klimov versioyonunu kullanıyorlar. Şimdi sana basit sorular soracağım: 1) Neden bu ülkelerin hepsi Çin değil, Rus motoru alıyor? 2) Pakistan salak mı gidip kendi müttefiki Çin varken, Hindistan'ın müttefiki Rusya'ya bağımlı oluyor? 3) Çin'in kendi motoru o kadar iyiyse neden Rus motorunu kenara koyup, ithalatçı ülkelere kendi motorunu dayatmıyor?

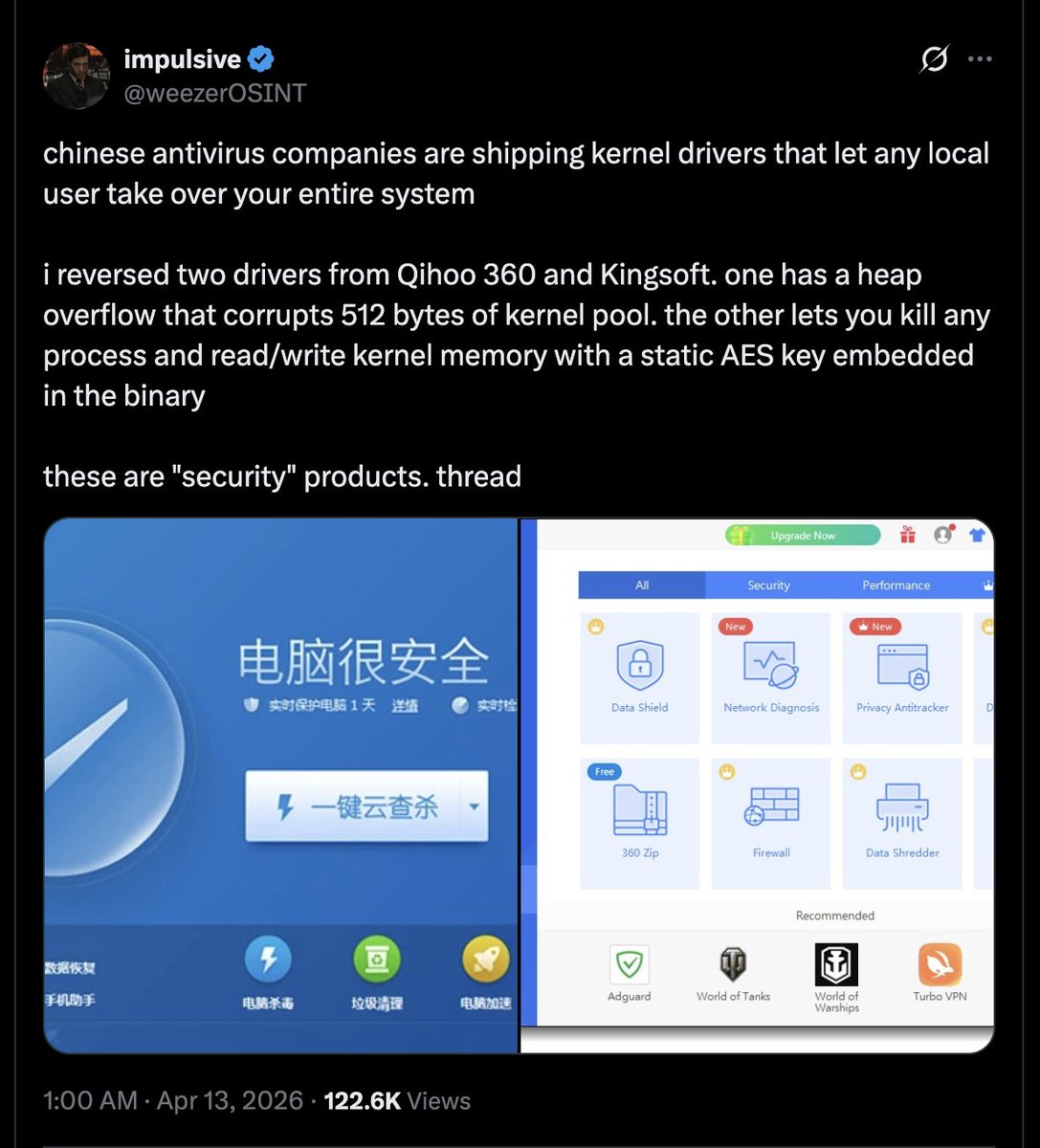
NEW: Chinese cybersecurity firm 360 Digital unveils new AI “Vulnerability Discovery Agent” that seeks to rival Claude Mythos.

DeepSeek Update Deepseek-v3.2-exp was added to the arena about an hour ago and appears to route to V4 DeepSeek V3.2 is now routing normally to v3.2 again



How to evaluate DeepSeek’s new "Expert Mode"? 🧠 Zhihu contributor 一只Zenon 👇: Quick take: This doesn’t appear to be the full DeepSeek Next model—more like a new checkpoint built on Lite, with Expert Mode likely tweaking decoding params rather than using a separate model weight. Test impressions so far: • Clean, lightweight tone ✨ No cringey generic chatbot phrases like "your xxx is very xxx" or overly empathetic filler lines. • Far less Gemini+ distillation vibe; more natural, less verbose logic. • Strong creative writing with proper structure & flow. Two standout breakthroughs: 1️⃣ Precise length control & deep prompt • It generated a 10,000-word report in seconds per my prompt. • Previous limits: DeepSeek ~2k words, Gemini 3.1 Pro ~4k, Qwen 3.6 Plus ~5k. • The result is clearer & more usable than Qwen 3.6 Plus Deep Research’s 10+ minute output, even when told to focus on software over hardware. 2️⃣Genuine logical reflection ability • Earlier "stubborn" models (GPT-5, Kimi K2+) just defended hallucinations or rambled. • DeepSeek Expert Mode actually reflects on the prompt’s logic itself—a skill previously exclusive to Claude Opus 4.6+. It solves classic real-world reasoning tests (e.g., "I live 50m from a car wash—walk or drive?") that stumped most Chinese models, with clean, grounded reasoning. 💡This kind of real-scenario inference requires advanced post-training & RL, a huge gap for most domestic LLMs. Whatever technique (eNgram, mHC, NSA or custom RL) enabled this jump is a big win. 🔗 Full Response (CN): zhihu.com/question/20250… #DeepSeek #Qwen #AI #Gemini #LLM #GenAI #AIGC #Tech